ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
現在データベースには 492 件のデータが登録されています。
【新品】980円









耐熱ガラス製ボウル3個セット
S:幅156×奥行156×高さ102mm
M:幅187×奥行187×高さ115mm
L:幅210×奥行210×高さ120mm
「MADE IN JAPAN」
HARIOの耐熱ガラスのほとんどは日本の自社工場で作られています。
重金属などは一切使わずピュアな素材だけを用いて
HARIOの耐熱ガラスは作られています。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

完売しました。
値下 160,000円
ローカルPCでAI画像を生成したい方へ
AI画像を生成するためには、高スペックなパソコンが必要です。
最小スペックでも15万円以上のパソコンが必要となります。
※特にグラフィックボード(GPU)
私もはじめは最小スペックでAI画像を生成していました。
しかし、生成時間があまりにもかかるので、少しずつですがスペックを上げていきました。
高スペックにすればするほど、生成時間も短縮され、AI画像を生成することが楽しくなりました。
AI画像生成に興味を持たれた方は、まずは以下のサイトをご覧ください。

パソコンスペック
| 筐体 | サーマルテイク(thermaltake) |
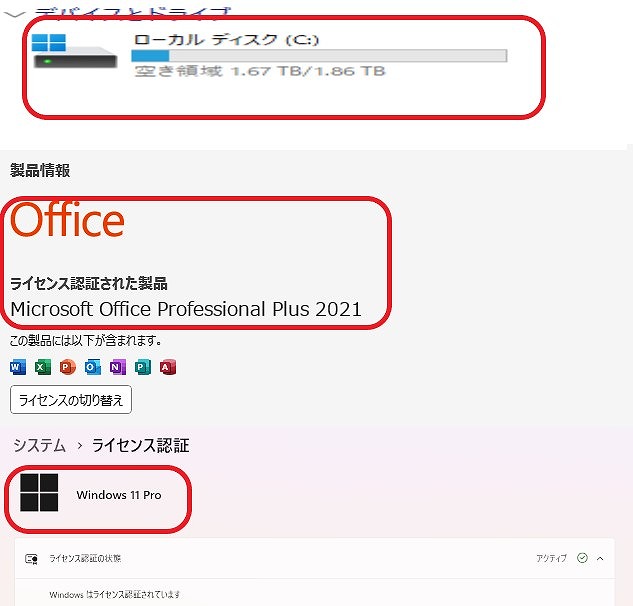
| OS | Windows11 Pro |
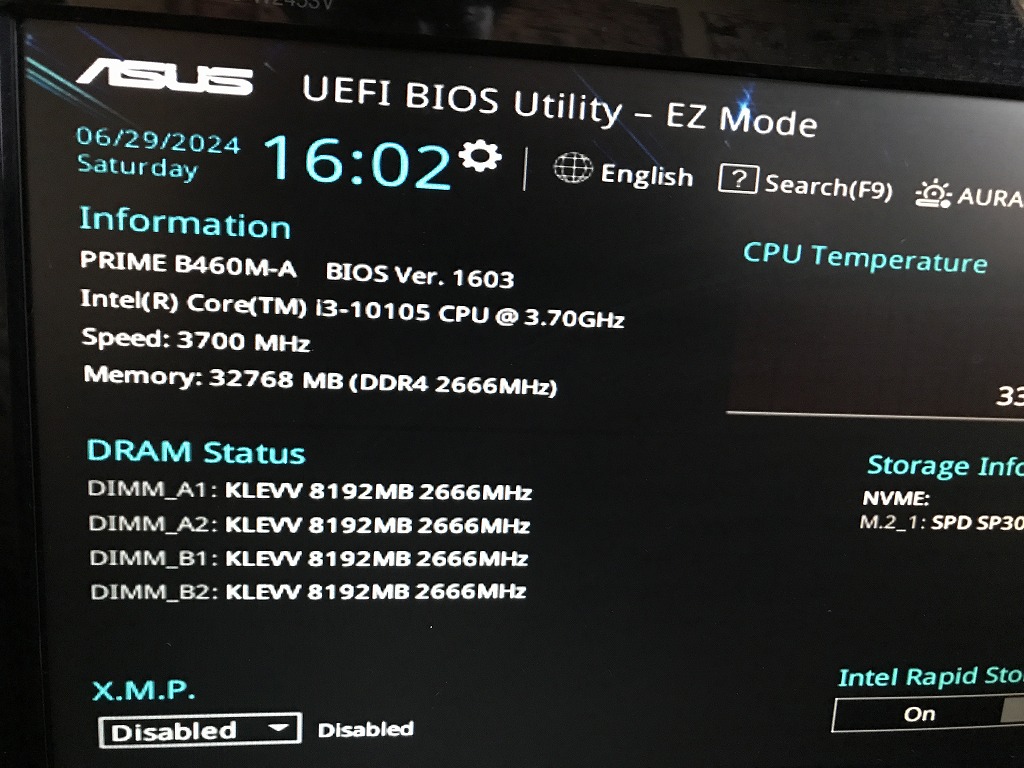
| マザーボード | B460M-A |
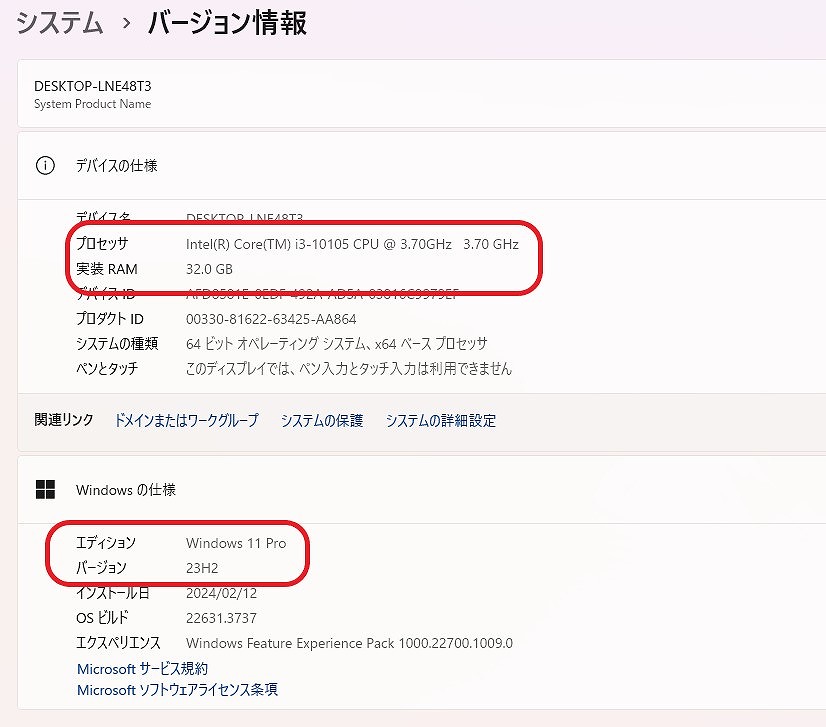
| CPU | Intel(R) Core(TM)i3-10105 CPU @ 3.70GHz |
| メモリ | KLEVV 32 GB (スロット:4/4) |
| グラフィック | NVIDIA GeForce RTX 3060 8GB |
| ストレージ | SSD M.2 : 2TB (新品) |
| オフィスソフト | Microsoft Office Pro 2021 |
| 電源ユニット | Corsair CX450M |
| ネットワーク | 有線〇/無線〇(TP-Link WiFi子機 AC1300 867Mbps + 400Mbps ) |
ギャラリー












商品説明
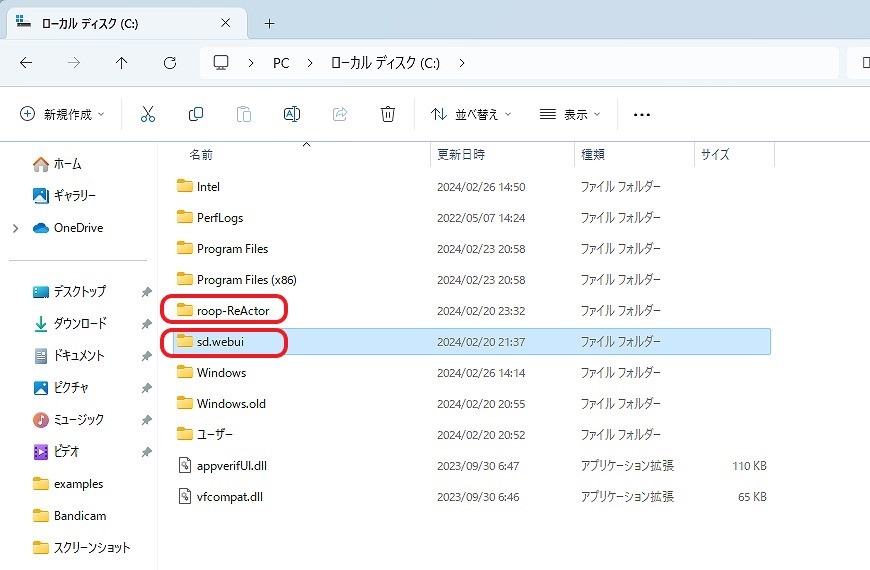
AI画像生成 「 Stable Diffusion WebUI
」を生成するために自作パソコンを構築しました。また、ディープフェイク動画生成する「 Rope
(最新)」「 ReActor-UI 」も構築しました。
グラフィックボードは「 NVIDIA GeForce RTX 3060 8GB
(ASUS) 」です。
CPUは「 Intel(R) Core(TM) i3-10105 CPU @ 3.70GHz 」となります。※ファン:前後、上面などに複数設置済み(生成速度の低下を抑制します)
合計 GPUメモリ24GB (生成する際に使用可能メモリ):専用GPUメモリ「 8GB
」、共有GPUメモリ「 16GB 」
私見になりますが、パソコンはある程度綺麗に使用されていたように感じます。※詳細は、画像でご確認ください。AI画像生成に興味を持たれている方もいるかと思い、出品するにあたり、
「 Stable Diffusion WebUI 」 と「 Rope 」「 ReActor-UI 」
を再構築しました。
ローカルPCなので、AI画像、スワップ動画などを無制限に生成することが可能です。
AI生成にご興味を持たれた方などは、ご検討いただけると有難いです。
AI画像生成 設定済み
●Stable Diffusion WebUI(AI画像生成)
- Stable Diffusion WebUI インストール済み
- CheckPoint インストール済み
- フォルダ内「 webui-user.bat 」ダブルクリックで起動
すぐに、AI画像を生成できます!
●Rope (ディープフェイク動画生成:複数人個別スワップ可)※新スワップUI
- 元動画データ と 変更したい各顔画像 を準備すれば、新しい動画が生成可能
- フォルダ内「 Rope_setup.bat 」ダブルクリックで起動
●ReActor-UI (ディープフェイク動画生成)
- 元動画データ と 変更したい顔画像 を準備すれば、新しい動画が生成可能
- フォルダ内「 ReActor_setup.bat 」ダブルクリックで起動
●roop (ディープフェイク動画生成)
- 元動画データ と 変更したい顔画像 を準備すれば、新しい動画が生成可能
- フォルダ内「 roop_setup.bat 」ダブルクリックで起動
詳細は、「Stable Diffusion」「Rope」「ReActor-UI」で検索をお願いいたします。
AI生成/スワップ方法なども、検索などでご確認いただけるようにお願いいたします。
すぐに、AI画像を生成できます!
「 Stable Diffusion WebUI 」と「 ReActor-UI 」の生成方法
「 Rope 」の生成方法
料金
税込 220,000円 (税抜200,000円)→ 税込 160,000円 (※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

49500円 →? 40000 円(※在庫処分)
新品メモリ16GB搭載/超美品/第7世代i3/新品SSD1TB/Webカメラ/Blu-ray/Office/Win11/
ギャラリー






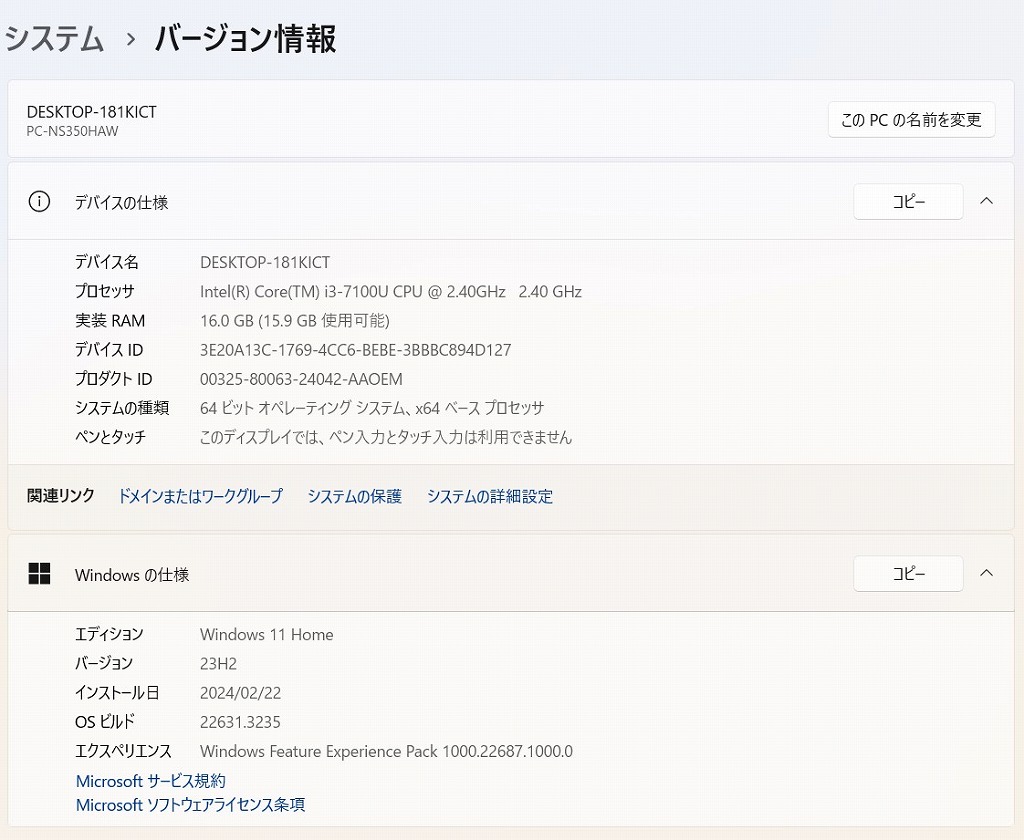
説明
Intel Core i3プロセッサー&新品メモリ16GB搭載で、動作も快適♪
ハードディスクも新品1TB(1000GB)SSDへ換装済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
ほぼ新品に近く、超美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | NEC |
| 型番 | PC-NS350HAW |
| カラー | クリスタルホワイト |
| CPU | Intel CORE i3-7100U 2.40GHz |
| メモリ | 16 GB |
| ストレージ | SSD 1TB(1000 GB) |
| 表示能力 | 15.6 インチ |
| OS | Windows 11 Home 64 bit |
| ソフト | Microsoft Office 365 |
| 光学ドライブ | Blu-ray Disc 光学ドライブ搭載 |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB 3.0x 3 個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル |
料金
税込? 49500円 ?(税抜45000円)→税込? 40000 円(※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

46200円 →? 38000 円(※在庫処分)
高性能第6世代i5搭載/超美品/新品M.2 SATA512GB+HDD512GB/メモリ8GB/Webカメラ/Office/Win11/
ギャラリー







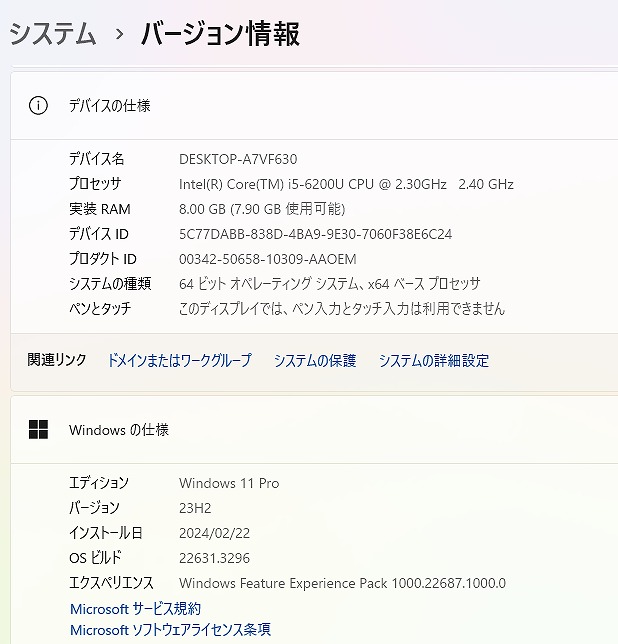

説明
Intel Core i5 プロセッサー& メモリ8GB 搭載で、動作も快適♪
ハードディスクも追加で、新品M.2 SSD 512GB へ換装済み!

- M.2 SSD Type 2280 512GB【新品】 追加
※一般的なSSDより高速
- 高性能なCPUの Core i5 (第6世代)、大容量の新品 M.2 SSD 512TB (読み書きが速い!)と,大容量 メモリ8GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
新品に近く使用感も少なく、美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | HP |
| 型番 | ProBook 450 G3 |
| カラー | ブラック |
| CPU | Intel CORE i5-6200U 2.30-2.80GHz |
| メモリ | 8 GB |
| ストレージ | M.2 SSD 512GB 【新品】+HDD 512 GB 【計1TB(1000GB)】 |
| 表示能力 | 15.6 インチ |
| 解像度 | 1366×768 |
| OS | Windows 11 Pro 64 bit |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | DVDスーパーマルチ |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB: 3.0x2個 2.0x2個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル |
料金
税込? 46200円 ?(税抜42000円)→? 38000 円(※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

79200円 → 60000円 ?(※在庫処分)
ギャラリー







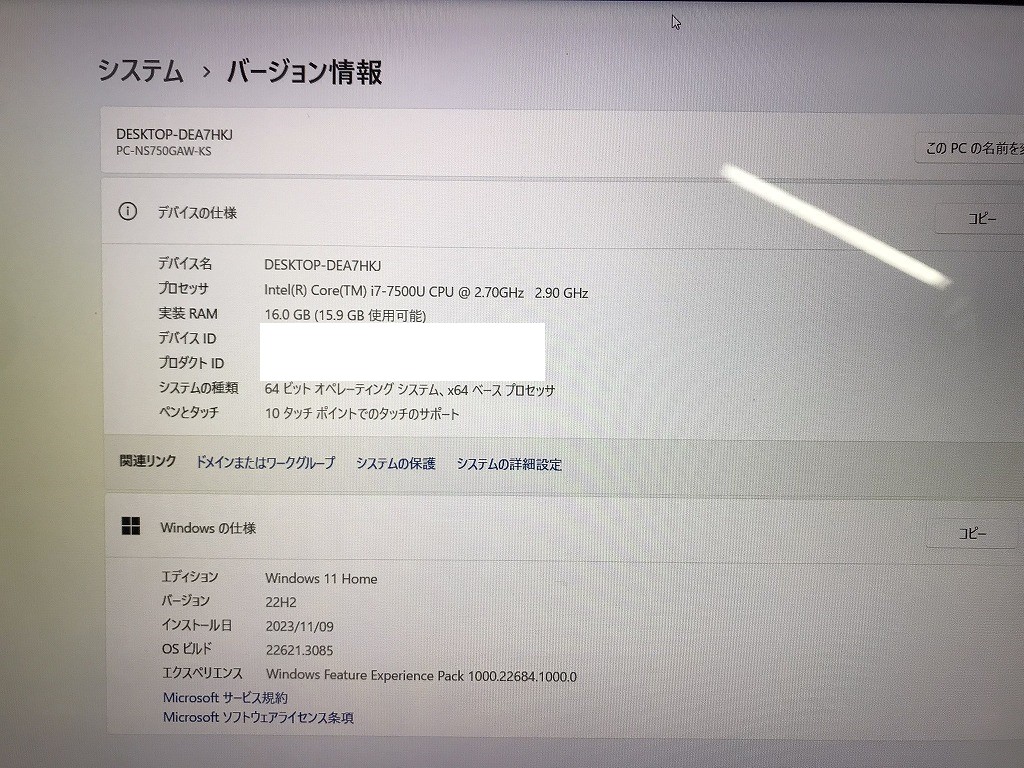
説明
Intel Core i7プロセッサー&メインメモリ16GB(増設済み)搭載で、動作も快適♪
デスクトップPCに勝るとも劣らぬウルトラハイスペックマシン!
ハードディスクも超特盛1TB(1000GB)SSDへ換装済み!
高速化技術を搭載した最新のハードディスクなので、ビデオ編集用マシンにも最適です!
読み書き両対応のブルーレイドライブ内蔵!15.6型のスーパーシャインビューLED液晶に加え、
NECハイエンドノートではお馴染みヤマハ製の高音質2.1ch内蔵スピーカーも搭載!
さらに4K出力対応のHDMI端子も搭載!! 映画視聴にうってつけのモデルです!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | NEC |
| CPU | Intel Core i7 7500U 2.7 GHz |
| メモリ | 16 GB |
| ストレージ | SSD 1TB(1000 GB) |
| 表示能力 | 15.6 インチ 光沢液晶 |
| OS | Windows 11 Home 64 bit |
| ソフト | Microsoft Office Professional Plus 2021 |
| 光学ドライブ | Blu-ray 読込/書込 対応 |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB 3.0 / HDMI端子 / マイク入力 / ヘッドホン出力 / microSDカードスロット / LANポート(100/1000 BASE) / USB Type-C |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル (他社Lenovo) |
| 外形寸法 | 約 382 (幅) × 270 (奥行) × 25.7 (高さ)mm(突起部含まず) |
| 質量 | 約 2.5 kg (標準バッテリパック装着時) |
説明
Intel Core i7プロセッサー&メインメモリ16GB(増設済み)搭載で、動作も快適♪
デスクトップPCに勝るとも劣らぬウルトラハイスペックマシン!
ハードディスクも超特盛1TB(1000GB)SSDへ換装済み!
高速化技術を搭載した最新のハードディスクなので、ビデオ編集用マシンにも最適です!
読み書き両対応のブルーレイドライブ内蔵!15.6型のスーパーシャインビューLED液晶に加え、
NECハイエンドノートではお馴染みヤマハ製の高音質2.1ch内蔵スピーカーも搭載!
さらに4K出力対応のHDMI端子も搭載!! 映画視聴にうってつけのモデルです!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | NEC |
| CPU | Intel Core i7 7500U 2.7 GHz |
| メモリ | 16 GB |
| ストレージ | SSD 1TB(1000 GB) |
| 表示能力 | 15.6 インチ 光沢液晶 |
| OS | Windows 11 Home 64 bit |
| ソフト | Microsoft Office Professional Plus 2021 |
| 光学ドライブ | Blu-ray 読込/書込 対応 |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB 3.0 / HDMI端子 / マイク入力 / ヘッドホン出力 / microSDカードスロット / LANポート(100/1000 BASE) / USB Type-C |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル (他社Lenovo) |
| 外形寸法 | 約 382 (幅) × 270 (奥行) × 25.7 (高さ)mm(突起部含まず) |
| 質量 | 約 2.5 kg (標準バッテリパック装着時) |
料金
税込? 79200円 ?(税抜72000円)→ 税込? 60000円 ?(※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

完売しました。
66000円
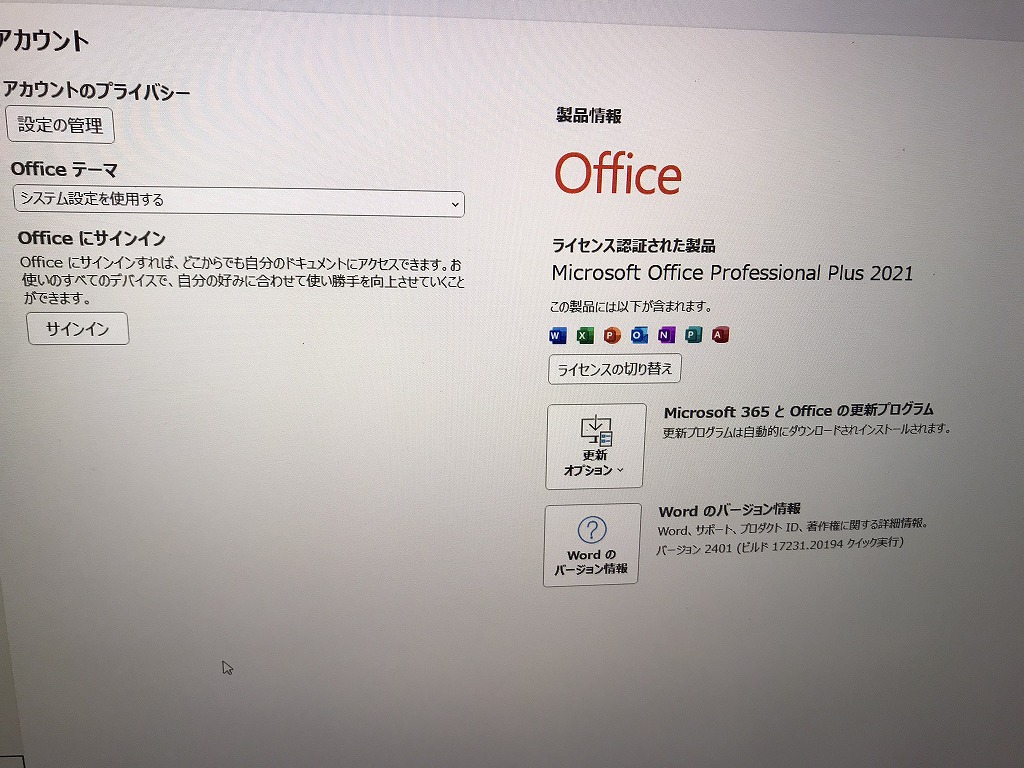
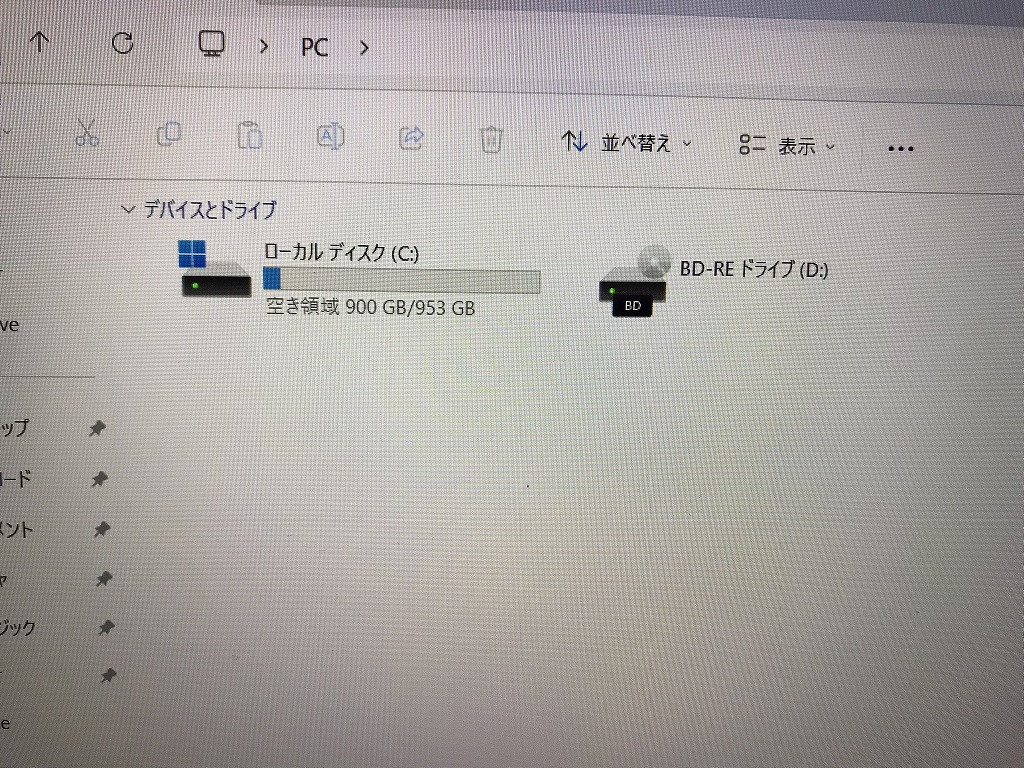
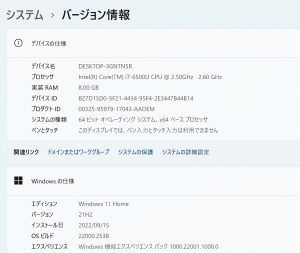
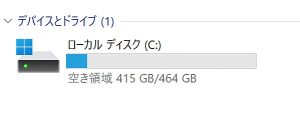
NEC GN256Y/37 M.2 SSD 500GB【新品】/バッテリー【新品】 Win11/Core i7-6500U/8GB/WEBカメラ/無線/Office
参考資料
ある学校に配布されたパソコン販売パンフレット

ギャラリー







説明
Intel Core i7プロセッサー&メモリ8GB搭載で、動作も快適♪

- M.2 SSD 500GB【新品】
※一般的なSSDより高速 - バッテリー 電池パック交換【新品】
- 超軽量で丈夫なモデルです。その上、性能も申し分ありません。
- 高性能なCPUの Core i7 、大容量の新品 M.2 SSD 500GB (読み書きが速い!)と,大容量 メモリ8GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
- 新品バッテリー交換
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
外観に細かい汚れ、傷あります。
| 状態 | 中古品 |
|---|---|
| パソコンメーカー | NEC |
| 型番 | PC-GN256Y3A7 |
| カラー | ブラック |
| CPU | intel Core i7-6500U (2.5GHz) |
| メモリ | 8 GB |
| ストレージ | M.2 SSD 500GB【新品】 |
| 表示能力 | 13.3型 |
| 解像度 | 2560 ×1440ドット |
| OS | Windows11 Home 64bit |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | 無 |
| ネットワーク | 有線:× / 無線:○ |
| 接続端子 | USB:3.0 2個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| インターフェース | HDMI、SDXC |
| 付属品 | 電源アダプタ / ACケーブル |
| 外形寸法 | 316 x 19.9 x 227 mm, 1.269 kg |
料金
税込 66000円 (税抜60000円)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
350000円→200000円(在庫処分)




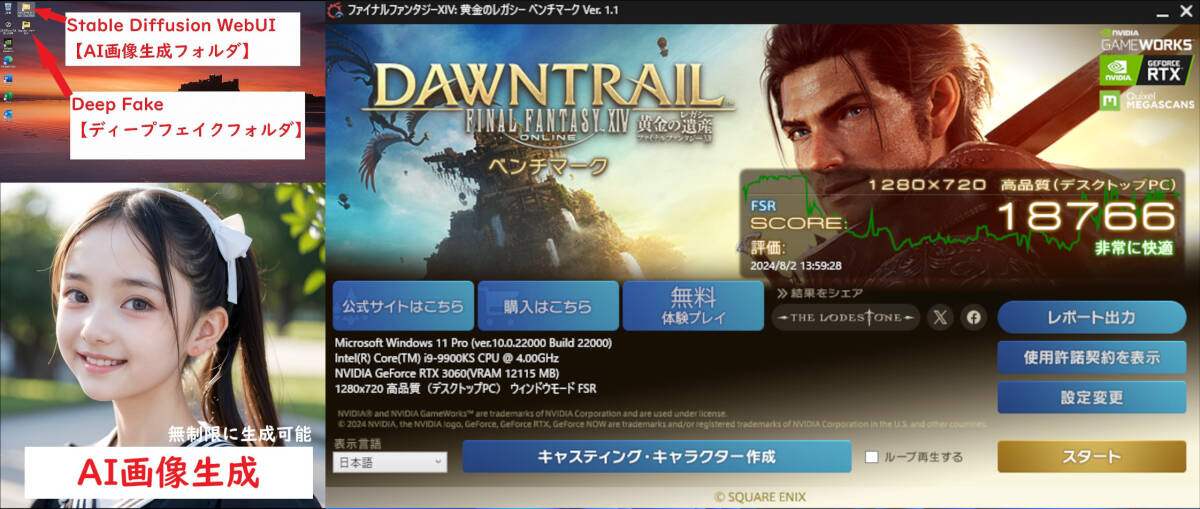



AI画像生成?「Stable Diffusion WebUI」を生成するために自作パソコンを構築しました。
また、ディープフェイク動画生成する「Rope(最新)」「ReActor-UI」も構築しました。
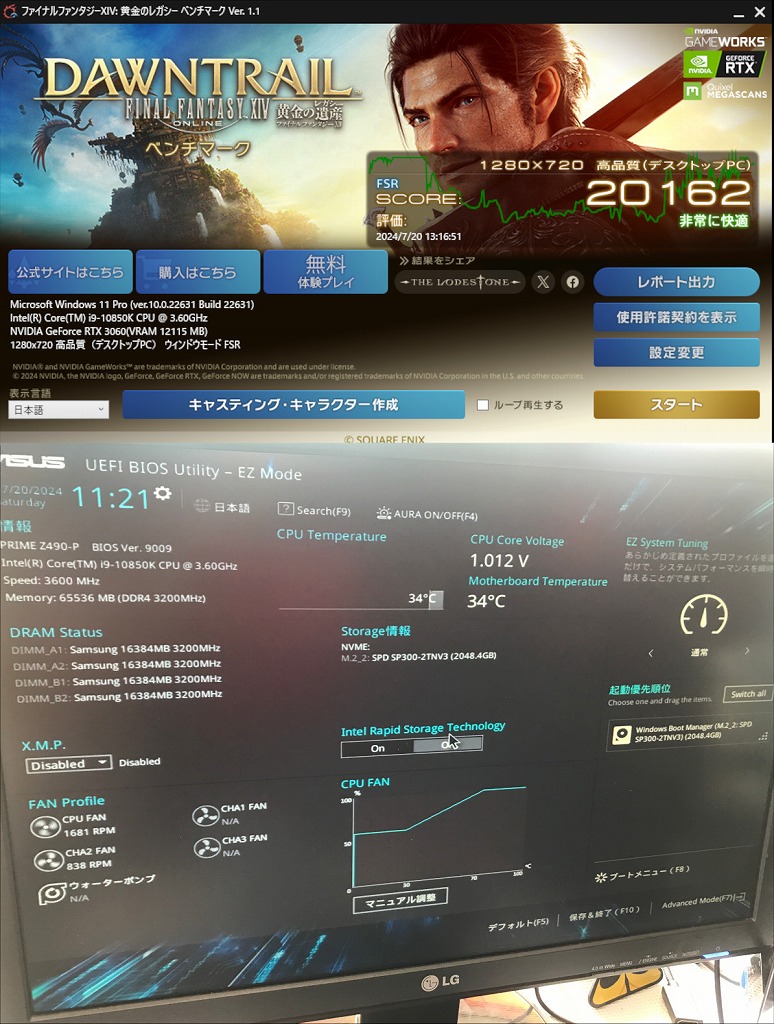
ベンチマーク:非常に快適
グラフィックボードは「NVIDIA GeForce RTX 3060 12GB(ZOTAC)」です。
※ZOTAC GeForce RTX 3060 12GB GDDR6 HDMI/DP*3
CPUは「Intel(R)?Core i9-9900KS?CPU @ 4.00GHz 4.00GHz」となります。
※ファン:前面、背面、上部などに設置済み(生成速度の低下を抑制します)
合計GPUメモリ28GB(生成する際に使用可能メモリ)
:専用GPUメモリ「12GB」、共有GPUメモリ「 16GB
」
訳アリ?
PCI-Express拡張カードを差し込むスロットの片方のツメが割れています。
PCIの留め具(ストッパー)が割れています(紛失しています)。
※留め具がなくても使用は可能であることを確認しました
※2つのうち一つが割れています。
写真グラボのように下のPCI-Express拡張カードは通常通りツメは割れていません。
訳アリ?
筐体の後ろの脚が歪んでいます。たぶん配送中に後ろ脚部分に力がかかり、少し歪んだと思われます。
調整・修正してみましたが、まだ少し歪みがみられます。
また、筐体などに多少傷などがみられます。
※詳細は、画像でご確認ください。
AI画像生成に興味を持たれている方もいるかと思い、出品するにあたり、
「Stable Diffusion WebUI」 と「Rope」「ReActor-UI」
を再構築しました。
ローカルPCなので、AI画像、スワップ動画などを無制限に生成することが可能です。
AI生成にご興味を持たれた方などは、ご検討いただけると有難いです。【交換部分】
・NVIDIA GeForce RTX 3060 12GB(ZOTAC)【中古】
・M.2 Kingston?NVMe 1TB【中古】×2
・SSD 1.0TB(Samsung SSD 870 EVO
1TB)【中古】
・TP-Link WiFi 無線LAN 子機 AC1300 867Mbps + 400Mbps?【新品】[外付けHDDについて]
・NGFF M.2 SSD 2TB
【新品】
・vigoole M.2 SSD SATA NGFF ケース? 外付けケース【新品】
※NVMeではありませんので、ご注意ください。
【スペック】
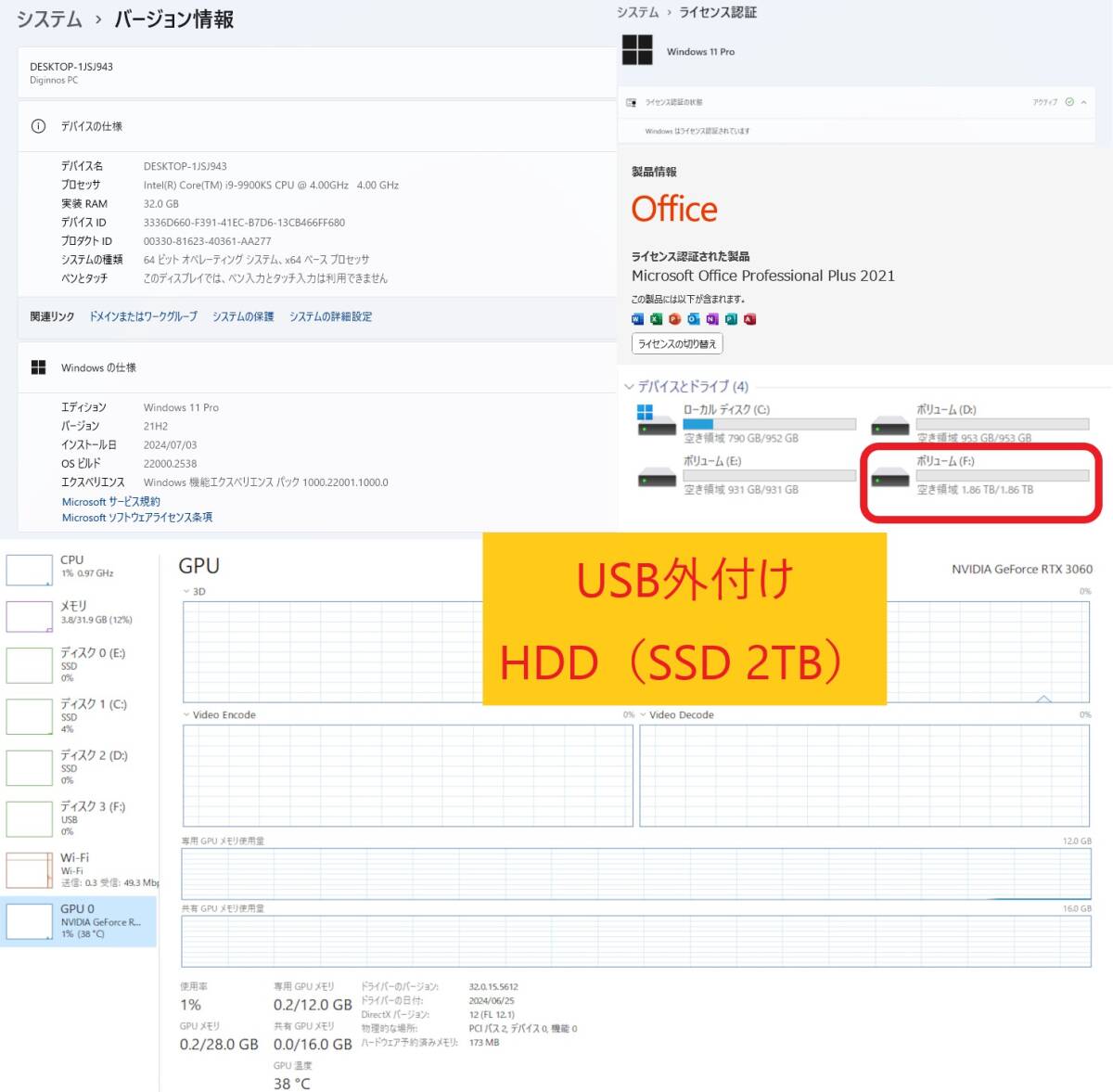
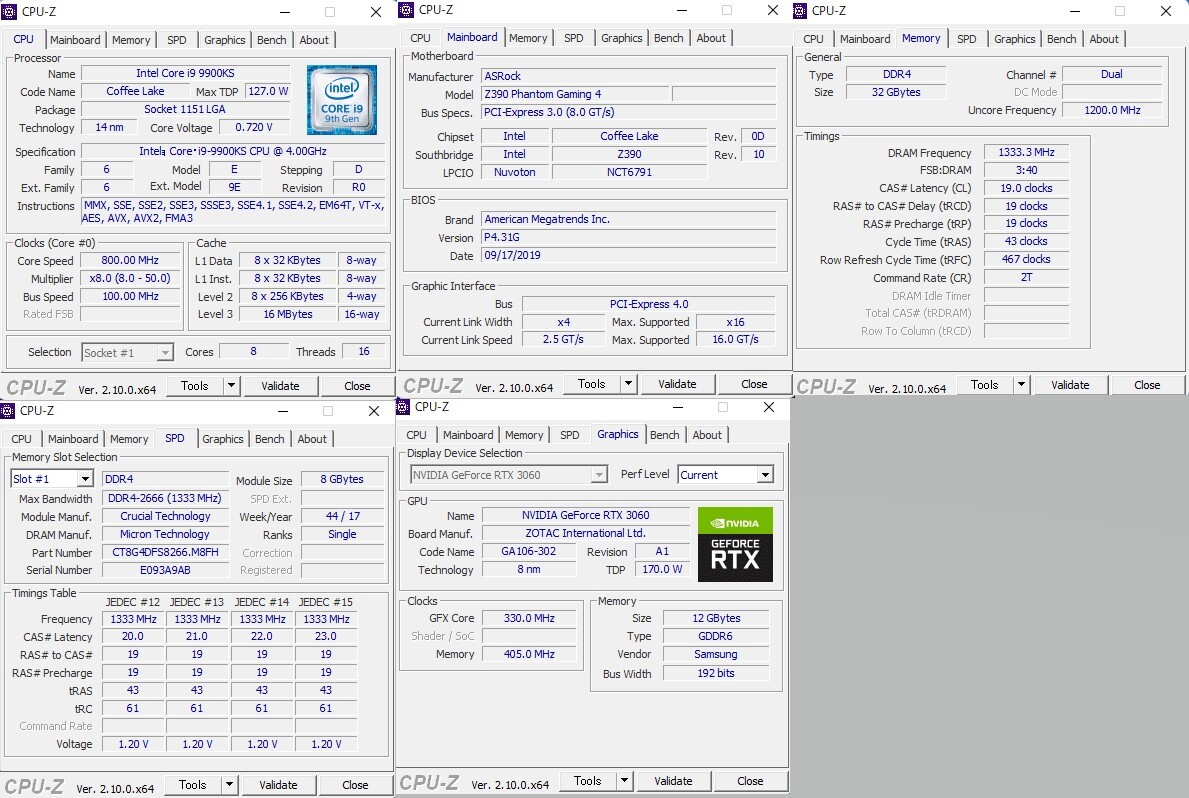
| OS | Windows11Pro |
| CPU | Intel(R) Core i9-9900KS CPU @ 4.00GHz 4.00GHz |
| メモリ | Crucial 32 GB (スロット:4/4) |
| グラフィック | NVIDIA GeForce RTX 3060 12GB(ZOTAC) |
| マザーボード | ASRock Z390 Phantom Gaming 4 |
| ストレージ1 | SSD(M.2) : 1TB ×2 / SSD:1TB / 外付けHDD(2TB) 【合計5TB】 |
| 電源ユニット | SilverStone 750W (80PLUS GOLD) |
| オフィスソフト | MicrosoftOffice2021Pro |
| ネットワーク | 有線〇/無線〇(TP-Link WiFi 無線LAN 子機 AC1300 867Mbps + 400Mbps (新品) ) |
【付属品】 本体と外付けHDD(M.2 SSD)、電源コードのみ となります。
筐体・マザーボードなどに不備はありますが、AI生成するパソコンとしてはスペックの高いパソコンとなります。
インテルは数世代前のCPUから、最高位モデルとして「KS」バージョンを用意しています。
生産したCPUの中から特に高速なものを選別したもので、通常はその世代のCPU発売後しばらくしてから、
限られた数量しか販売されないとのことです。
私もAI生成するパソコンにいろいろなCPUを試してみましたが、 「KS」バージョンが一番安定しています。
もしよろしければ、「KS」バージョンをご確認のうえ、ご検討いただけると有難いです。↓以下はおまけ程度にお考え下さいAI画像生成 設定済み
●Stable Diffusion WebUI(AI画像生成)
- Stable Diffusion WebUI?インストール済み
- CheckPoint インストール済み
- フォルダ内「webui-user.bat」ダブルクリックで起動
?すぐに、AI画像を生成できます!
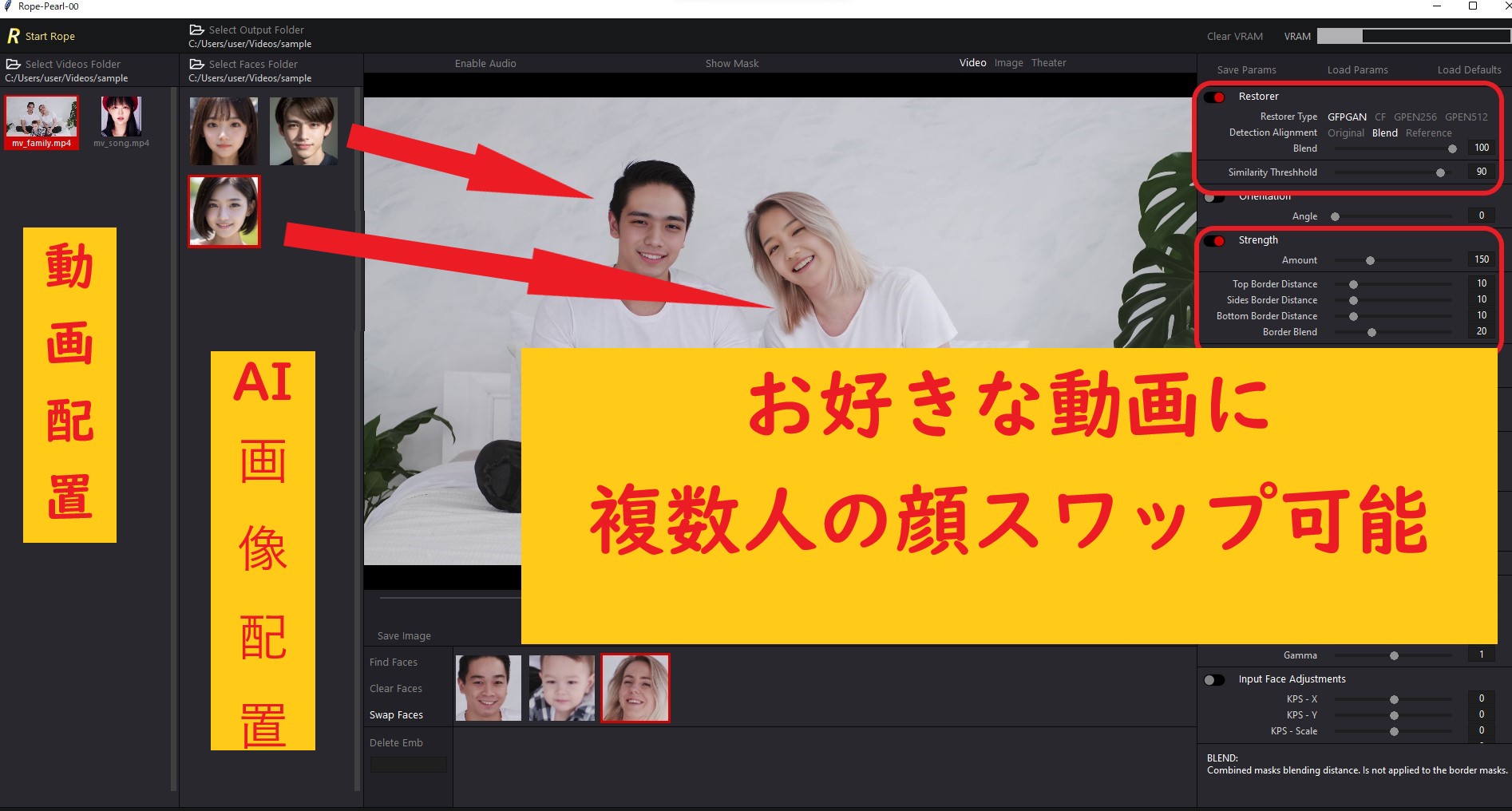
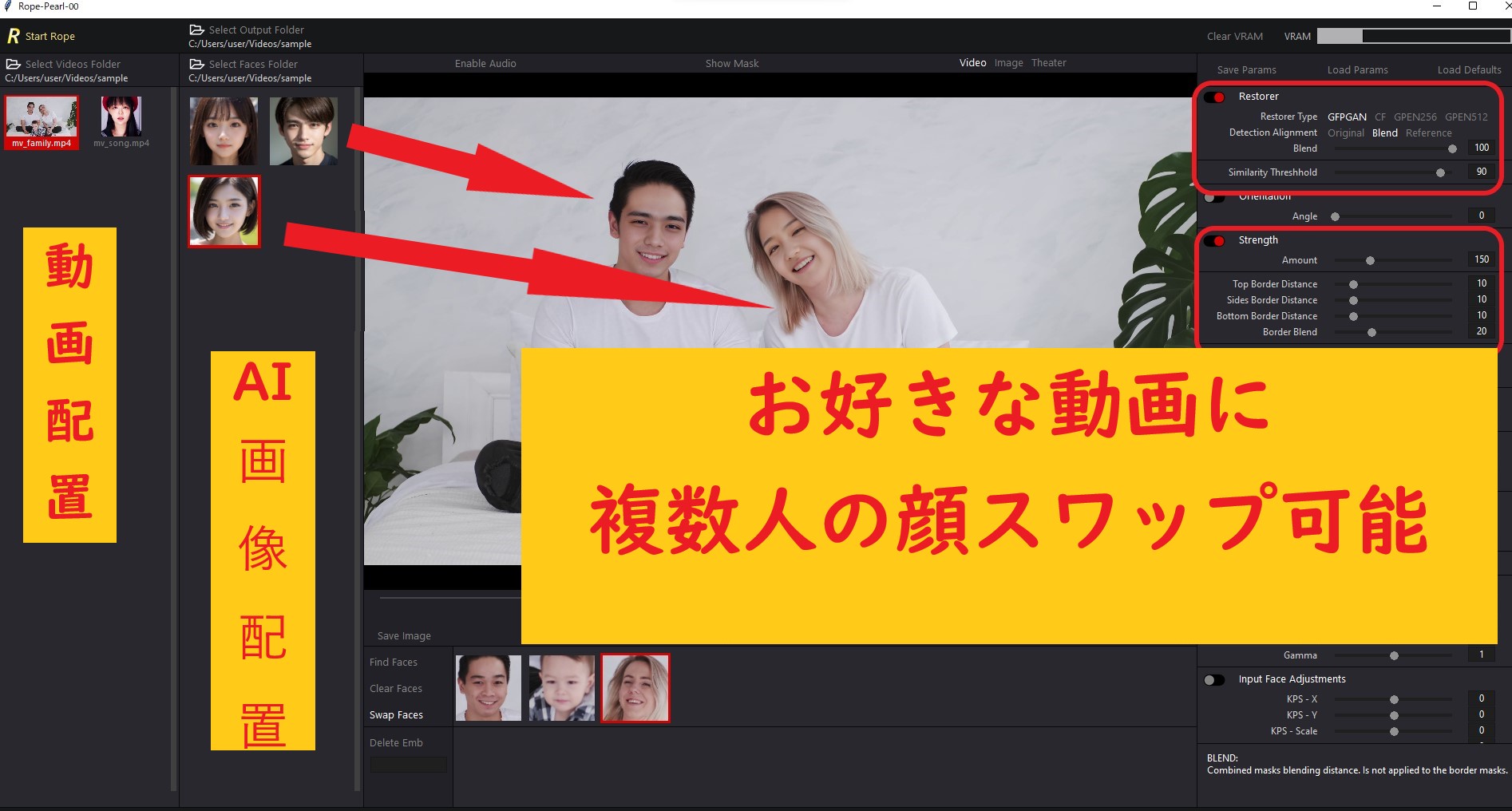
●Rope (ディープフェイク動画生成)
- 複数人の個別スワップ可能
- 動画と顔画像(AI画像)を準備すれば、新しい動画が生成可能
- フォルダ内「Rope_setup.bat」ダブルクリックで起動
●ReActor-UI (ディープフェイク動画生成)
- 動画と顔画像(AI画像)を準備すれば、新しい動画が生成可能
- フォルダ内「ReActor_setup.bat」ダブルクリックで起動
詳細は、「Stable Diffusion」「Rope」「ReActor-UI」で検索をお願いいたします。
AI生成/スワップ方法なども、検索などでご確認いただけるようにお願いいたします。
ご興味を持たれた方は、ご検討のほど、よろしくお願いいたします。
「Stable Diffusion WebUI」「DeepFake」をローカルPCに設定する時間がない方などにもお勧めかなと思います。
「Stable Diffusion WebUI」は1年以上活用していますが、いまだに楽しいです。
現在は、「Rope」を楽しんでいます。
30分程度の動画を用意し、生成したAI画像の顔に変更したりして楽しんでいます。
「Rope」は新しいスワップUIで、個別スワップが可能になった上に、精度の向上やUI機能も使いやすくなっています。

280,000円(在庫処分)
交換した部分
・NVIDIA GeForce RTX 3060 12GB(COLORFUL)【中古(綺麗美品)】
・PCI Express PCIe3.0 16xライザーケーブル
拡張ポートアダプタ【新品】
・M.2 2280 PCIe Gen3x4 NVMe2TB【新品】
・SSD M.2?2280?980pro NVMe 4TB【新品】
・TP-Link WiFi
無線LAN 子機 AC1300 867Mbps + 400Mbps 【新品】
パソコンスペック
| 筐体 | Thermaltake Core P3 TG オープンフレームPCケース CS7538 CA-1G4-00M1WN-06 ブラック |
| OS | Windows11 Pro |
| マザーボード | ASUS z490 |
| CPU | Intel(R) Core i9 10850K CPU @ 3.60GHz 3.60GHz |
| メモリ | SAMSUNG 64 GB (スロット:4/4) |
| グラフィック | COLORFUL iGame GEFORCE RTX 3060 Ultra W OC 12GB (綺麗美品) |
| ストレージ | M.2 2280 PCIe Gen3x4 NVMe2TB【新品】 M.2?2280?980pro NVMe 4TB【新品】 |
| オフィスソフト | Microsoft Office Pro 2021 |
| 電源ユニット | 750W 静音電源 (80PLUS GOLD) |
| ネットワーク | 有線〇/無線〇(TP-Link WiFi 無線LAN 子機 (新品)) |
ギャラリー








商品説明
【AI画像生成 設定済み】i9-10850k 64GB SSD:M.2(2TB&4TB) 合計6TB 美品綺麗:RTX3060(12GB) Win11 office2021
(※比較的美品?Thermaltake?ゲーミングPC)
交換・追加した部品
・NVIDIA GeForce RTX 3060 12GB(COLORFUL)【中古(綺麗美品)】
・PCI Express PCIe3.0 16xライザーケーブル
拡張ポートアダプタ【新品】
・M.2 2280 PCIe Gen3x4 NVMe2TB【新品】
・SSD M.2?2280?980pro NVMe 4TB【新品】
・TP-Link WiFi
無線LAN 子機 AC1300 867Mbps + 400Mbps 【新品】
AI画像生成 「Stable Diffusion WebUI」を生成するために自作パソコンを構築しました。
また、ディープフェイク動画生成する「Rope(最新)」「ReActor-UI」も構築しました。
ベンチマーク:非常に快適
グラフィックボードは「 NVIDIA GeForce RTX 3060 12GB(COLORFUL)(3連ファン) 」です。
CPUは「 Intel(R) Core i9 10850K CPU @ 3.60GHz 」となります。
CPUクーラー: Cooler Master MasterLiquid ML240L V2
RGB
オープンフレームPCケース となります。
※ファン:背面などに設置済み(生成速度の低下を抑制します)
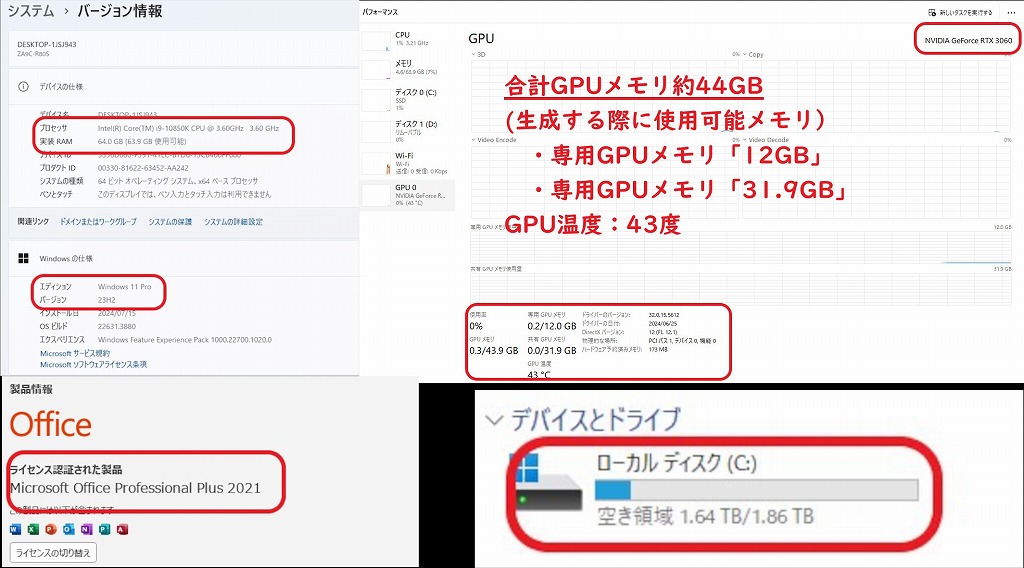
合計GPUメモリ約44GB(生成する際に使用可能メモリ):
・専用GPUメモリ「12GB」
・共有GPUメモリ「約32GB」
私見になりますが、パソコンはある程度綺麗に使用されていたように感じます。
※詳細は、画像でご確認ください。
AI画像生成に興味を持たれている方もいるかと思い、
「 Stable Diffusion WebUI 」 と「 Rope 」「 ReActor-UI 」
を再構築しました。
ローカルPCなので、AI画像、スワップ動画などを無制限に生成することが可能です。
AI生成にご興味を持たれた方などは、ご検討いただけると有難いです。
ローカルPCでAI画像を生成したい方へ
AI画像を生成するためには、高スペックなパソコンが必要です。
最小スペックでも15万円以上のパソコンが必要となります。
※特にグラフィックボード(GPU)
私もはじめは最小スペックでAI画像を生成していました。
しかし、生成時間があまりにもかかるので、少しずつですがスペックを上げていきました。
高スペックにすればするほど、生成時間も短縮され、AI画像を生成することが楽しくなりました。
AI画像生成に興味を持たれた方は、まずは以下のサイトをご覧ください。
AI画像生成 設定済み
●Stable Diffusion WebUI(AI画像生成)
- Stable Diffusion WebUI インストール済み
- CheckPoint インストール済み
- フォルダ内「 webui-user.bat 」ダブルクリックで起動
すぐに、AI画像を生成できます!
●Rope (ディープフェイク動画生成:複数人個別スワップ可)※新スワップUI
- 元動画データ と 変更したい各顔画像 を準備すれば、新しい動画が生成可能
- フォルダ内「 Rope_setup.bat 」ダブルクリックで起動
●ReActor-UI (ディープフェイク動画生成)
- 元動画データ と 変更したい顔画像 を準備すれば、新しい動画が生成可能
- フォルダ内「 ReActor_setup.bat 」ダブルクリックで起動
●roop (ディープフェイク動画生成)
- 元動画データ と 変更したい顔画像 を準備すれば、新しい動画が生成可能
- フォルダ内「 roop_setup.bat 」ダブルクリックで起動
詳細は、「Stable Diffusion」「Rope」「ReActor-UI」で検索をお願いいたします。
AI生成/スワップ方法なども、検索などでご確認いただけるようにお願いいたします。
すぐに、AI画像を生成できます!
「 Stable Diffusion WebUI 」と「 ReActor-UI 」の生成方法
「 Rope 」の生成方法
料金
税込 280,000円 (※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

完売しました。
新品に近く、状態もかなり良く、大変喜ばれました。
これからも、良いものを安くお届けできるように精進していきたいと思います。
79200円 → 72000 円(※在庫処分)
中古品/第7世代i7/メモリ16GB/Webカメラ/Office/Win11
ギャラリー








説明
Intel Core i7プロセッサー&メモリ16GB搭載で、動作も快適♪
ハードディスクも新品1TB(1000GB)SSDへ換装済み!
天板などに傷があります。
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
使用感も少なく、美品に思います。
| 状態 | 中古品 |
|---|---|
| パソコンメーカー | TOSHIBA |
| 型番 | Dynabook T65/EG |
| カラー | サテンゴールド |
| CPU | Intel Core i7 7500U 2.70GHz |
| メモリ | 16 GB |
| ストレージ | SSD 1TB(1000 GB)【新品】 |
| 表示能力 | 15.6 インチ |
| 解像度 | 1366×768 |
| OS | Windows 11 Home 64 bit |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | DVDスーパーマルチ |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB: 3.0x2個 2.0x2個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル |
料金
税込 79200円 (税抜72000円)→ 72000 円(※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

はじめに
パソコンが遅くなった方はいませんか?
今お持ちのパソコンがSSDに換装することにより起動時間が速くなります。
なおかつ、パソコン内のデータ、WiFi設定、プリンタ設定なども現在のまま維持されます。
SSD換装後の状態
なにかありましたら、お気軽にご相談ください。