ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
現在データベースには 492 件のデータが登録されています。
坂東市長選挙告示 現職の木村敏文氏 無投票で3選|NHK 首都圏のニュース
【NHK】任期満了に伴う茨城県坂東市の市長選挙が16日告示され、現職の木村敏文氏のほかに立候補の届け出はなく、無投票で3回目の当選を果たしました。 …

任期満了に伴う茨城県坂東市の市長選挙が16日告示され、現職の木村敏文氏のほかに立候補の届け出はなく、無投票で3回目の当選を果たしました。
坂東市長選挙は16日午後5時で、立候補の受け付けが締め切られ、現職の木村敏文氏のほかに立候補の届け出はなく、無投票で3回目の当選を果たしました。
木村氏は69歳。
合併前の旧猿島町の町議会議員や坂東市の市議会議員を経て、8年前の市長選挙で初当選しました。
坂東市は人口およそ5万2000人。
少子高齢化が進む中子育て支援の充実や、圏央道を生かした産業の誘致などが課題となっています。
木村氏は「持続可能なまちづくりをするために、企業誘致や子育ての充実などの実績をもとに政策をさらに前に進めていきたい」と話しています。
出陣式・当選報告会動画
・木村敏文 出陣式
・木村敏文 当選報告会
54000円 → 45000 円(※在庫処分)
ギャラリー




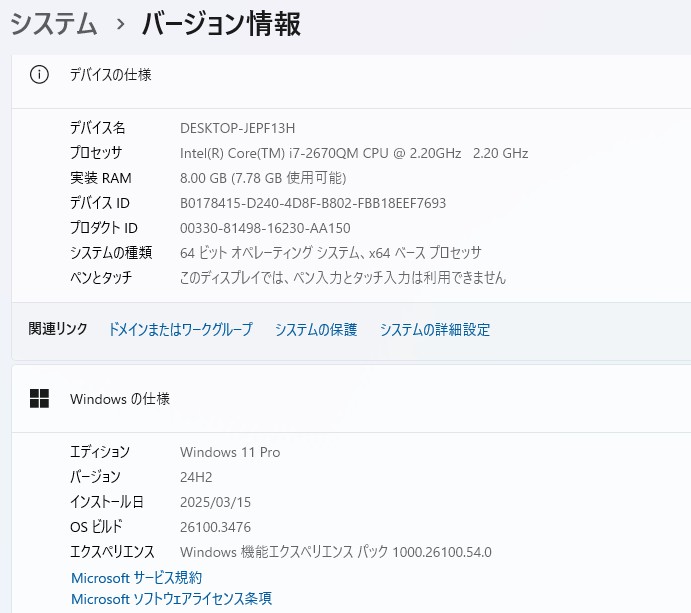

Intel Core i7プロセッサー&メモリ8GB&SSD?512GB 【新品】搭載で、動作も快適♪
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
経年劣化などの使用感はあります。
| 状態 | 中古品 |
|---|---|
| パソコンメーカー | 富士通 |
| 型番 | FMV LIFEBOOK AH77/E |
| CPU | Core i7 2670QM |
| メモリ | 8 GB |
| ストレージ | SSD?512GB 【新品】 |
| 表示能力 | 15.6 インチ |
| 解像度 | 1366×768 |
| OS | Windows 11 Pro 64 bit |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | BD/DVDスーパーマルチ |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | HDMI端子 USB3.0 VGA端子 |
| 内蔵機能 | WEBカメラ / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル |
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
CM動画
居酒屋 みやべ屋
〒306-0632
茨城県坂東市辺田1501-3
居心地の良いアットホームな雰囲気の居酒屋づくりに力を入れ、お客様には肩の荷を下ろして、お食事やお酒を楽しんでいただけるような空間の提供に取り組んでおります。和食から洋食、韓国料理まで幅広いメニューを取り揃えており、お酒に苦手意識がある方やハンドルキーパーの方などにもご利用いただけるよう、ドリンクバーも用意しています。
坂東でお子様連れの方も歓迎し、ご家族揃ってのご利用にも適したメニューを取り揃えております。個室のようにリラックスできる暖簾で区切られた空間で、思い思いのひと時を満喫してみませんか。
LINE Creators Market
スタンプ完成
男の子
スタンプ販売
スタンプ作者URL: https://line.me/S/shop/sticker/author/5208854
スタイリッシュな男の子 ケン

不同意性交などの問題が発生しています。前もって 同意確認 をお互いにすることをお勧めします!
LINE Creators Market
スタンプ完成
男の子

女の子

スタンプ販売
スタンプ作者URL: https://line.me/S/shop/sticker/author/5208854
スタイリッシュな男の子 ケン

スタイリッシュな女の子 ニナ

観光交流センター秀緑
坂東市の市街地に位置する「酒造跡地」において、明治28年建造の本蔵を代表とした歴史的建造物群と緑豊かな景観を活かし、体験型のガラス、陶芸、木工工房や、多目的ホール、文化歴史観光案内所等の「リノベーション複合施設」として誕生しました。
なお、本蔵および主屋については文化庁の登録有形文化財に指定された貴重な建物となっております。

日本酒「秀緑」
坂東市の日本酒!
華やかな香り、フレッシュな味わいのお酒です。

日本酒秀緑 | 観光交流センター秀緑
坂東の米で醸す日本酒 「秀緑」「将門」「勘助新田」など多くの銘柄と幅広い味で親しまれた大塚酒造は、世の嗜好の変化、人材確保など様々な理由が重なった結果、平成23…
PR動画
モデル
FluxesCore-Dev
FluxesCore-Dev - V1.0 - bnb-nf4 | Flux Checkpoint | Civitai
If you like my work, please consider supporting me ! For more information, please visit Patreon ! Overview FluxesCore-Dev series models are fine-tu...
プロンプト・AI生成画像
- 都会的で洗練されたポートレート
???? プロンプト:
"A high-resolution photograph of a cute Japanese teenage girl with fair skin and dark brown eyes, posing elegantly in an urban
setting at dusk. She wears a stylish beige trench coat over a white blouse, her soft brown hair gently swaying in the evening breeze. The neon lights of Shibuya
softly illuminate her face, creating a cinematic and modern cityscape background. The photo has a shallow depth of field, emphasizing her natural beauty with a
bokeh effect. Ultra-realistic lighting and high-quality details."


- ナチュラルな朝の光の中で
???? プロンプト:
"A hyper-realistic close-up portrait of a cute Japanese teenage girl in a sunlit bedroom. She sits by a window, wearing a cozy
pastel-colored sweater, her long black hair slightly tousled. The golden morning light softly touches her face, highlighting her delicate features. She looks
directly into the camera with a gentle, serene expression. The background is blurred, showing warm, neutral tones, emphasizing a natural and candid moment.
High-quality, professional photography with soft-focus and beautiful skin texture."


- カフェでのリラックスしたひととき
???? プロンプト:
"A high-definition photograph of a young Japanese teenage girl in a cozy café, sipping a latte while looking out the window with
a gentle smile. She wears a casual yet fashionable outfit, a white oversized sweater paired with a pleated skirt. The warm glow of hanging lights and the
blurred background of a trendy Tokyo café create a dreamy, cinematic atmosphere. The reflection of city life outside adds realism, making the image feel like a
magazine cover. Ultra-detailed skin texture and natural soft lighting enhance the authenticity."


- 学校帰りの爽やかな一瞬
???? プロンプト:
"A professional studio-quality photograph of a cheerful Japanese teenage girl in a classic high school uniform, walking home on a
sunny afternoon. She carries a school bag over her shoulder and smiles brightly at the camera. Her jet-black hair is neatly tied in a ponytail, slightly swaying
with her movement. The golden-hour sunlight filters through the trees, casting a soft, warm glow on her face. The background is slightly blurred, showing a
quiet suburban street. Ultra-sharp details with cinematic depth of field make it look like a fashion magazine cover."


- 夏祭りでの幻想的なポートレート
???? プロンプト:
"A stunningly realistic nighttime photograph of a cute Japanese teenage girl at a summer festival, wearing a pastel-colored yukata
with delicate floral patterns. She holds a glowing paper lantern in one hand and gazes into the camera with a soft smile. Fireworks light up the night sky in
the background, creating a dreamy bokeh effect. Her dark brown eyes reflect the warm festival lights, and her silky black hair is elegantly styled with
traditional hairpins. The soft-focus background captures the lively festival atmosphere, emphasizing her ethereal beauty. Ultra-HD details with cinematic
lighting."


ポイント:
すべて写真であることを強調するため、"photograph," "hyper-realistic," "studio-quality," "ultra-HD"
などのワードを使用。
日本らしい日常のシーン(都市、カフェ、学校、夏祭り)を盛り込み、リアリティを向上。
カメラ技法(シャロー・デプス・オブ・フィールド、ボケ、シネマティック・ライティング)を意識。