ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
現在データベースには 492 件のデータが登録されています。

はじめに

Excelの立ち上げができないと連絡があった。
ご訪問するとOS自体も10分程度要している感じだった。
Excelに至っては、さらに10分程度の時間を要した。
パソコン最適化
iobitを使用し、最適化を実施
【公式】Windows PCを劇的に高速化・最適化・セキュリティ保護 - IObit
IObitは、パソコン高速&快適化、セキュリティ対策、ドライバーアップデート、パソコン最適化などを総合メンテナンスして、ワンクリックでWindows PCを新品のように動きま…
- Advanced SystemCare
- Malware Fighter
- Uninstaller
ある程度、OSの起動も速くなった
Windows11アップグレード
2025年10月14日にWindows10のサポートが終了
サポートが終了することもあり、Windows11へアップグレードを実施
パソコン最適化
Windows11のアップデートを実施。
また、起動時のスタートアップ時のアプリを整理整頓
メモリ増設

元々4GBのメモリでした。
メモリ8GBを増設し、12GBにしました。
パソコン設置
ご自宅にパソコンを持参し、パソコンを設置した。
また、インターネット・メール・印刷・アプリなどを確認し、パソコン修理を終了した。
以前に比べると20秒程度で起動できるようになり、お客様の大変喜んでおられました。
パソコンが遅くて困っている方がいましたら、お気軽にご相談ください。


19800円 → 12800円 (※在庫処分)
動作動画
ギャラリー






説明
知人からのご依頼となります。
複数台(4台)あります。
最近まで問題なく起動していたそうです。
- HDDを新品SSD256GBに交換【新品】
- マザーボードの電池交換【新品】
- Windows11にアップグレード
- Office365【新たにインストール】
本体外装にキズがある状態です。
| 状態 | 中古品【傷あり】 |
|---|---|
| パソコンメーカー | 富士通 |
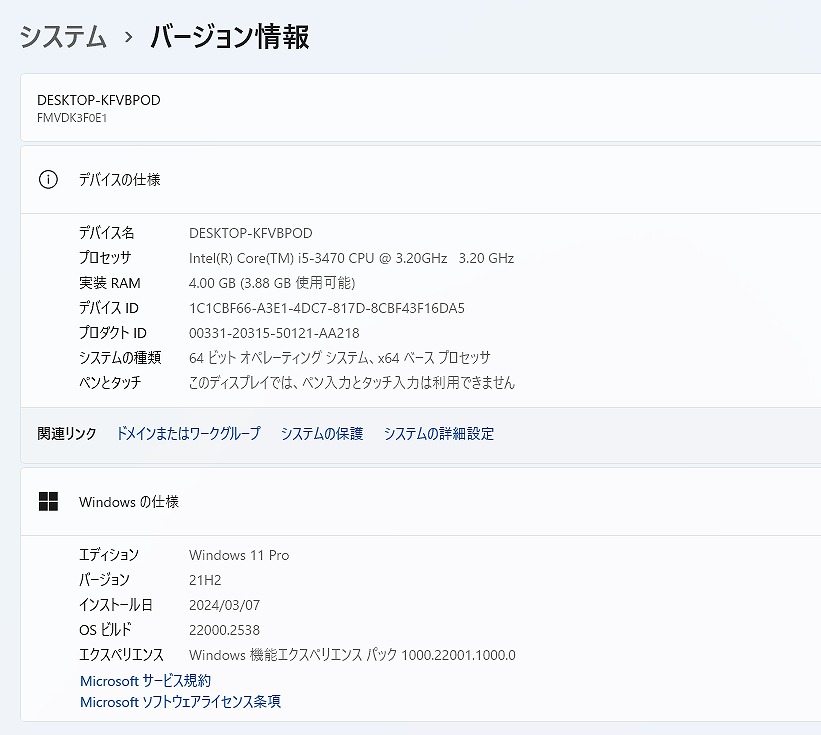
| 型番 | ESPRIMO D582/F |
| カラー | ホワイト |
| CPU | Intel Core i5 3470 【3世代】3.2GHz コア数:4 スレッド数:4 |
| メモリ | 4 GB |
| ストレージ | SSD 256 GB【新品】 |
| OS | Windows 11 Pro 64 bit |
| ソフト | Microsoft Office 365 |
| 光学ドライブ | DVDスーパーマルチドライブ |
| ネットワーク | 有線:○ |
| 接続端子 | USB2.0 (前×2・後×2)、USB3.0 (後×4) |
| 外形寸法 | 約89cm× 約338cm× 約332cm |
| 付属品 | 電源アダプタ / ACケーブル |
料金
税込 19800円 (税込)/1台→ 税込 12800円 /1台 (※在庫処分)
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]

29800円 → 24800円 ?(※在庫処分)
ギャラリー









説明
知人からのご依頼となります。
最近まで問題なく起動していたそうです。
- HDDを新品SSD256GBに交換【新品】
- マザーボードの電池交換【新品】
- Windows11にアップグレード
- Office365【新たにインストール】
| 状態 | 中古品 |
|---|---|
| パソコンメーカー | 富士通 |
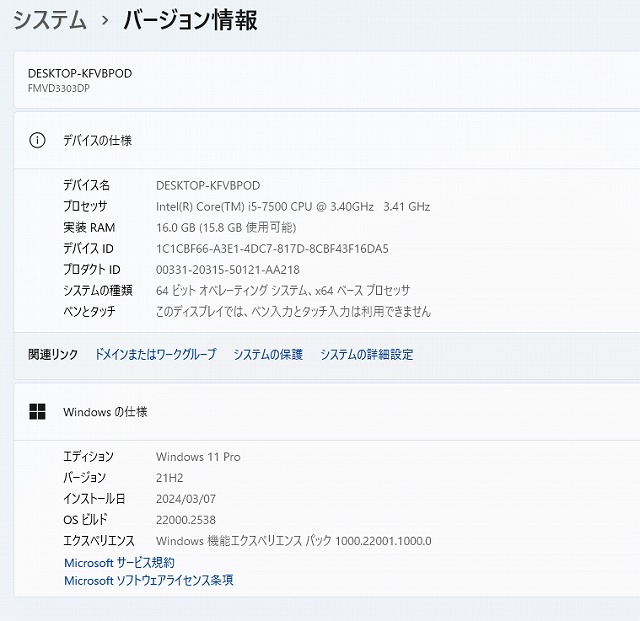
| 型番 | ESPRIMO D587/SX (FMVD3303DP) |
| カラー | ホワイト |
| CPU | Intel Core i5 7500 @3.40GHz |
| メモリ | 16 GB |
| ストレージ | SSD 256 GB【新品】 |
| OS | Windows 11 Pro 64 bit |
| ソフト | Microsoft Office 365 |
| 光学ドライブ | DVDスーパーマルチドライブ |
| ネットワーク | 有線:○ |
| 接続端子 | USB(前×2・後×6) |
| 外形寸法 | 約89cm× 約338cm× 約332cm |
| 付属品 | 電源アダプタ / ACケーブル |
パソコン本体は少し古いスペックとなりますが、動作自体は問題ないように感じます。
インターネット、ワードを確認したところ、違和感なく動作いたします。?
【付属品】?本体、電源コード(写真参照)?となります。
お問合せ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
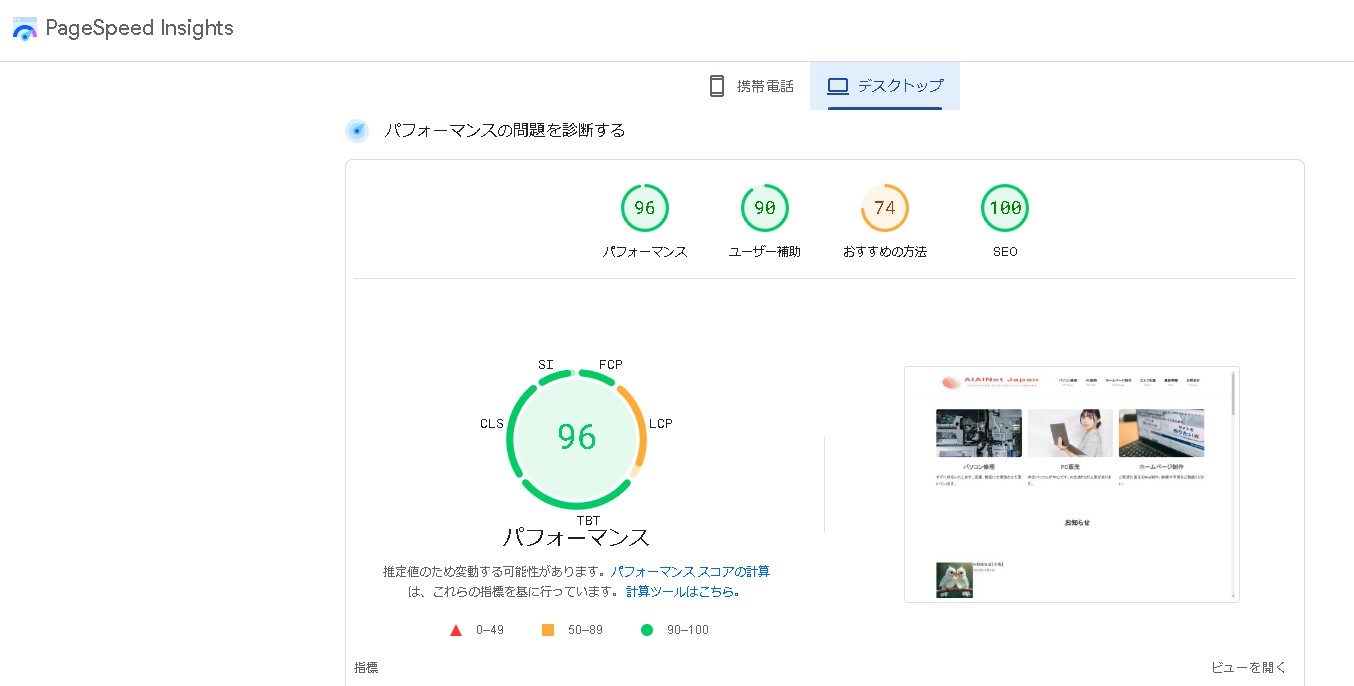
Webサイト表示速度検証ツール
PageSpeed Insights
WordPress最適化後
パフォーマンスが良くなりました
最適化方法(参考サイト)
Autoptimize
CSS、java_script、画像を最適化してWordPressを高速化するプラグイン!Autoptimize
ウェブサイトの表示速度を高速化してユーザの直帰率を下げる事は、Google検索の上位表示に欠かせない指標の一つとなりますが、ソースコードを圧縮、遅延読み込みをしてWor…

Flying Pages
Flying Pages: Preload Pages for Faster Navigation & Improved User Experience – WordPress plugin | WordPress.org
Preload pages intelligently to boost site speed and enhance user experience by loading pages before users click, ensuring instant page transitions.

EWWW Image Optimizer
【2024年6月版】EWWW Image Optimizerの最新設定方法と正しい使い方についてわかりやすく解説|hitodeblog(ヒトデブログ)
2024年6月16日:手順、設定画面を最新のものに更新しました 「サイトが重いから対策をしたい……」 「画像を圧縮すればサイトが早くなるって聞いた

Autoptimize
Autoptimizeのおすすめな設定方法&使い方を画像たっぷりで徹底解説【WordPressの最適化プラグイン】
専業ブロガー7年目のあかね猫です WordPressで超定番なプラグインの1つ… の導入手順からおすすめな設定方法&使い方まで、実際の画像たっぷりでブログ初心者さん向けに…

W3 Total Cache
【2024年最新】W3 Total Cacheの使い方・設定方法(不具合の対処も紹介)
W3 Total Cacheは、キャッシュにより表示速度を高速化できるプラグインです。1度表示されたウェブページのデータを、サーバーやブラウザに保存しておくことで、パフォーマ…

Vidu
KLING
dream-machine
Luma Dream Machine | AI Video Generator
Unlock your creativity with Luma AI Video Generator. Turn text into stunning videos with our cutting-edge text-to-video AI. Dream big, create bigger!

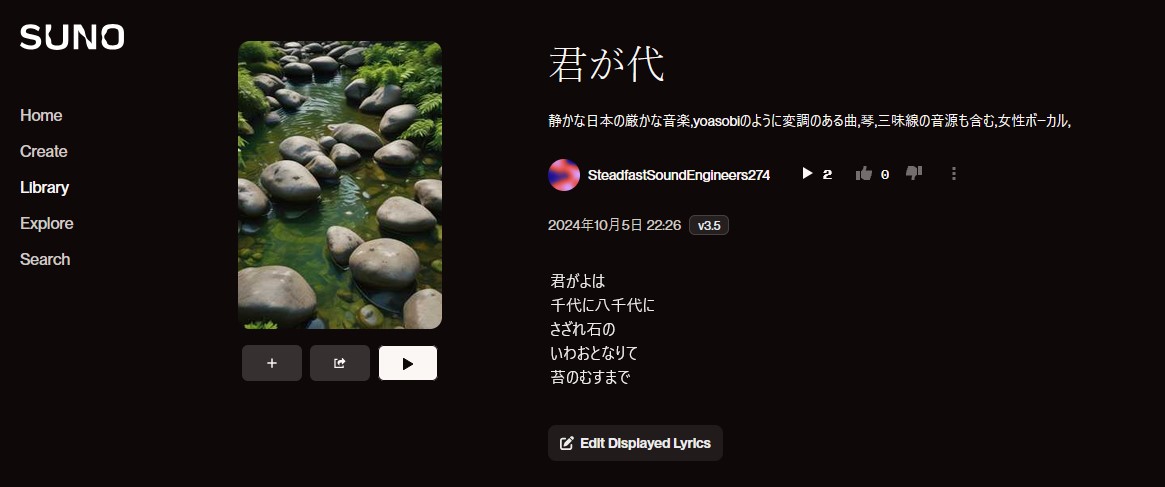
SUNO
音楽生成
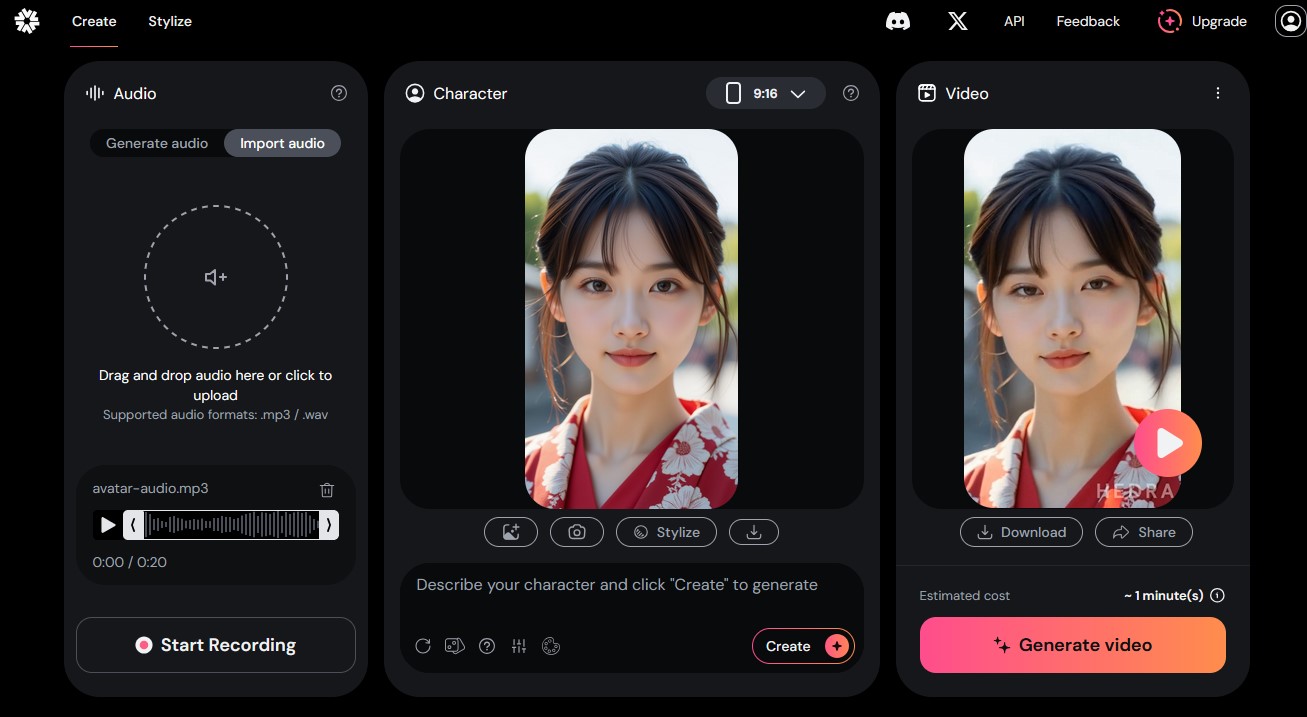
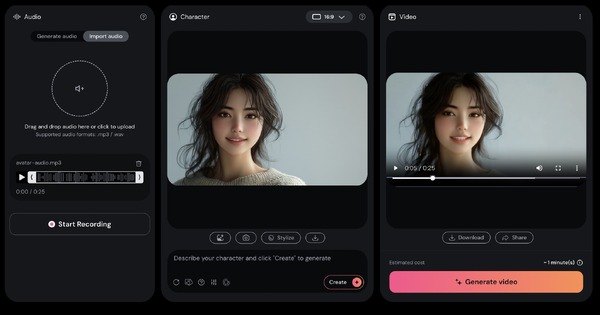
Hedra
音楽に合わせて口パク(リップシンク)を生成
canva
動画編集
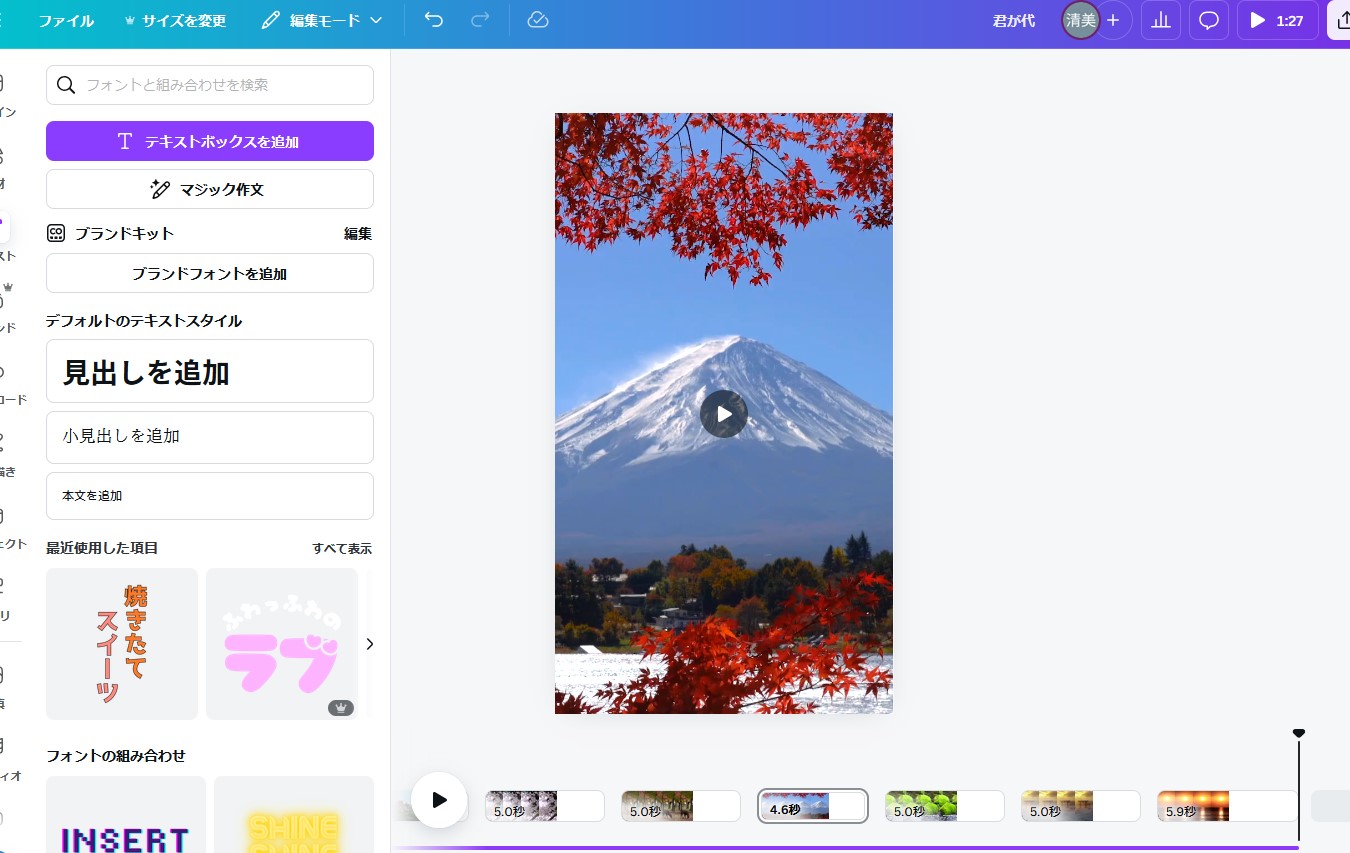
完成動画
君が代
君が代は 千代に八千代に
(きみがよは ちよにやちよに)
さざれ石の 巌となりて 苔のむすまで
(さざれいしの いわおとなりて こけのむすまで)
参考サイト
簡単導入ですぐに使える!AIリップシンクツール「Hedra」Character-1で、可能性は無限大!
AIリップシンクのHedraが大幅機能アップの「Character-2」投入。AIミュージックビデオやAIポッドキャストが実用域に(CloseBox)
AIリップシンクのHedraが大幅機能アップの「Character-2」投入。AIミュージックビデオやAIポッドキャストが実用域に(CloseBox) | テクノエッジ TechnoEdge
AIリップシンクサービスのHedraが新バージョン「Character-2」を公開したので使ってみました。
Hedra公式サイト