гғӣгғјгғ
>> гғҳгғғгғүгғ©гӮӨгғі
>>
PCдҝ®зҗҶгҒ®гӮҸгҒҹгҒӘгҒ№
гғӣгғјгғ
>> гғҳгғғгғүгғ©гӮӨгғі
>>
PCдҝ®зҗҶгҒ®гӮҸгҒҹгҒӘгҒ№
| гғЎгӮӨгғі | з°Ўжҳ“гғҳгғғгғүгғ©гӮӨгғі |
 |

|
зҸҫеңЁгғҮгғјгӮҝгғҷгғјгӮ№гҒ«гҒҜ 316 件гҒ®гғҮгғјгӮҝгҒҢзҷ»йҢІгҒ•гӮҢгҒҰгҒ„гҒҫгҒҷгҖӮ
гҒҜгҒҳгӮҒгҒ«
гғӯгӮҙзҙ жқҗгӮ’дҪңжҲҗгҒ—гҒҹгҒ„гҒЁжҖқгҒ„гҖҒжҺўгҒ—гҒҰгҒ„гҒҹгҒЁгҒ“гӮҚгҖҒиҲҲе‘іж·ұгҒ„гӮөгӮӨгғҲгӮ’гҒҝгҒӨгҒ‘гҒҹгҖӮ
еҸӮиҖғгӮөгӮӨгғҲ
гҖҺStable Diffusion WEB UIгҒ§з°ЎеҚҳпјҒгҖҖгӮ№гғҶгғғгӮ«гғјгғ»гӮўгӮӨгӮігғігғ»гғӯгӮҙзҙ жқҗгҒ®дҪңгӮҠж–№гҖҸ

дҪңжҲҗйҒҺзЁӢ
еҸӮиҖғгӮөгӮӨгғҲгҒЁеҗҢж§ҳгҒӘзҙ жқҗгӮ’дҪңжҲҗгҒ—гҒҰгҒҝгҒҫгҒ—гҒҹгҖӮ
?гғ—гғӘгғігғҲгӮ№гғҶгғғгӮ«гғјйўЁ
(high resolution:1.5),logo design art,Vivid Colors,cool,Messily painted,smooth vector,(white background),punk and wolf
motif,
neg:(worst quality:2),(low quality:2),

?гӮ№гғҶгғғгӮ«гғјгғӯгӮҙйўЁ
(high resolution:1.5),2d ferocious wolf head, vector illustration, angry eyes, team emblem logo, 2d flat, centered
nega:(worst quality:2),(low quality:1.4),((3d, cartoon)),

?гӮўгғјгғҲгғӯгӮҙйўЁ
(high resolution:1.5),futuristic minimalistic centered stylized logo of a subject,botanical motif white with black
background, smooth vector, typo
nega:(worst quality:2),(low quality:1.4),((3d, cartoon)),

?гғўгғҖгғігӮўгӮӨгӮігғійўЁ
(high resolution:1.5),Clean, sharp, vectorized, Company logo,castle and sword motif,icon,trending,modern and
minimalist,monochrome,
neg:(worst quality:2),(low quality:1.4),((3d, cartoon)),

?гӮўгӮӨгӮігғійўЁ
(highly detailed),Simple and iconic logo design chart of combining (castle:1.2) motifs, (chain) accent, vector drawing,
trending on behance ,simple, minimal
nega:(worst quality:2),(low quality:2),

?гӮ·гғігғ—гғ«гғӯгӮҙйўЁ
simple symbol logo,stylish,cool,white background,vector,flat,
nega:(worst quality:2),(low quality:1.4),((3d, cartoon)),

жҒҜжҠңгҒҚгӮ’гӮӮе…јгҒӯгҒҰгҖҒйҒҠгҒ°гҒӣгҒҰгҒ„гҒҹгҒ гҒҚгҒҫгҒ—гҒҹгҖӮ
63800еҶҶ вҶ’? 58000 еҶҶпјҲвҖ»еңЁеә«еҮҰеҲҶпјү
第7дё–д»ЈвҳҶVAIOвҳҶVJPG11C11NвҳҶCore i5 2.50GHz/8GB/SSD256GB/з„Ўз·ҡ/Bluetooth/WEBгӮ«гғЎгғ©/ Office 2021 /Win11
еҸӮиҖғиіҮж–ҷ
гҒӮгӮӢеӯҰж ЎгҒ«й…ҚеёғгҒ•гӮҢгҒҹгғ‘гӮҪгӮігғіиІ©еЈІгғ‘гғігғ•гғ¬гғғгғҲ

гӮ®гғЈгғ©гғӘгғј








иӘ¬жҳҺ
Intel Core i5гғ—гғӯгӮ»гғғгӮөгғјпјҶгғЎгғўгғӘ8GBжҗӯијүгҒ§гҖҒеӢ•дҪңгӮӮеҝ«йҒ©вҷӘ
- Core i5
- SSD 256GB
- и¶…и»ҪйҮҸгҒ§дёҲеӨ«гҒӘгғўгғҮгғ«гҒ§гҒҷгҖӮгҒқгҒ®дёҠгҖҒжҖ§иғҪгӮӮз”ігҒ—еҲҶгҒӮгӮҠгҒҫгҒӣгӮ“гҖӮ
- й«ҳжҖ§иғҪгҒӘCPUгҒ® Core i5 гҖҒ SSD256GB (иӘӯгҒҝжӣёгҒҚгҒҢйҖҹгҒ„пјҒ)гҒЁ,еӨ§е®№йҮҸ гғЎгғўгғӘ8GB гҒ§гҒҷгҖӮ
- жңҖж–°гҒ® Microsoft office 2021 Professional Plus гӮӨгғігӮ№гғҲгғјгғ«жёҲгҒҝпјҒ
з„Ўз·ҡLANеҶ…и”өгҒӘгҒ®гҒ§гҖҒ家гҒ®дёӯгҒ§гӮӮгӮұгғјгғ–гғ«дёҚиҰҒгғ»е ҙжүҖгӮ’йҒёгҒ°гҒҡгғҚгғғгғҲгҒҢеҮәжқҘгҒҫгҒҷпјҒ
дҪҝз”Ёж„ҹгӮӮе°‘гҒӘгҒҸгҖҒгҒӮгӮӢзЁӢеәҰзҫҺе“ҒгҒ«жҖқгҒ„гҒҫгҒҷгҖӮ
| зҠ¶ж…Ӣ | дёӯеҸӨе“ҒгҖҗзҫҺе“ҒгҖ‘ |
|---|---|
| гғ‘гӮҪгӮігғігғЎгғјгӮ«гғј | VAIO |
| еһӢз•Ә | VJPG11C11N |
| гӮ«гғ©гғј | гғ–гғ©гғғгӮҜ |
| CPU | Core i5-7200U гғ—гғӯгӮ»гғғгӮөгғј 2.50 GHz (жңҖеӨ§3.10 GHz) |
| гғЎгғўгғӘ | 8 GB |
| гӮ№гғҲгғ¬гғјгӮё | SSD 256GB |
| иЎЁзӨәиғҪеҠӣ | 13.3еһӢ |
| и§ЈеғҸеәҰ | 1920Г—1080гғүгғғгғҲ |
| OS | Windows11 Pro |
| гӮҪгғ•гғҲ | Microsoft Office Professional plus 2021 |
| е…үеӯҰгғүгғ©гӮӨгғ– | з„Ў |
| гғҚгғғгғҲгғҜгғјгӮҜ | жңүз·ҡпјҡгҖҮ / з„Ўз·ҡпјҡв—Ӣ |
| жҺҘз¶ҡз«Ҝеӯҗ | USB (USB 3.0) зөҰйӣ»ж©ҹиғҪд»ҳгҒҚ Г— 1гҖҒUSB (USB 3.0) Г— 2гҖҖ |
| еҶ…и”өж©ҹиғҪ | WEBгӮ«гғЎгғ© / Bluetooth / гӮ№гғ”гғјгӮ«гғј / гғҶгғігӮӯгғј |
| гӮӨгғігӮҝгғјгғ•гӮ§гғјгӮ№ | SDгӮ«гғјгғүгӮ№гғӯгғғгғҲ(SDHCгғ»SDXCеҜҫеҝң) HDMI В® еҮәеҠӣз«ҜеӯҗГ—1 |
| д»ҳеұһе“Ғ | йӣ»жәҗгӮўгғҖгғ—гӮҝ / ACгӮұгғјгғ–гғ«гҖҖ |
| еӨ–еҪўеҜёжі• | зҙ„ 1.06 пҪӢ g |
ж–ҷйҮ‘
зЁҺиҫј? 63800еҶҶ ?пјҲзЁҺжҠң58000еҶҶпјүвҶ’? 58000 еҶҶпјҲвҖ»еңЁеә«еҮҰеҲҶпјү
гҒҠе•ҸгҒ„еҗҲгӮҸгҒӣ
вҖ»е•Ҷе“ҒгӮҝгӮӨгғҲгғ«гӮ’гҖҢйЎҢеҗҚгҖҚгҒ«гӮігғ”гғјгҒ—гҒҰйҖҒдҝЎгҒ—гҒҰгҒҸгҒ гҒ•гҒ„
[contact-form-7]
79200еҶҶ вҶ’ 72000 еҶҶ ?пјҲвҖ»еңЁеә«еҮҰеҲҶпјү
гҖҗзҲҶйҖҹSSDвҳҶWin11 ProгҖ‘TOSHIBA dynabook UZ63/H вҳҶж–°е“ҒM.2 SSD1TB!/Core i7/ж–°е“ҒгӮӯгғјгғңгғјгғү/ж–°е“ҒгғҗгғғгғҶгғӘгғј/гғЎгғўгғӘпјҳGB/MS Office 2021
еҸӮиҖғиіҮж–ҷ
гҒӮгӮӢеӯҰж ЎгҒ«й…ҚеёғгҒ•гӮҢгҒҹгғ‘гӮҪгӮігғіиІ©еЈІгғ‘гғігғ•гғ¬гғғгғҲ
гӮ®гғЈгғ©гғӘгғј









иӘ¬жҳҺ
Intel Core i7гғ—гғӯгӮ»гғғгӮөгғјпјҶгғЎгғўгғӘ8GBжҗӯијүгҒ§гҖҒеӢ•дҪңгӮӮеҝ«йҒ©вҷӘ

- M.2 NVMe SSD пј‘TB(1000GBпјүгҖҗж–°е“ҒгҖ‘
вҖ»дёҖиҲ¬зҡ„гҒӘSSDгӮҲгӮҠй«ҳйҖҹ - гӮӯгғјгғңгғјгғүжҸӣиЈ… гҖҗж–°е“ҒгҖ‘
- гғҗгғғгғҶгғӘгғјжҸӣиЈ… гҖҗж–°е“ҒгҖ‘
- и¶…и»ҪйҮҸгҒ§дёҲеӨ«гҒӘгғўгғҮгғ«гҒ§гҒҷгҖӮгҒқгҒ®дёҠгҖҒжҖ§иғҪгӮӮз”ігҒ—еҲҶгҒӮгӮҠгҒҫгҒӣгӮ“гҖӮ
- ж–°е“ҒгӮӯгғјгғңгғјгғүгҒ«жҸӣиЈ… гҒ—гҒҫгҒ—гҒҹгҒ®гҒ§гҖҒгҒҚгӮҢгҒ„гҒӘзҠ¶ж…ӢгҒ§гҒҷгҖӮ
- гғҗгғғгғҶгғӘгғјгӮӮзҙ”жӯЈж–°е“ҒгҒ«жҸӣиЈ… гҒ—гҒҫгҒ—гҒҹгҒ®гҒ§гҖҒеӨ–еҮәе…ҲгҒ§гҒ®дҪҝз”ЁгӮӮе®үеҝғгҒ§гҒҷгҖӮ
- harman/kardonгҒ®гӮ№гғ”гғјгӮ«гғјгӮ·гӮ№гғҶгғ гҒ§гҒ„гҒ„йҹігҒ§гҒҷгҖӮ
- й«ҳжҖ§иғҪгҒӘCPUгҒ® Core i7 (第8дё–д»Ј)гҖҒеӨ§е®№йҮҸгҒ®ж–°е“Ғ M.2 SSDпј‘TB (иӘӯгҒҝжӣёгҒҚгҒҢйҖҹгҒ„пјҒ)гҒЁ,еӨ§е®№йҮҸ гғЎгғўгғӘ8GB гҒ§гҖҒеӢ•з”»з·ЁйӣҶгӮӮгҒ„гҒ‘гҒҫгҒҷгҖӮ
- жңҖж–°гҒ® Microsoft office 2021 Professional Plus гӮӨгғігӮ№гғҲгғјгғ«жёҲгҒҝпјҒ
з„Ўз·ҡLANеҶ…и”өгҒӘгҒ®гҒ§гҖҒ家гҒ®дёӯгҒ§гӮӮгӮұгғјгғ–гғ«дёҚиҰҒгғ»е ҙжүҖгӮ’йҒёгҒ°гҒҡгғҚгғғгғҲгҒҢеҮәжқҘгҒҫгҒҷпјҒ
дҪҝз”Ёж„ҹгӮӮе°‘гҒӘгҒҸгҖҒгҒӮгӮӢзЁӢеәҰзҫҺе“ҒгҒ«жҖқгҒ„гҒҫгҒҷгҖӮ
| зҠ¶ж…Ӣ | дёӯеҸӨе“Ғ |
|---|---|
| гғ‘гӮҪгӮігғігғЎгғјгӮ«гғј | TOSHIBA |
| еһӢз•Ә | dynabook UZ63/H |
| гӮ«гғ©гғј | гғ–гғ©гғғгӮҜ |
| CPU | гӮӨгғігғҶгғ« Core i7-8550U |
| гғЎгғўгғӘ | 8 GB |
| гӮ№гғҲгғ¬гғјгӮё | M.2 NVMeSSD пј‘TBпјҲ1000GBпјүгҖҗж–°е“ҒгҖ‘ |
| иЎЁзӨәиғҪеҠӣ | 13.3еһӢ FHD |
| и§ЈеғҸеәҰ | 1,920Г—1,080гғүгғғгғҲ |
| OS | Windows11 Pro |
| гӮҪгғ•гғҲ | Microsoft Office Professional plus 2021 |
| е…үеӯҰгғүгғ©гӮӨгғ– | з„Ў |
| гғҚгғғгғҲгғҜгғјгӮҜ | з„Ўз·ҡпјҡв—Ӣ |
| жҺҘз¶ҡз«Ҝеӯҗ | USB:1еҖӢгҖҖSDгӮ«гғјгғүгӮ№гғӯгғғгғҲ |
| еҶ…и”өж©ҹиғҪ | WEBгӮ«гғЎгғ© / Bluetooth / гӮ№гғ”гғјгӮ«гғј / гғҶгғігӮӯгғј |
| гӮӨгғігӮҝгғјгғ•гӮ§гғјгӮ№ | гғһгӮӨгӮҜе…ҘеҠӣ/гғҳгғғгғүгғӣгғіеҮәеҠӣз«ҜеӯҗГ—1 Thunderboltв„ў 3(USB Type-Cв„ў)гӮігғҚгӮҜгӮҝ(йӣ»жәҗгӮігғҚгӮҜгӮҝ)Г—2 HDMI В® еҮәеҠӣз«ҜеӯҗГ—1 |
| д»ҳеұһе“Ғ | йӣ»жәҗгӮўгғҖгғ—гӮҝ / ACгӮұгғјгғ–гғ«гҖҖ |
| еӨ–еҪўеҜёжі• | зҙ„316.0пјҲе№…пјүГ—227.0пјҲеҘҘиЎҢпјүГ—15.9пјҲй«ҳгҒ•пјүmmгҖҖ зҙ„1,090g |
ж–ҷйҮ‘
зЁҺиҫј? 79200еҶҶ ?пјҲзЁҺжҠң72000еҶҶпјүвҶ’гҖҖзЁҺиҫј? 72000 еҶҶ ?пјҲвҖ»еңЁеә«еҮҰеҲҶпјү
гҒҠе•ҸгҒ„еҗҲгӮҸгҒӣ
вҖ»е•Ҷе“ҒгӮҝгӮӨгғҲгғ«гӮ’гҖҢйЎҢеҗҚгҖҚгҒ«гӮігғ”гғјгҒ—гҒҰйҖҒдҝЎгҒ—гҒҰгҒҸгҒ гҒ•гҒ„
[contact-form-7]
74800еҶҶ вҶ’гҖҖзЁҺиҫј? 68000 еҶҶ ?пјҲвҖ»еңЁеә«еҮҰеҲҶпјү
Dynabook S73/HSгғ»з¬¬11дё–д»ЈCorei3гғ»гғЎгғўгғӘ16Gгғ»ж–°е“ҒSSD500Gгғ»Win11Proгғ»13.3еһӢFHDгғ»office2021
еҸӮиҖғиіҮж–ҷ
гҒӮгӮӢеӯҰж ЎгҒ«й…ҚеёғгҒ•гӮҢгҒҹгғ‘гӮҪгӮігғіиІ©еЈІгғ‘гғігғ•гғ¬гғғгғҲ
гӮ®гғЈгғ©гғӘгғј









иӘ¬жҳҺ
Intel Core i3гғ—гғӯгӮ»гғғгӮөгғјпјҶгғЎгғўгғӘ16GBжҗӯијүгҒ§гҖҒеӢ•дҪңгӮӮеҝ«йҒ©вҷӘ
- M.2 NVMe SSD 500GBгҖҗж–°е“ҒгҖ‘
вҖ»дёҖиҲ¬зҡ„гҒӘSSDгӮҲгӮҠй«ҳйҖҹ
- и¶…и»ҪйҮҸгҒ§дёҲеӨ«гҒӘгғўгғҮгғ«гҒ§гҒҷгҖӮгҒқгҒ®дёҠгҖҒжҖ§иғҪгӮӮз”ігҒ—еҲҶгҒӮгӮҠгҒҫгҒӣгӮ“гҖӮ
- й«ҳжҖ§иғҪгҒӘCPUгҒ® Core i3 гҖҒеӨ§е®№йҮҸгҒ®ж–°е“Ғ M.2 SSD 500GB (иӘӯгҒҝжӣёгҒҚгҒҢйҖҹгҒ„пјҒ)гҒЁ,еӨ§е®№йҮҸ гғЎгғўгғӘ16GB гҒ§гҖҒеӢ•з”»з·ЁйӣҶгӮӮгҒ„гҒ‘гҒҫгҒҷгҖӮ
- жңҖж–°гҒ® Microsoft office 2021 Professional Plus гӮӨгғігӮ№гғҲгғјгғ«жёҲгҒҝпјҒ
з„Ўз·ҡLANеҶ…и”өгҒӘгҒ®гҒ§гҖҒ家гҒ®дёӯгҒ§гӮӮгӮұгғјгғ–гғ«дёҚиҰҒгғ»е ҙжүҖгӮ’йҒёгҒ°гҒҡгғҚгғғгғҲгҒҢеҮәжқҘгҒҫгҒҷпјҒ
ж–°е“ҒгҒ«иҝ‘гҒҸдҪҝз”Ёж„ҹгӮӮе°‘гҒӘгҒҸгҖҒгҒӮгӮӢзЁӢеәҰзҫҺе“ҒгҒ«жҖқгҒ„гҒҫгҒҷгҖӮ
| зҠ¶ж…Ӣ | дёӯеҸӨе“ҒгҖҗзҫҺе“ҒгҖ‘ |
|---|---|
| гғ‘гӮҪгӮігғігғЎгғјгӮ«гғј | TOSHIBA |
| еһӢз•Ә | Dynabook S73/HS |
| гӮ«гғ©гғј | гғ–гғ©гғғгӮҜ |
| CPU | Core i3-1115G4 |
| гғЎгғўгғӘ | 16 GB |
| гӮ№гғҲгғ¬гғјгӮё | M.2 NVMeSSD 500GBгҖҗж–°е“ҒгҖ‘ |
| иЎЁзӨәиғҪеҠӣ | 13.3еһӢ |
| и§ЈеғҸеәҰ | 1920Г—1080гғүгғғгғҲ |
| OS | Windows11 Pro |
| гӮҪгғ•гғҲ | Microsoft Office Professional plus 2021 |
| е…үеӯҰгғүгғ©гӮӨгғ– | з„Ў |
| гғҚгғғгғҲгғҜгғјгӮҜ | жңүз·ҡпјҡгҖҮ / з„Ўз·ҡпјҡв—Ӣ |
| жҺҘз¶ҡз«Ҝеӯҗ | USB3.1 Gen1(USB3.0) Type-Ax2/Type-Cx1 |
| еҶ…и”өж©ҹиғҪ | WEBгӮ«гғЎгғ© / Bluetooth / гӮ№гғ”гғјгӮ«гғј / гғҶгғігӮӯгғј |
| гӮӨгғігӮҝгғјгғ•гӮ§гғјгӮ№ | HDMIx1 microSDгӮ№гғӯгғғгғҲ |
| д»ҳеұһе“Ғ | йӣ»жәҗгӮўгғҖгғ—гӮҝ / ACгӮұгғјгғ–гғ«гҖҖ |
| еӨ–еҪўеҜёжі• | 316 x 19.9 x 227 mm, 1.269 kg |
ж–ҷйҮ‘
зЁҺиҫј? 74800еҶҶ ?пјҲзЁҺжҠң68000еҶҶпјүвҶ’гҖҖзЁҺиҫј? 68000 еҶҶ ?пјҲвҖ»еңЁеә«еҮҰеҲҶпјү
гҒҠе•ҸгҒ„еҗҲгӮҸгҒӣ
вҖ»е•Ҷе“ҒгӮҝгӮӨгғҲгғ«гӮ’гҖҢйЎҢеҗҚгҖҚгҒ«гӮігғ”гғјгҒ—гҒҰйҖҒдҝЎгҒ—гҒҰгҒҸгҒ гҒ•гҒ„
[contact-form-7]
гҒҜгҒҳгӮҒгҒ«
еҶҚеәҰгҖҒstable video diffusionгҒ§еӢ•з”»гӮ’з”ҹжҲҗгҒ—гҒҰгҒҝгӮӢгҖӮ
з”ҹжҲҗйҒҺзЁӢ
Stable Diffusion гҒ§AIз”»еғҸз”ҹжҲҗ

stable video diffusionгҒ§AIеӢ•з”»з”ҹжҲҗ

VideoProc VloggerгҒ§еӢ•з”»еҲ¶дҪң

еӢ•з”»е®ҢжҲҗ
гҒҜгҒҳгӮҒгҒ«
жҳ з”»гҒ®гӮҲгҒҶгҒӘз¶әйә—гҒӘз”»еғҸгӮ’дҪңгҒЈгҒҰгҒҝгҒҹгҒ„гҒЁжҖқгҒЈгҒҹгҖӮ
еҝҚиҖ…гҒ®гӮ№гӮҝгӮӨгғ«гҒ§гҖҒгҒҫгҒҡгҒҜи©ҰгҒҝгҒҹгҖӮ
з”ҹжҲҗйҒҺзЁӢ
гғ—гғӯгғігғ—гғҲ
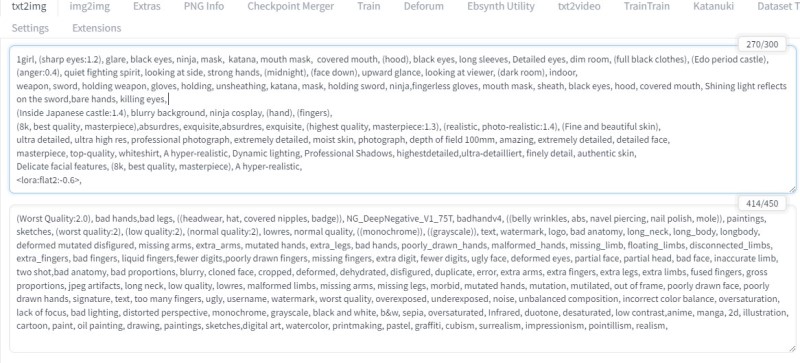
Hires.fixгҖҒADetailerгҒӘгҒ©гӮ’дҪҝз”Ё
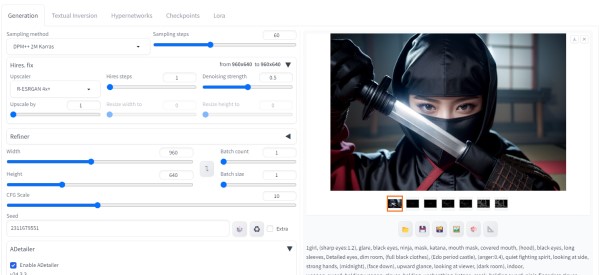
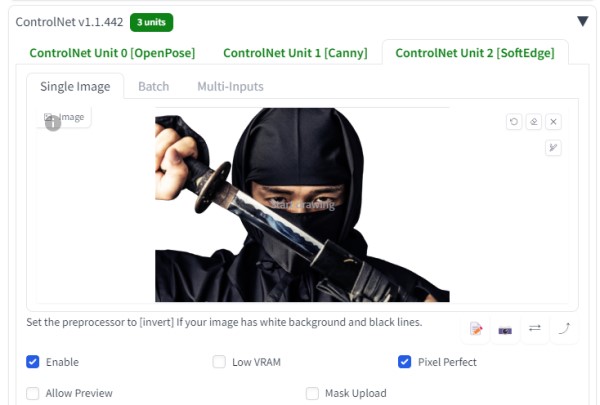
ControlNetгҖҗOpenPose:Canny:SoftEdgeгҖ‘гӮ’дҪҝз”Ё
гҒҸгғҺдёҖгҖҗгӮ®гғЈгғ©гғӘгғјгҖ‘




гҒҜгҒҳгӮҒгҒ«
CanvaгҒ§гӮўгғӢгғЎгғјгӮ·гғ§гғігӮ’дҪңжҲҗгҒ§гҒҚгӮӢгҒ“гҒЁгҒҢгӮҸгҒӢгҒЈгҒҹ
еҸӮиҖғгӮөгӮӨгғҲ
CANVAгҒ§дәәгҒҢи©ұгҒҷгӮўгғӢгғЎгғјгӮ·гғ§гғіеӢ•з”»гӮ’дҪңжҲҗгҒҷгӮӢж–№жі•
гӮўгғӢгғЎгғјгӮ·гғ§гғідҪңжҲҗ
Canva

йҹіиӘӯгҒ•гӮ“

CanvaдҪңжҲҗйҒҺзЁӢ

гӮўгғӢгғЎгғјгӮ·гғ§гғіе®ҢжҲҗ
иҖғеҜҹ
еҸЈгғ‘гӮҜгҒҢз°ЎеҚҳгҒ«гҒ§гҒҚгҒҹгҖӮ
йҹіиӘӯгҒ•гӮ“гҒ«гӮҲгӮҠгҖҒгғҠгғ¬гғјгӮ·гғ§гғігӮӮз°ЎеҚҳгҒ«гҒ§гҒҚгҒҹгҖӮ
гӮҝгӮ№гӮҜгғҗгғјгҒ®е·ҰжҸғгҒҲ
- гӮҝгӮ№гӮҜгғҗгғјгӮ’еҸігӮҜгғӘгғғгӮҜгҒ—гҖҒгӮҝгӮ№гӮҜгғҗгғјгҒ®иЁӯе®ҡгӮ’гӮҜгғӘгғғгӮҜ
- гӮҝгӮ№гӮҜгғҗгғјгҒ®еӢ•дҪңгҒҫгҒ§з§»еӢ•
- гҖҢдёӯеӨ®жҸғгҒҲгҖҚгҒӢгӮүгҖҢе·ҰжҸғгҒҲгҖҚгҒёеӨүжӣҙгҒҷгӮӢ
гӮҝгӮ№гӮҜгғҗгғјгҒҢгҖҢе·ҰжҸғгҒҲгҖҚгҒ«гҒӘгӮҠгҒҫгҒ—гҒҹ
гҒҜгҒҳгӮҒгҒ«
ж—Ҙжң¬жңҖеҸӨгҒ®еҶҷзңҹгӮ’гӮ«гғ©гғјеҢ–гҒ—гҒҰгҒҝгҒҹгҖӮ
гҖҗдёҖеәҰгҒҜиҰӢгҒҰгҒҠгҒҚгҒҹгҒ„пјҒгҖ‘дё–з•ҢжңҖеҸӨгғ»ж—Ҙжң¬жңҖеҸӨгҒ®жҳ еғҸпјҶеҶҷзңҹ

ж—Ҙжң¬еҶҷзңҹеҸІ

вҖ»дёҠиЁҳгӮөгӮӨгғҲгҒӢгӮүеҶҷзңҹгӮ’жӢқеҖҹгҒ•гҒӣгҒҰгҒ„гҒҹгҒ гҒҚгҒҫгҒ—гҒҹ
гӮ®гғЈгғ©гғӘгғј










49500еҶҶ вҶ’? 44000 еҶҶпјҲвҖ»еңЁеә«еҮҰеҲҶпјү
ж–°е“ҒгғЎгғўгғӘ16GBжҗӯијү/и¶…зҫҺе“Ғ/第7дё–д»Јi3/ж–°е“ҒSSD1TB/WebгӮ«гғЎгғ©/Blu-ray/Office/Win11/
гӮ®гғЈгғ©гғӘгғј






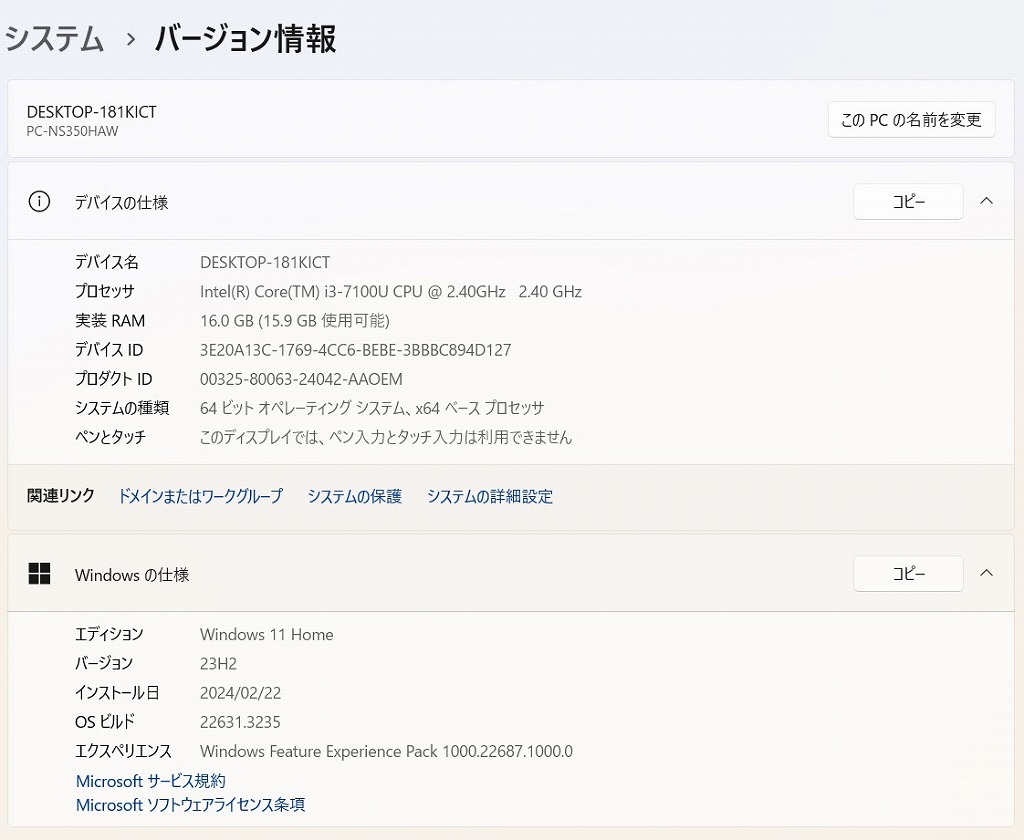
иӘ¬жҳҺ
Intel Core i3гғ—гғӯгӮ»гғғгӮөгғјпјҶж–°е“ҒгғЎгғўгғӘ16GBжҗӯијүгҒ§гҖҒеӢ•дҪңгӮӮеҝ«йҒ©вҷӘ
гғҸгғјгғүгғҮгӮЈгӮ№гӮҜгӮӮж–°е“Ғ1TB(1000GB)SSDгҒёжҸӣиЈ…жёҲгҒҝпјҒ
з„Ўз·ҡLANеҶ…и”өгҒӘгҒ®гҒ§гҖҒ家гҒ®дёӯгҒ§гӮӮгӮұгғјгғ–гғ«дёҚиҰҒгғ»е ҙжүҖгӮ’йҒёгҒ°гҒҡгғҚгғғгғҲгҒҢеҮәжқҘгҒҫгҒҷпјҒ
гҒ»гҒјж–°е“ҒгҒ«иҝ‘гҒҸгҖҒи¶…зҫҺе“ҒгҒ«жҖқгҒ„гҒҫгҒҷгҖӮ
| зҠ¶ж…Ӣ | дёӯеҸӨе“ҒгҖҗзҫҺе“ҒгҖ‘ |
|---|---|
| гғ‘гӮҪгӮігғігғЎгғјгӮ«гғј | NEC |
| еһӢз•Ә | PC-NS350HAW |
| гӮ«гғ©гғј | гӮҜгғӘгӮ№гӮҝгғ«гғӣгғҜгӮӨгғҲ |
| CPU | Intel CORE i3-7100U 2.40GHz |
| гғЎгғўгғӘ | 16 GB |
| гӮ№гғҲгғ¬гғјгӮё | SSD пј‘TBпјҲ1000 GBпјү |
| иЎЁзӨәиғҪеҠӣ | 15.6 гӮӨгғігғҒ |
| OS | Windows 11 Home 64 bit |
| гӮҪгғ•гғҲ | Microsoft Office 365 |
| е…үеӯҰгғүгғ©гӮӨгғ– | Blu-ray Disc е…үеӯҰгғүгғ©гӮӨгғ–жҗӯијү |
| гғҚгғғгғҲгғҜгғјгӮҜ | жңүз·ҡпјҡв—Ӣ / з„Ўз·ҡпјҡв—Ӣ |
| жҺҘз¶ҡз«Ҝеӯҗ | USB 3.0пҪҳ 3 еҖӢ |
| еҶ…и”өж©ҹиғҪ | WEBгӮ«гғЎгғ© / Bluetooth / гӮ№гғ”гғјгӮ«гғј / гғҶгғігӮӯгғј |
| д»ҳеұһе“Ғ | йӣ»жәҗгӮўгғҖгғ—гӮҝ / ACгӮұгғјгғ–гғ«гҖҖ |
ж–ҷйҮ‘
зЁҺиҫј? 49500еҶҶ ?пјҲзЁҺжҠң45000еҶҶпјүвҶ’зЁҺиҫј? 44000 еҶҶпјҲвҖ»еңЁеә«еҮҰеҲҶпјү
гҒҠе•ҸгҒ„еҗҲгӮҸгҒӣ
вҖ»е•Ҷе“ҒгӮҝгӮӨгғҲгғ«гӮ’гҖҢйЎҢеҗҚгҖҚгҒ«гӮігғ”гғјгҒ—гҒҰйҖҒдҝЎгҒ—гҒҰгҒҸгҒ гҒ•гҒ„
[contact-form-7]