ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
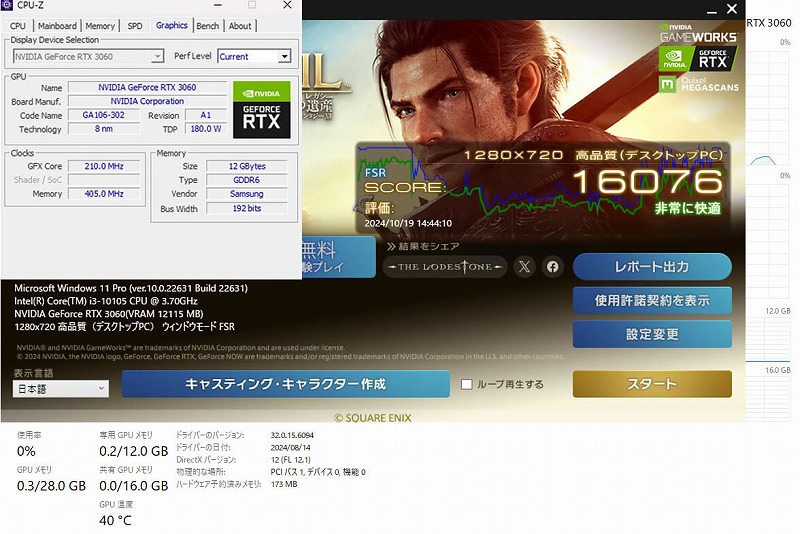
現在データベースには 492 件のデータが登録されています。
248000円
ギャラリー




(※ゲーミングPC AI生成PC)
【ベンチマーク】非常に快適
【スペック】
筐体 OMEN
シリーズ OMEN
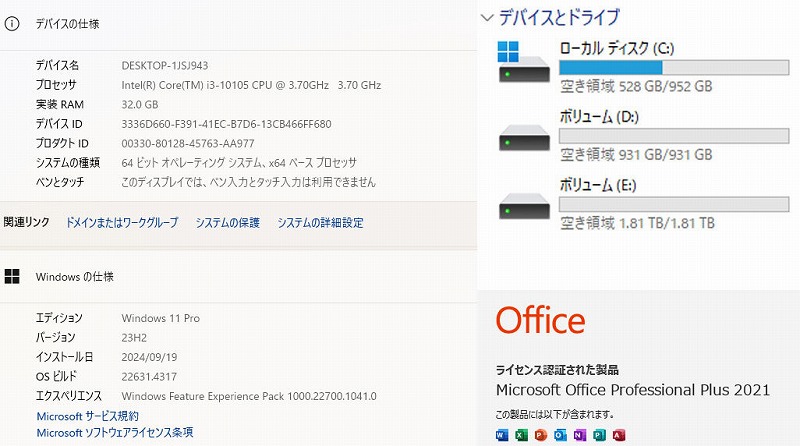
OS Windows11Pro
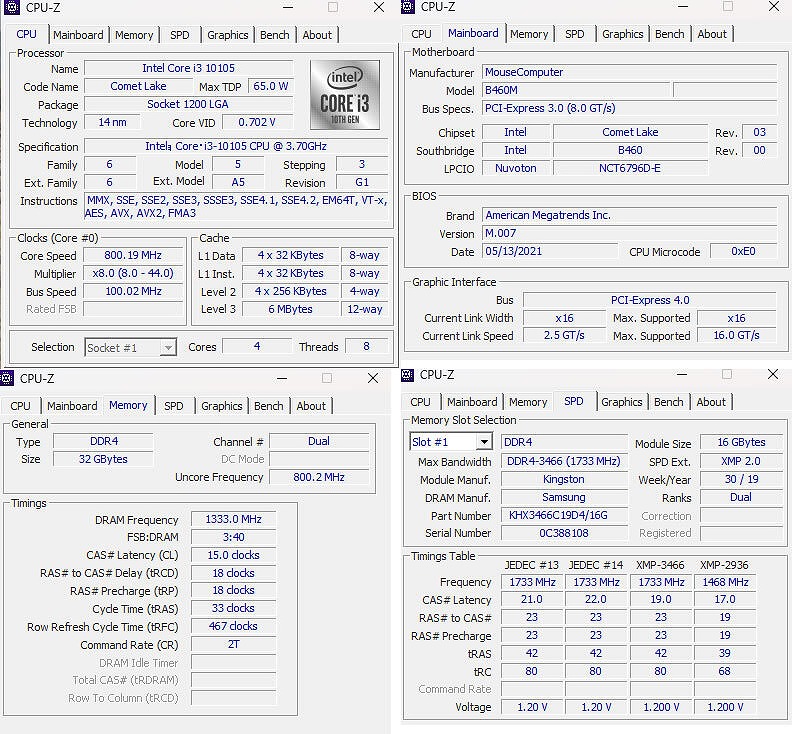
CPU Intel(R) Core i3-10105 @ 3.70GHz
メモリ Kingston DDR4 16GB×2 (32GB)
(スロット:2/2)
グラフィック palit GeForce RTX3060 12GB
マザーボード MouseComputer B460M (CPUSocket)
CPUクーラー
水冷CPUクーラー
電源ユニット HP L84096-003 750W
オフィスソフト MicrosoftOffice2021Pro
ネットワーク 有線〇/無線〇
ストレージ
SSD(M.2): 1TB(INTEL 660p SERIES)
HDD: 1TB(TOSHIBA DT01ACA100)
HDD: 2TB(WD WD20EFRX)
グラフィック
RTX3060 DUAL OC 12GB GDDR6 192bit 3-DP HDMI(中古美品)
ケース
ケースのみOMEN 30L
※ファン:背面、前面、上面などに複数設置済み(生成速度の低下を抑制します)
合計GPUメモリ約28GB(生成する際に使用可能メモリ)
:専用GPUメモリ「12GB」、共有GPUメモリ「16GB」
私見になりますが、パソコンはある程度綺麗に使用されていたように感じます。
※詳細は、画像でご確認ください。
【付属品】?本体、電源コード、空き箱(写真参照)
となります。
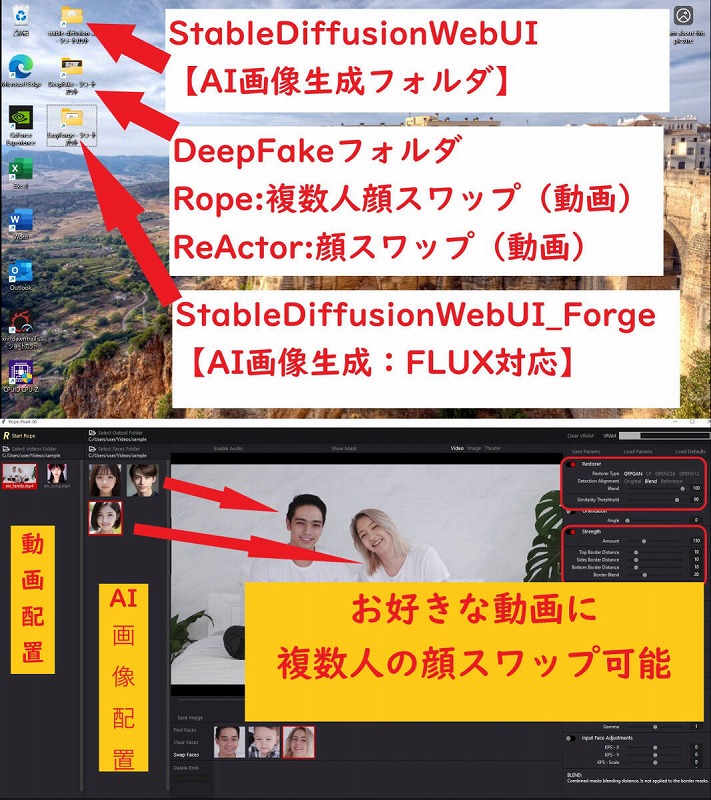
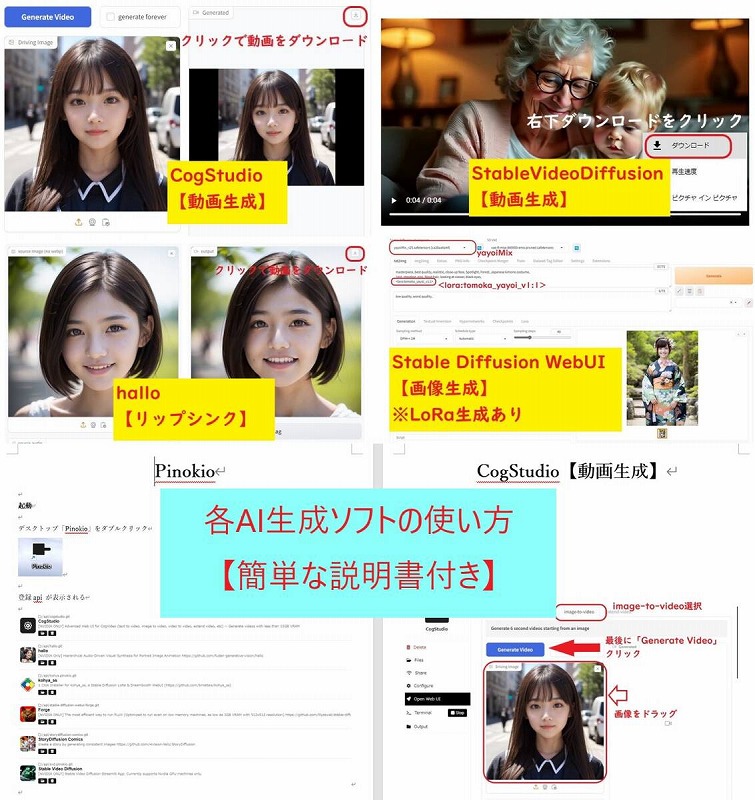
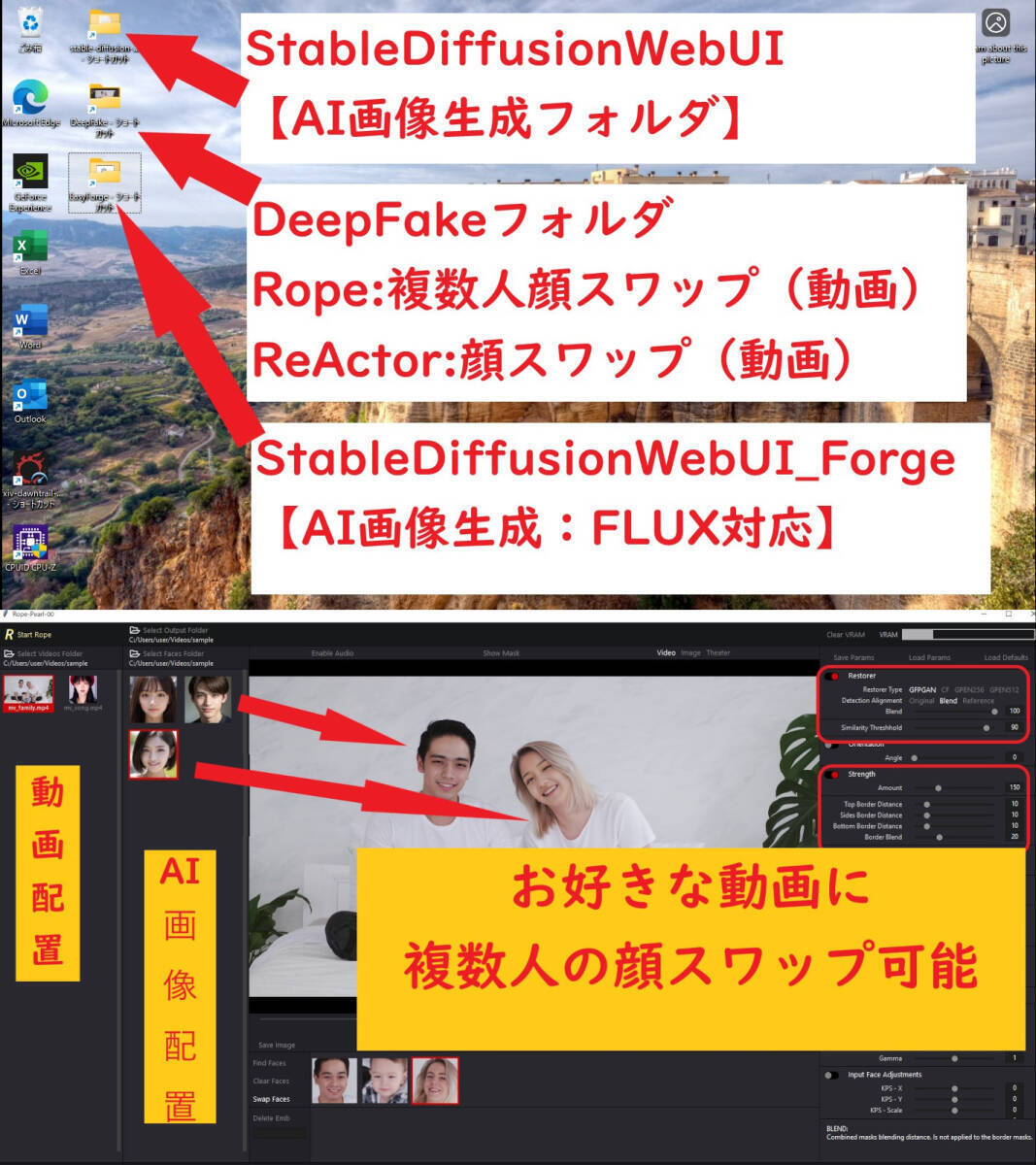
AI画像生成
・WebUI Forge
・Stable Diffusion WebUI
AI顔スワップ動画生成
・Rope
・ReActor-UI
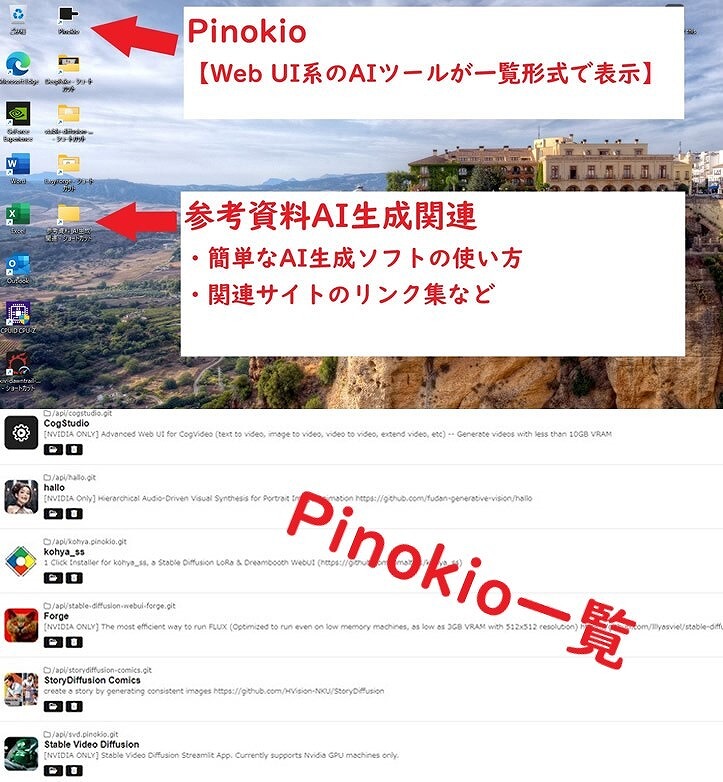
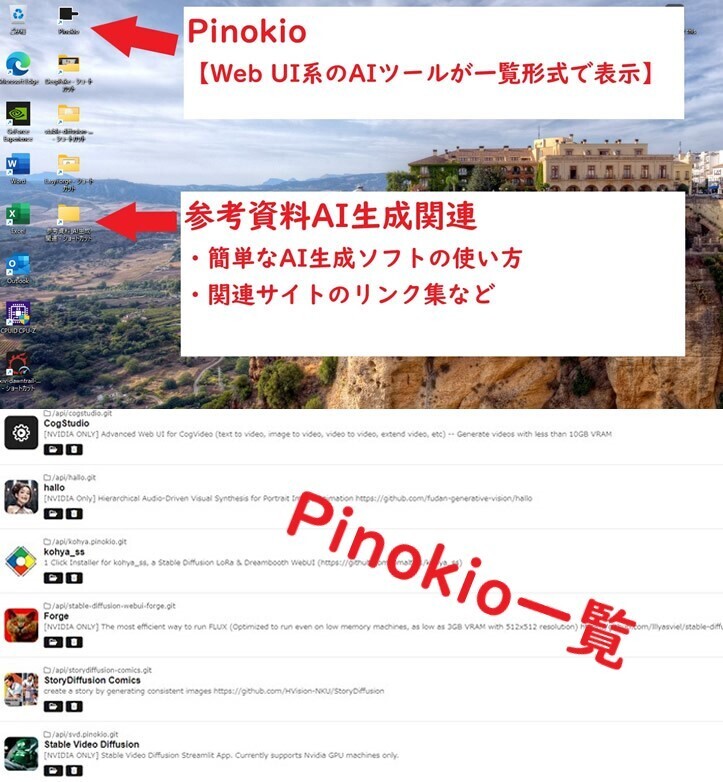
Pinokio【AIツール一覧】
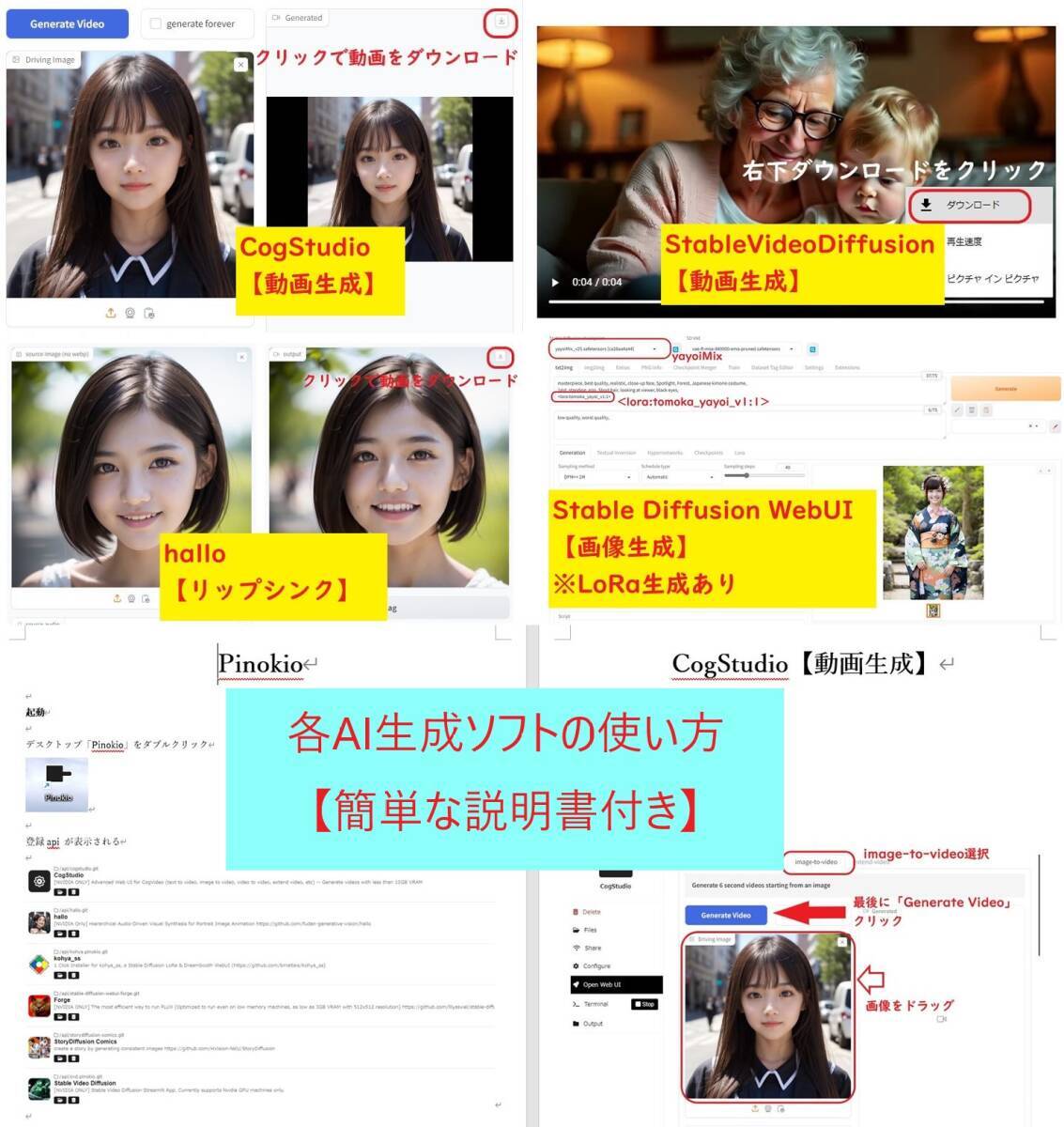
・CogStudio 【動画生成】
・Hallo 【リップシンク】
・Forge 【画像生成(FLUX)】
・Story Diffusion
comics 【漫画生成】
・Stable Video Diffusion 【動画生成】
・Kohya_ss 【LoRa生成】
を再構築しました。
ローカルPCなので、AI画像、スワップ動画などを無制限に生成することが可能です。
AI生成にご興味を持たれた方などは、ご検討いただけると有難いです。
↓以下はおまけ程度にお考え下さい
AI画像生成 設定済み
●WebUI Forge(AI画像生成)
WebUI Forgeインストール済み
最新AI画像生成「FLUX.1」を生成可能
高解像度化を生成してみたい方はこちらをお試しください。
フォルダ内「Forge-user.bat」ダブルクリックで起動
すぐに、AI画像を生成できます!
●Stable Diffusion WebUI(AI画像生成)
Stable Diffusion WebUI インストール済み
CheckPoint インストール済み
フォルダ内「webui-user.bat」ダブルクリックで起動
すぐに、AI画像を生成できます!
いろいろな画風を楽しみたい方は、LoRAが豊富なこちらをご活用ください。
●Rope (ディープフェイク動画生成:複数人個別スワップ可)
・お好きな動画をご用意
・AIなどで顔画像をご用意
・複数人の顔スワップが可能元動画データと変更したい各スワップ顔画像を準備すれば、新しい動画が生成可能 ←おすすめ!
お好きな動画の人物を変更すること(顔スワップ)が可能です。
フォルダ内「Rope_setup.bat」ダブルクリックで起動
●ReActor-UI (ディープフェイク動画生成)
元動画データと変更したいスワップ顔画像を準備すれば、新しい動画が生成可能
フォルダ内「ReActor_setup.bat」ダブルクリックで起動
詳細は、「WebUI Forge」「Stable Diffusion」「Rope」「ReActor-UI」で検索をお願いいたします。
AI生成/スワップ方法なども、検索などでご確認いただけるようにお願いいたします。
●Pinokio(AIツールの一覧)
AIツールをまとめた「 Pinokio 」を導入しました。
いろいろなAI生成ツールを「Pinokio」で管理・操作ができます。
・CogStudio 【動画生成】
・Hallo 【リップシンク】
・Forge 【画像生成(FLUX)】
・Story Diffusion
comics 【漫画生成】
・Stable Video Diffusion 【動画生成】
・Kohya_ss 【LoRa生成】
※目的の人物などの画像を20枚程度からLoRaを生成可能
※StableDiffusionWebUIで目的の人物AI画像を生成可能
●参考資料(AI生成関連)
各AI生成ソフトごとに、簡単な操作方法を記述した説明書を制作しました 参考となるサイトを各フォルダごとに追加
簡単ではありますが、もしよろしければ、ご活用ください。
ご興味を持たれた方は、ご検討のほど、よろしくお願いいたします。
ローカルPCに設定する時間がない方などにもお勧めかなと思います。「 Stable Diffusion WebUI
」は1年以上活用していますが、いまだに楽しいです。「 Rope
」は新しいスワップUIで、複数人の個別顔スワップが可能になった上に、精度の向上やUI機能も使いやすくなっています。
8月より話題の画像生成AI「 FLUX.1 」もローカルPCで楽しめるようになりました。
AI画像生成の能力は、以前より格段に高くなりました。
AI画像か写真か、見分けがつかない画像も生成できました。
「 Pinokio
」でAI動画も生成可能となりました。AI画像を生成した後にご活用ください。
「 Kohya_ss
」もインストールしておきました。
※簡単ではありますが、使用方法も説明書に追加しておきました。
LoRaを作成できるので、お好きな人物のAI画像も生成可能となっております。
詳細は、画像でご確認ください。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
268000円
ギャラリー




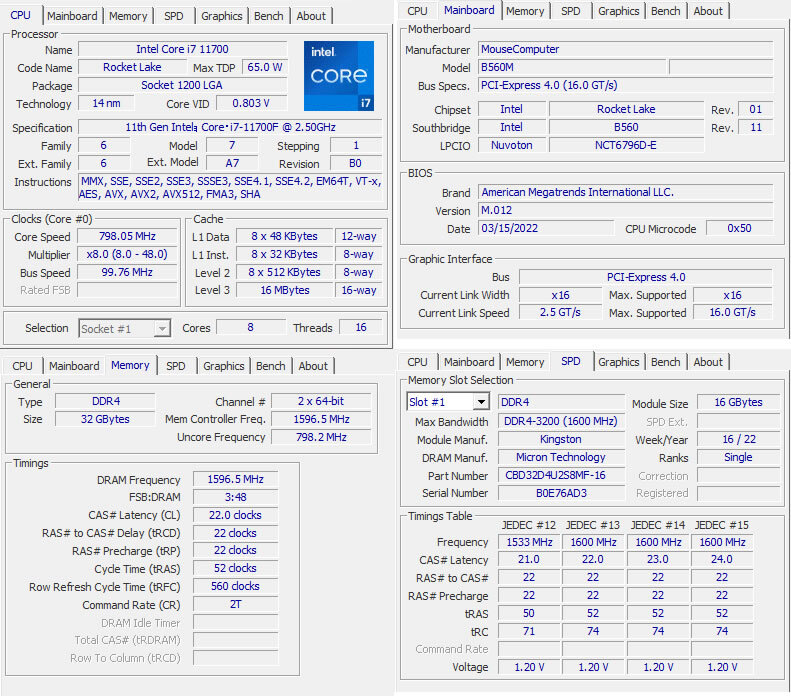
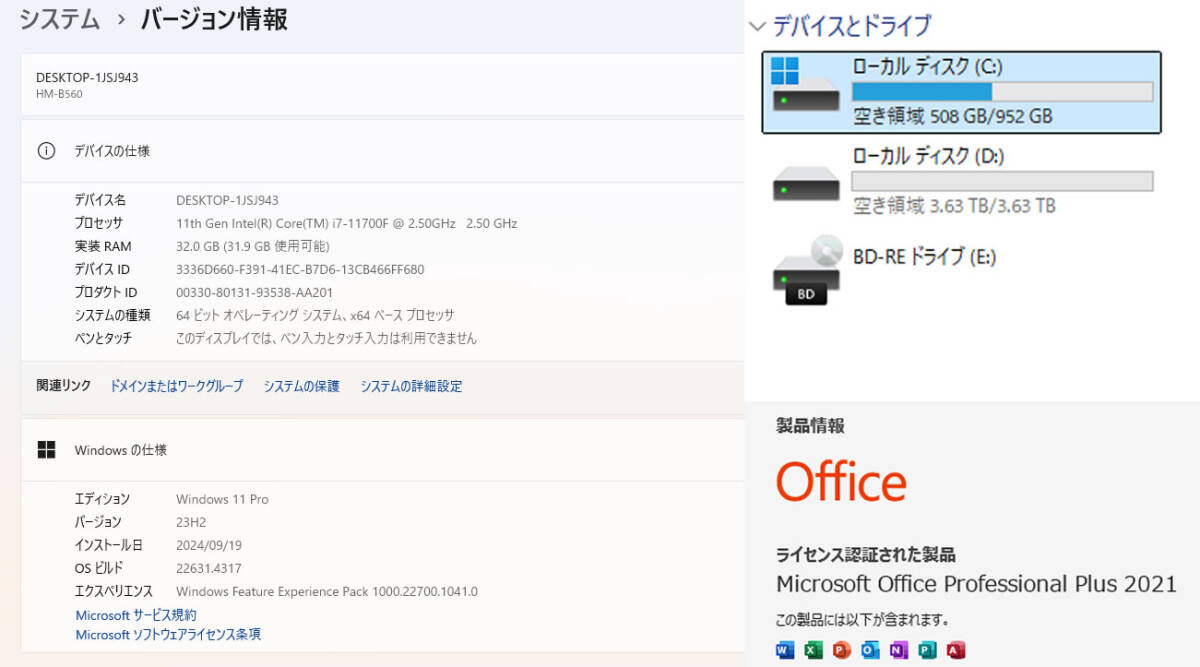
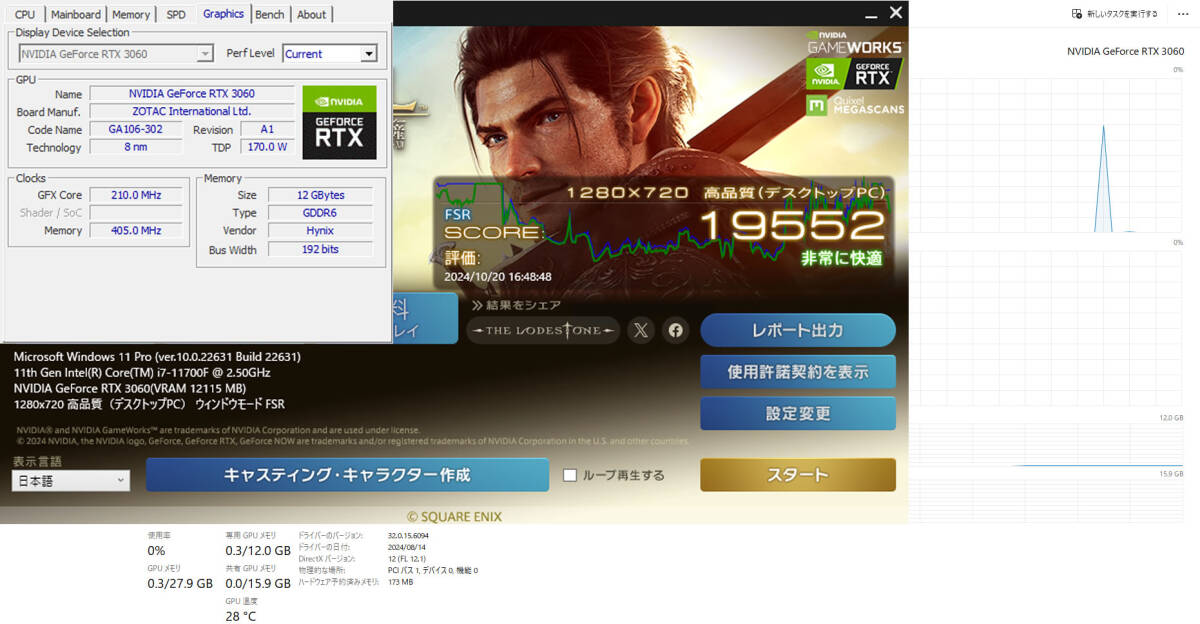
(※ゲーミングPC AI生成PC)
【ベンチマーク】非常に快適
【スペック】
筐体 Mouse
シリーズ GTUNE
OS Windows11Pro
CPU Intel(R) Core i7-11700F @ 2.50GHz
メモリ Kingston DDR4 16GB×2 (32GB)
(スロット:2/2)
グラフィック ZOTAC GeForce RTX3060 12GB
マザーボード MouseComputer B560
CPUクーラー 水冷CPUクーラー
電源ユニット FSP 750A-SAG1 750W
オフィスソフト MicrosoftOffice2021Pro
ネットワーク 有線〇/無線〇
ストレージ
SSD(M.2): 1TB(ORICO J-10) 【新品】
HDD: 4TB(WD WD40EZAZ)
グラフィック
ZOTAC GeForce RTX3060 12GB GDDR6 HDMI/DP*3(中古美品)
※ファン:背面、前面(2箇所)などに複数設置済み(生成速度の低下を抑制します)合計GPUメモリ約28GB(生成する際に使用可能メモリ)
:専用GPUメモリ「12GB」、共有GPUメモリ「約16GB」
私見になりますが、パソコンは綺麗に使用されていたように感じます。
※詳細は、画像でご確認ください。
【付属品】?本体、電源コード
となります。
AI画像生成
?・WebUI Forge
?・Stable Diffusion WebUI
AI顔スワップ動画生成
?・Rope
?・ReActor-UI
Pinokio【AIツール一覧】
・CogStudio 【動画生成】
・Hallo 【リップシンク】
・Forge 【画像生成(FLUX)】
・Story Diffusion
comics 【漫画生成】
・Stable Video Diffusion 【動画生成】
・Kohya_ss 【LoRa生成】
を再構築しました。
ローカルPCなので、AI画像、スワップ動画などを無制限に生成することが可能です。
AI生成にご興味を持たれた方などは、ご検討いただけると有難いです。
↓以下はおまけ程度にお考え下さい
AI画像生成 設定済み
●WebUI Forge(AI画像生成)
WebUI Forgeインストール済み
最新AI画像生成「FLUX.1」を生成可能
高解像度化を生成してみたい方はこちらをお試しください。
フォルダ内「Forge-user.bat」ダブルクリックで起動
?すぐに、AI画像を生成できます!
●Stable Diffusion WebUI(AI画像生成)
Stable Diffusion WebUI インストール済み
CheckPoint インストール済み
フォルダ内「webui-user.bat」ダブルクリックで起動
?すぐに、AI画像を生成できます!
いろいろな画風を楽しみたい方は、LoRAが豊富なこちらをご活用ください。
●Rope (ディープフェイク動画生成:複数人個別スワップ可)
・お好きな動画をご用意
・AIなどで顔画像をご用意
・複数人の顔スワップが可能元動画データと変更したい各スワップ顔画像を準備すれば、新しい動画が生成可能?←おすすめ!
お好きな動画の人物を変更すること(顔スワップ)が可能です。
フォルダ内「Rope_setup.bat」ダブルクリックで起動
●ReActor-UI (ディープフェイク動画生成)
元動画データと変更したいスワップ顔画像を準備すれば、新しい動画が生成可能
フォルダ内「ReActor_setup.bat」ダブルクリックで起動
詳細は、「WebUI Forge」「Stable Diffusion」「Rope」「ReActor-UI」で検索をお願いいたします。
AI生成/スワップ方法なども、検索などでご確認いただけるようにお願いいたします。
●Pinokio(AIツールの一覧)
AIツールをまとめた「 Pinokio 」を導入しました。
いろいろなAI生成ツールを「Pinokio」で管理・操作ができます。
・CogStudio 【動画生成】
・Hallo 【リップシンク】
・Forge 【画像生成(FLUX)】
・Story Diffusion
comics 【漫画生成】
・Stable Video Diffusion 【動画生成】
・Kohya_ss 【LoRa生成】
?※目的の人物などの画像を20枚程度からLoRaを生成可能
?※StableDiffusionWebUIで目的の人物AI画像を生成可能
●参考資料(AI生成関連)?
各AI生成ソフトごとに、簡単な操作方法を記述した説明書を制作しました?参考となるサイトを各フォルダごとに追加
?簡単ではありますが、もしよろしければ、ご活用ください。
ご興味を持たれた方は、ご検討のほど、よろしくお願いいたします。
ローカルPCに設定する時間がない方などにもお勧めかなと思います。「 Stable Diffusion WebUI
」は1年以上活用していますが、いまだに楽しいです。「 Rope
」は新しいスワップUIで、複数人の個別顔スワップが可能になった上に、精度の向上やUI機能も使いやすくなっています。
8月より話題の画像生成AI「 FLUX.1 」もローカルPCで楽しめるようになりました。
AI画像生成の能力は、以前より格段に高くなりました。
AI画像か写真か、見分けがつかない画像も生成できました。
「 Pinokio
」でAI動画も生成可能となりました。AI画像を生成した後にご活用ください。
「 Kohya_ss
」もインストールしておきました。
※簡単ではありますが、使用方法も説明書に追加しておきました。
LoRaを作成できるので、お好きな人物のAI画像も生成可能となっております。
詳細は、画像でご確認ください。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
268000円
ギャラリー
(※ゲーミングPC AI生成PC)
【ベンチマーク】非常に快適
【スペック】
筐体 Mouse
シリーズ GTUNE
OS Windows11Pro
CPU Intel(R) Core i7-11700F @ 2.50GHz
メモリ Kingston DDR4 16GB×2 (32GB)
(スロット:2/2)
グラフィック ZOTAC GeForce RTX3060 12GB
マザーボード MouseComputer B560
CPUクーラー 水冷CPUクーラー
電源ユニット FSP 750A-SAG1 750W
オフィスソフト MicrosoftOffice2021Pro
ネットワーク 有線〇/無線〇
ストレージ
SSD(M.2): 1TB(ORICO J-10) 【新品】
HDD: 4TB(WD WD40EZAZ)
グラフィック
ZOTAC GeForce RTX3060 12GB GDDR6 HDMI/DP*3(中古美品)
※ファン:背面、前面(2箇所)などに複数設置済み(生成速度の低下を抑制します)合計GPUメモリ約28GB(生成する際に使用可能メモリ)
:専用GPUメモリ「12GB」、共有GPUメモリ「約16GB」
私見になりますが、パソコンは綺麗に使用されていたように感じます。
※詳細は、画像でご確認ください。
【付属品】?本体、電源コード
となります。
AI画像生成
?・WebUI Forge
?・Stable Diffusion WebUI
AI顔スワップ動画生成
?・Rope
?・ReActor-UI
Pinokio【AIツール一覧】
・CogStudio 【動画生成】
・Hallo 【リップシンク】
・Forge 【画像生成(FLUX)】
・Story Diffusion
comics 【漫画生成】
・Stable Video Diffusion 【動画生成】
・Kohya_ss 【LoRa生成】
を再構築しました。
ローカルPCなので、AI画像、スワップ動画などを無制限に生成することが可能です。
AI生成にご興味を持たれた方などは、ご検討いただけると有難いです。
↓以下はおまけ程度にお考え下さい
AI画像生成 設定済み
●WebUI Forge(AI画像生成)
WebUI Forgeインストール済み
最新AI画像生成「FLUX.1」を生成可能
高解像度化を生成してみたい方はこちらをお試しください。
フォルダ内「Forge-user.bat」ダブルクリックで起動
?すぐに、AI画像を生成できます!
●Stable Diffusion WebUI(AI画像生成)
Stable Diffusion WebUI インストール済み
CheckPoint インストール済み
フォルダ内「webui-user.bat」ダブルクリックで起動
?すぐに、AI画像を生成できます!
いろいろな画風を楽しみたい方は、LoRAが豊富なこちらをご活用ください。
●Rope (ディープフェイク動画生成:複数人個別スワップ可)
・お好きな動画をご用意
・AIなどで顔画像をご用意
・複数人の顔スワップが可能元動画データと変更したい各スワップ顔画像を準備すれば、新しい動画が生成可能?←おすすめ!
お好きな動画の人物を変更すること(顔スワップ)が可能です。
フォルダ内「Rope_setup.bat」ダブルクリックで起動
●ReActor-UI (ディープフェイク動画生成)
元動画データと変更したいスワップ顔画像を準備すれば、新しい動画が生成可能
フォルダ内「ReActor_setup.bat」ダブルクリックで起動
詳細は、「WebUI Forge」「Stable Diffusion」「Rope」「ReActor-UI」で検索をお願いいたします。
AI生成/スワップ方法なども、検索などでご確認いただけるようにお願いいたします。
●Pinokio(AIツールの一覧)
AIツールをまとめた「 Pinokio 」を導入しました。
いろいろなAI生成ツールを「Pinokio」で管理・操作ができます。
・CogStudio 【動画生成】
・Hallo 【リップシンク】
・Forge 【画像生成(FLUX)】
・Story Diffusion
comics 【漫画生成】
・Stable Video Diffusion 【動画生成】
・Kohya_ss 【LoRa生成】
?※目的の人物などの画像を20枚程度からLoRaを生成可能
?※StableDiffusionWebUIで目的の人物AI画像を生成可能
●参考資料(AI生成関連)?
各AI生成ソフトごとに、簡単な操作方法を記述した説明書を制作しました?参考となるサイトを各フォルダごとに追加
?簡単ではありますが、もしよろしければ、ご活用ください。
ご興味を持たれた方は、ご検討のほど、よろしくお願いいたします。
ローカルPCに設定する時間がない方などにもお勧めかなと思います。「 Stable Diffusion WebUI
」は1年以上活用していますが、いまだに楽しいです。「 Rope
」は新しいスワップUIで、複数人の個別顔スワップが可能になった上に、精度の向上やUI機能も使いやすくなっています。
8月より話題の画像生成AI「 FLUX.1 」もローカルPCで楽しめるようになりました。
AI画像生成の能力は、以前より格段に高くなりました。
AI画像か写真か、見分けがつかない画像も生成できました。
「 Pinokio
」でAI動画も生成可能となりました。AI画像を生成した後にご活用ください。
「 Kohya_ss
」もインストールしておきました。
※簡単ではありますが、使用方法も説明書に追加しておきました。
LoRaを作成できるので、お好きな人物のAI画像も生成可能となっております。
詳細は、画像でご確認ください。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
14800円
ギャラリー








知人からの依頼となります。
本体の動作を確認しました。
リモコンの反応を確認しました。
ヌンチャク(?)の反応を確認しました。
ソフト(9本)
・ニュー・スーパーマリオブラザーズ・Wii
・マリオカート
・スーパーマリオギャラクシー
・スーパーマリオギャラクシー2
・ジャストダンス
・Wiiパーティ
・みんなのリズム天国
・Wiiスポーツ?リゾート
・フィットネス?パーティ
詳細は、画像でご確認ください。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
14800円
ギャラリー
知人からの依頼となります。
本体の動作を確認しました。
リモコンの反応を確認しました。
ヌンチャク(?)の反応を確認しました。
ソフト(9本)
・ニュー・スーパーマリオブラザーズ・Wii
・マリオカート
・スーパーマリオギャラクシー
・スーパーマリオギャラクシー2
・ジャストダンス
・Wiiパーティ
・みんなのリズム天国
・Wiiスポーツ?リゾート
・フィットネス?パーティ
詳細は、画像でご確認ください。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
完売しました
9800円
ギャラリー










リンナイ KG67BKL(LP)
ブランド:リンナイ
知人からの依頼となります。
汚れや傷などがあります。
詳細は、画像でご確認ください。
【付属品】本体のみ
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
9800円
ギャラリー
リンナイ KG67BKL(LP)
ブランド:リンナイ
知人からの依頼となります。
汚れや傷などがあります。
詳細は、画像でご確認ください。
【付属品】本体のみ
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
3500円
ギャラリー



Wii EA BEST HITS MONOPOLY クラシック&ワールドエディション [日本語版]
【Wii】 モノポリー [EA BEST HITS]ブランド:エレクトロニック・アーツ
発売日:2010/12/16
詳細は、画像でご確認ください。
【付属品】本体のみ
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
3500円
ギャラリー
Wii EA BEST HITS MONOPOLY クラシック&ワールドエディション [日本語版]
【Wii】 モノポリー [EA BEST HITS]ブランド:エレクトロニック・アーツ
発売日:2010/12/16
詳細は、画像でご確認ください。
【付属品】本体のみ
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
4800円
ギャラリー


アンパンマン ノリノリおんがく キーボードだいすき
ブランド:ジョイパレット
知人からの依頼となります。
動作確認済み
詳細は、画像でご確認ください。
ノークレーム、ノーリターンでお願いいたします。
【付属品】本体のみ
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]