ホーム
>>
ヘッドライン
>>
stable video diffusion webui (ローカルPC 環境構築)
ホーム
>>
ヘッドライン
>>
stable video diffusion webui (ローカルPC 環境構築)
ヘッドライン
| メイン | 簡易ヘッドライン |
stable video diffusion webui (ローカルPC 環境構築) (2023-12-15 18:52:02)
はじめに
Stable Video Diffusion(SVD) は、Stability AIが開発したImage2Videoモデルの一種で、 画像から動画を生成できるAIモデル です。
2023年11月22日に発表されました。SVDは、研究目的のみで利用可能で、画像から短いクリップを生成する2つの 最新AIモデル(SVDとSVD-XT) が含まれています。
単一画像からのマルチビュー合成など、さまざまなビデオアプリケーションに適応できるとされています。
Stable Diffusionは、テキストや画像プロンプトから写真のようにリアルな独自の画像を生成する生成型人工知能(生成系AI)モデルです。
画像以外にも、 モデルを使用して動画やアニメーションを作成することもできます 。
参考サイト
(Comfy UIを使わない) stable video diffusion webuiのローカル環境構築
準備
モデルのダウンロード
svd: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/tree/main 9.5GB(14フレームで学習/14フレームを生成できる?)
svd-xt: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/tree/main 9.5GB(25フレームで学習/25フレームを生成できる?)
※とりあえず、 svd-xt のみ ダウンロードするといいかなと思います。
ファイルのインストール
Cドライブ直下に「stable-video-diffusion」フォルダ作成

「stable-video-diffusion」フォルダ内に入り、コマンドプロンプトを起動(タスクバーにcmdと打ってエンター)
Generative-modelsのGithubページ: https://github.com/Stability-AI/generative-models
Generative-modelsをクローン
git clone https://github.com/Stability-AI/generative-models.git

C:\stable-video-diffusion\generative-models\scripts\demo フォルダ内、「 streamlit_helpers.py 」ファイルの編集
※61行目を False から True へ変更

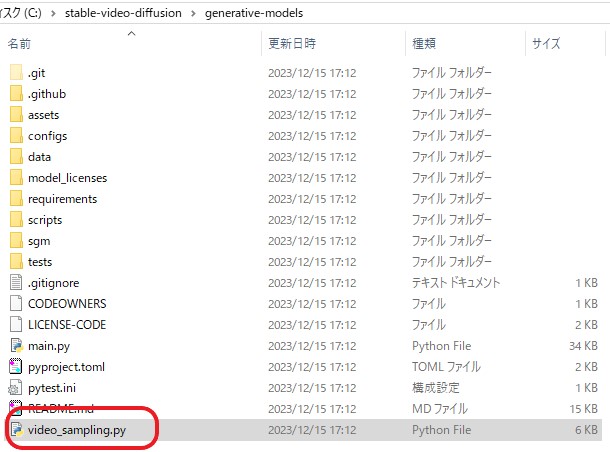
C:\stable-video-diffusion\generative-models\scripts\demo フォルダ内、「 video_sampling.py 」ファイルの移動
「 video_sampling.py 」ファイルを、C:\stable-video-diffusion\generative-modelsへ移動
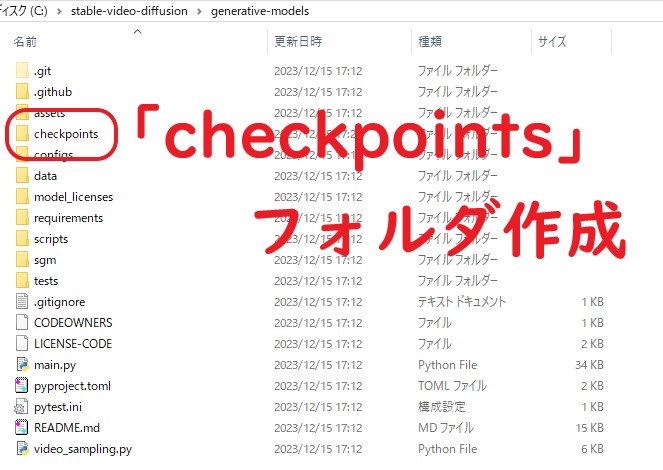
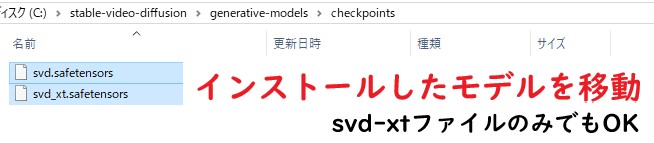
C:\stable-video-diffusion\generative-modelsに、「 checkpoints 」フォルダ作成
C:\stable-video-diffusion\generative-models\checkpointsに、インストールしたモデルを移動する。
( svd-xt
、または、 svd ファイルのみでも大丈夫です。)
C:\stable-video-diffusion\generative-models\requirementsフォルダ内、「 pt2.txt 」ファイルの編集
34行目 「triton==2.0.0」を削除

必要なファイルのインストール(コマンドプロンプト)
C:\stable-video-diffusion\generative-modelsへ、移動する。
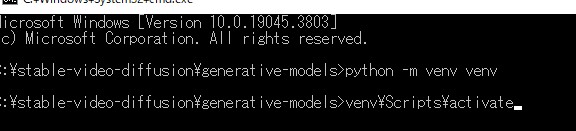
タスクバーにて、cmdと打ち込み、エンターでコマンドプロンプトを立ち上げる。
#仮想環境venv
python -m venv venv

#仮想環境を活性化
venv\Scripts\activate
#pipアップグレード
python -m pip install --upgrade pip
Windowsに対応した 「triton==2.0.0」 をインストール
pip install https://huggingface.co/r4ziel/xformers_pre_built/resolve/main/triton-2.0.0-cp310-cp310-win_amd64.whl

#PyTorchインストール
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118

#requirementsフォルダ内のパッケージのインストール
pip install -r requirements/pt2.txt

#残りのパッケージのインストール
pip install .

起動
起動コマンド
streamlit run video_sampling.py

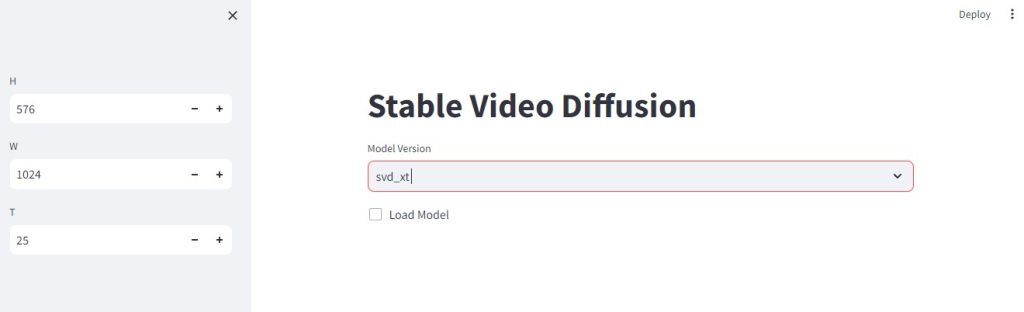
Web画面
※Model Version で 「 svd_xt 」を選択
2回目以降
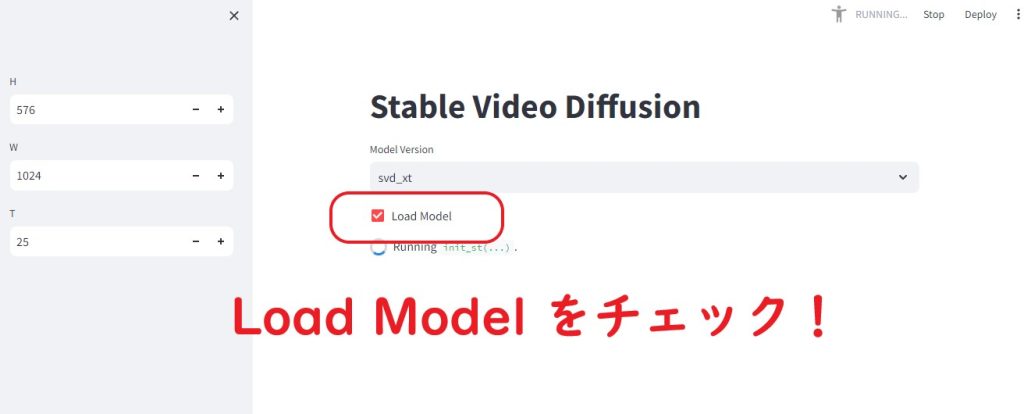
1. C:\stable-video-diffusion\generative-models でコマンドプロンプト(cmd)
2. venv\Scripts\activate
3. streamlit run video_sampling.py
「 Load Model 」にチェック!
Stable diffusion で画像作成
※W:1024 H:512 (画像サイズは、 64の倍数 )
※プロンプト:a dog, solo, runnig, realistic, best quality,

※使用する画像

stable video diffusionに、画像をドラッグ
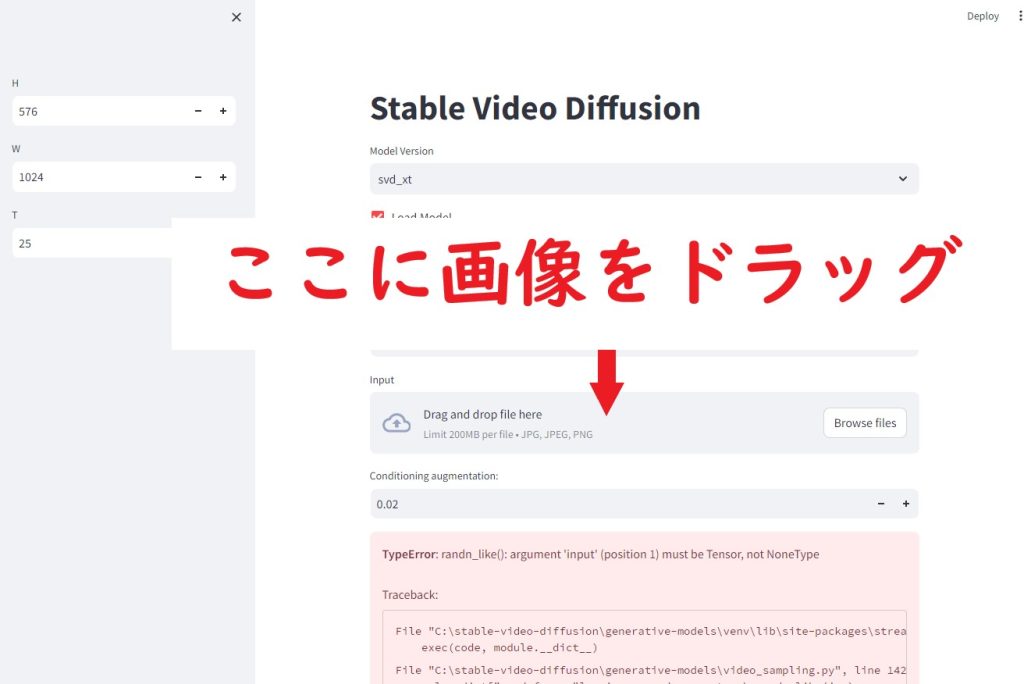
画像をドラッグ後
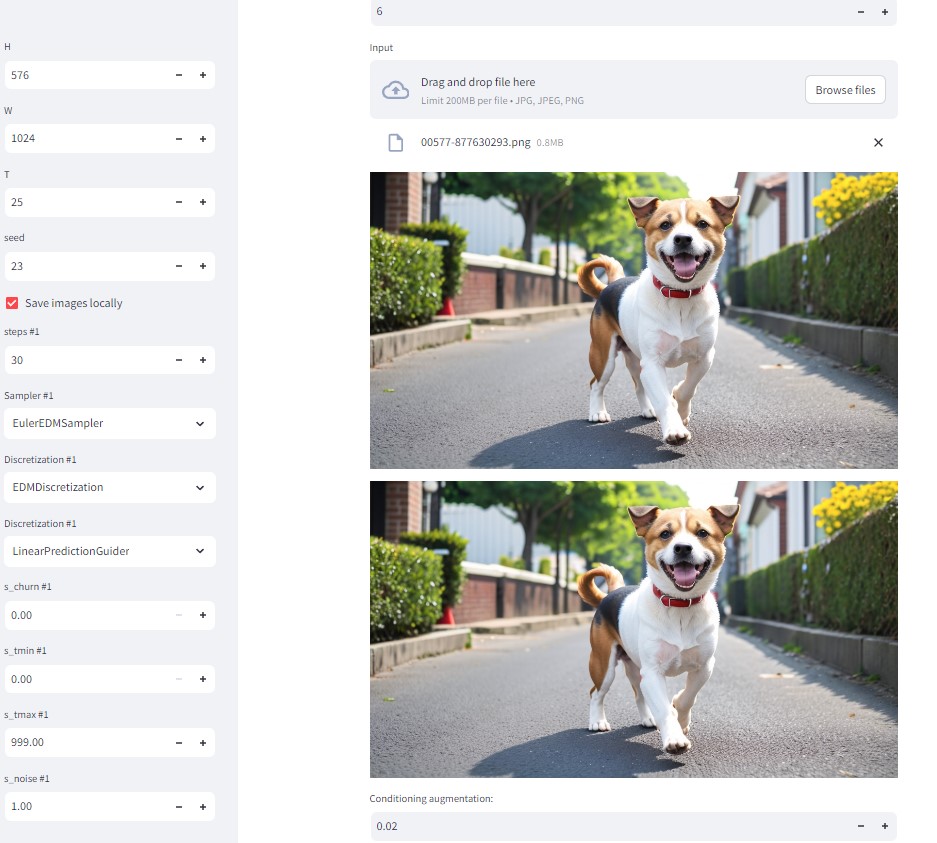
デフォルトの設定
・サイズ:512×1024
・25フレーム
・fps:6フレーム/秒 (※3?30フレーム)
※約4秒の動画
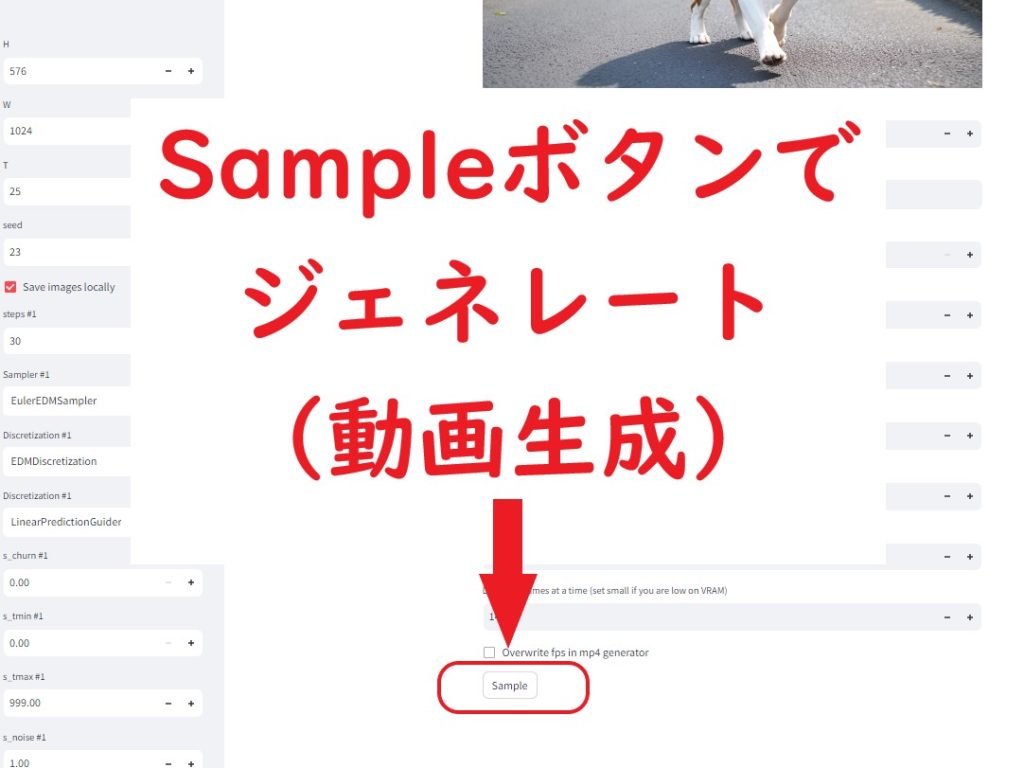
画面下の「 Sample 」ボタンをクリック! ( 動画生成が始まります )
C:\stable-video-diffusion\generative-models\outputs\demo\vid\svd_xt\samples 以下に動画が生成されています。
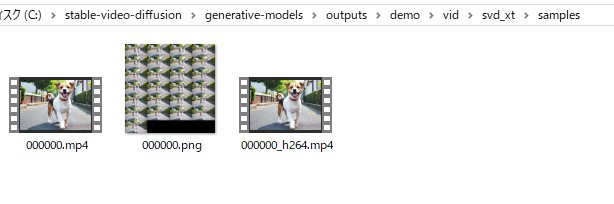
生成された動画
考察
Stable Diffusionでは、背景や衣服などの一貫性に欠けるところがあったが、stable video diffusionでは、見事に一貫性が保たれている。
今回の犬のように、まばたきなども自動で生成される。
まだまだサンプル(開発途中)のため、これからが楽しみである。
- Video Motion Bucket
デフォルトは127。この値を小さくすると動きが遅くなる - Video Augmentation Level
デフォルトは0。大きくするとモーション(運動量?)が増える
-
fps: 生成されたビデオの 1 秒あたりのフレーム数。 -
motion_bucket_id: 生成されたビデオに使用するモーション バケット ID。これを使用して、生成されたビデオの動きを制御できます。モーション バケット ID を増やすと、生成されるビデオのモーションが増加します。 -
noise_aug_strength: コンディショニング画像に追加されるノイズの量。値が高くなるほど、ビデオは調整画像に似なくなります。この値を増やすと、生成されるビデオのモーションも増加します。