ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
現在データベースには 506 件のデータが登録されています。
完売しました。
パソコンの状態もかなり良く、大変喜ばれました。
AI画像・動画にも興味があるとのことでした。
これからも、良いものを安くお届けできるように精進していきたいと思います。
値下 250,000円 (※在庫処分)
ローカルPCでAI画像を生成したい方へ
AI画像を生成するためには、高スペックなパソコンが必要です。
最小スペックでも15万円以上のパソコンが必要となります。
※特にグラフィックボード(GPU)
私もはじめは最小スペックでAI画像を生成していました。
しかし、生成時間があまりにもかかるので、少しずつですがスペックを上げていきました。
高スペックにすればするほど、生成時間も短縮され、AI画像を生成することが楽しくなりました。
AI画像生成に興味を持たれた方は、まずは以下のサイトをご覧ください。

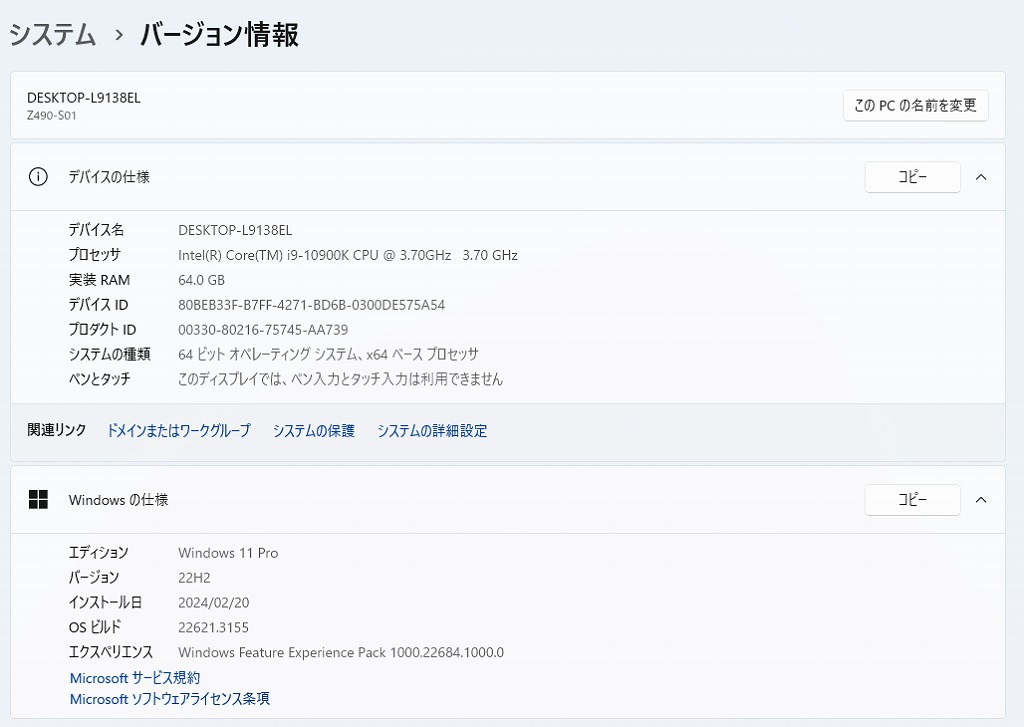
パソコンスペック
| 筐体 | COOLER MASTER |
| OS | Windows11 Pro |
| CPU | Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz |
| メモリ | 64 GB (スロット:4/4) |
| グラフィック | PALiT RTX3080Ti GAMEROCK 12GB |
| 光学ドライブ | BD-RE BH16NS58 |
| ストレージ1 | SSD M.2 : 1TB |
| ストレージ2 | HDD : 2TB |
| オフィスソフト | Microsoft Office Pro 2021 |
| CPUクーラー | Cooler Master 簡易水冷CPUクーラー |












同スペック販売価格: G-GEAR GA9J-J202/ZT 税込価格: 379,800円
※ご用意したパソコンは、 メモリ64 GB (増設)+ CPUクーラー + Office付き + AI画像生成設定済み となります
デスクトップの確認


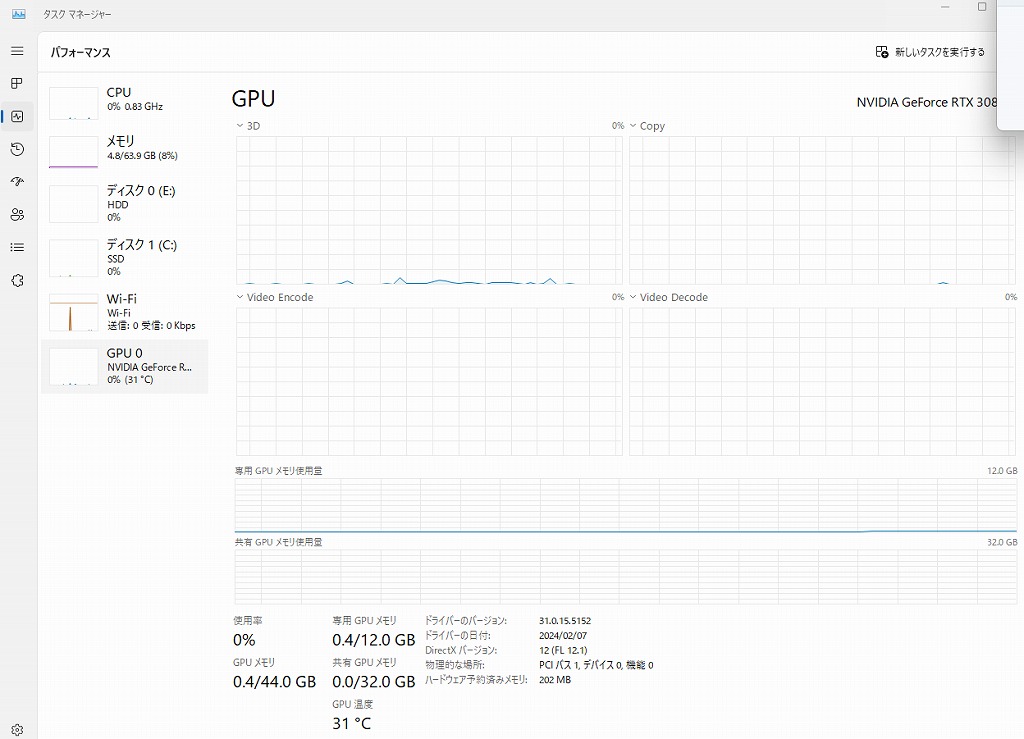
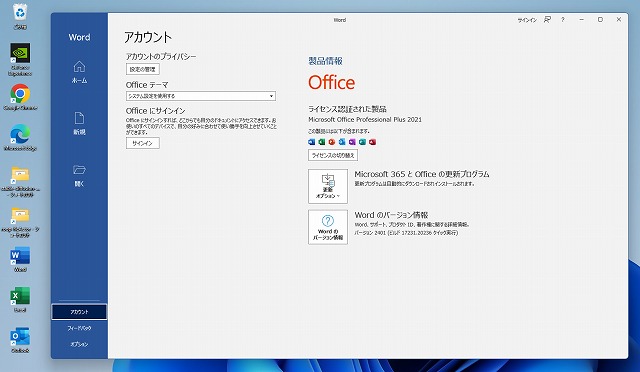
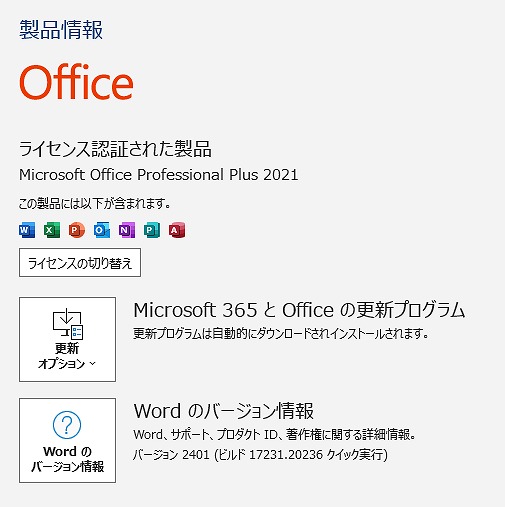
AI画像生成 設定済み
- Stable Diffusion WebUI インストール
- CheckPoint インストール
- Lora インストール
すぐに、AI画像を生成できます!
「Stable Diffusion WebUI」と「ReActor-UI」の生成方法を実際にご覧頂けます。
料金
税込 275,000円 (税抜250,000円)→ 税込 250,000円 (※在庫処分)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
はじめに
AI画像から副業に転換できないかと思い探していたところ、以下の動画サイトを発見した
pixivFACTORY

BOOTH

考察
実際にキャラクターを作成し、今後試したいと思います。
はじめに
TVでFireTVを使用している方で、TVerが見れないと連絡があった。

解決策
- Fire TV Stickを再起動します。
- Wi-Fiルーター、モデムを再起動します。
- Fire TV Stickにご利用いただけるアップデートがあれば適用します。
- Fire TV Stickから「設定」を開きます。
- 「アプリケーション」を選択します。
- 「インストール済みアプリを管理」を選択します。
- 「TVer」を選択します。
- 「強制停止」を選択します。
- 「データを消去」を選択します。
- 「キャッシュを消去」を選択します。
59500 円 →? 54000 円(※在庫処分)
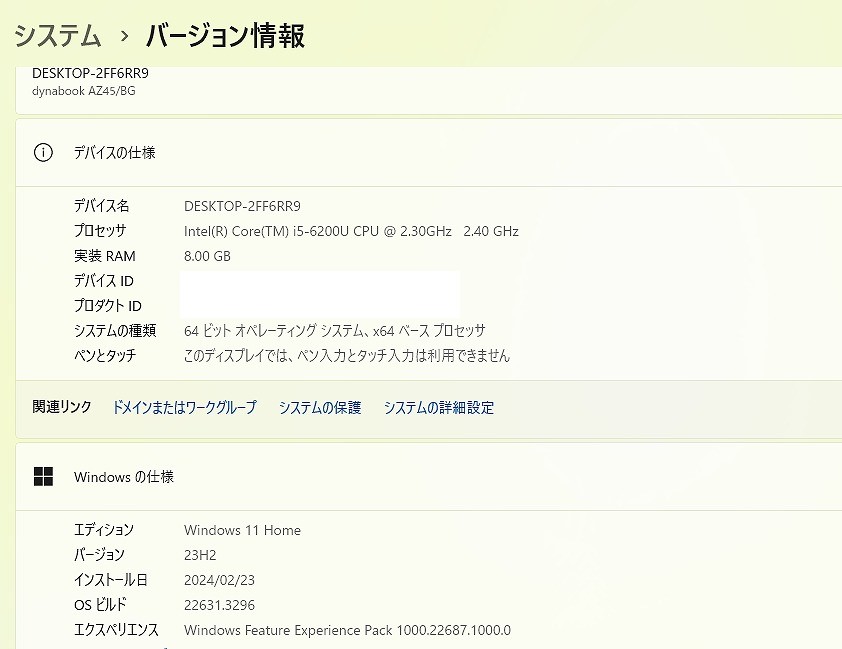
美品/第6世代i5/メモリ8GB/Webカメラ/Office/Win11
ギャラリー









説明
Intel Core i5プロセッサー&メモリ8GB搭載で、動作も快適♪
ハードディスクも新品1TB(1000GB)SSDへ換装済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
使用感も少なく、美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | TOSHIBA |
| 型番 | Dynabook AZ45/BG |
| カラー | サテンゴールド |
| CPU | Intel CORE i5-6200U 2.30-2.80GHz |
| メモリ | 8 GB |
| ストレージ | SSD 1TB(1000 GB)【新品】 |
| 表示能力 | 15.6 インチ |
| 解像度 | 1366×768 |
| OS | Windows 11 Home 64 bit |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | DVDスーパーマルチ |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB: 3.0x2個 2.0x2個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル |
料金
税込? 59500 円 ?(税抜54000円)→? 54000 円(※在庫処分)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
はじめに
新しい動画生成AIをみつけた
参照サイト
生成過程
画像生成 (Stable Diffusion)
動画生成AI (Haiper.ai)

動画編集 (VideoProc Vlogger)
動画完成
おまけ
はじめに
Windows 10は22H2最終バージョン、サポート期限は 2025年10月14日 となっております。
OS起動が遅く、サポート期限前にWindows11にアップグレードを依頼された。
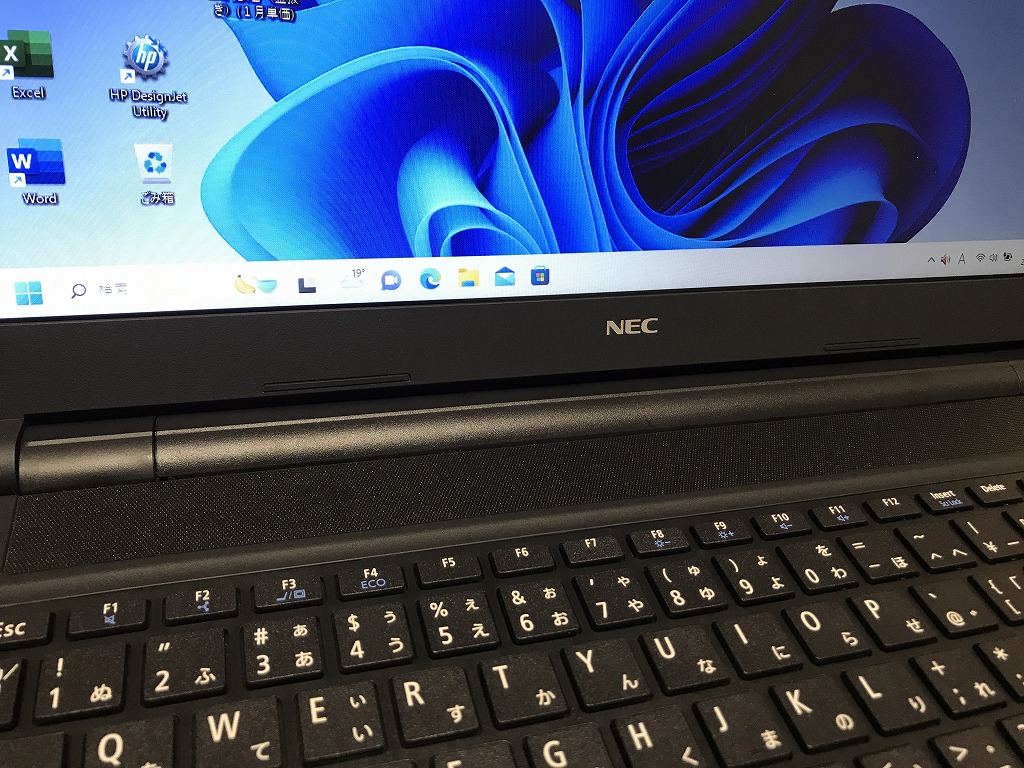
【機種/型番】NEC VRT25F-5 (PC-VRT25FB7S4R5)


パソコン修理の過程
パソコンの分解
裏面のネジを外す

キーボードを外し、ネジを外す

表面側を外し、HDDを取り外す

- HDDデータをSSDへ丸ごとコピー(HDDからSSDへ換装)
- SSDを本体へ戻す
- Windows10からWindows11へアップグレード
パソコン修理の終了
本体を起動し、Windows11を確認
最後に
- ウィルス除去
- パソコン最適化&高速化
- クリーニング
パソコン起動も10秒程度に高速になり、無事にWindows11へアップグレードが成功してよかったです。
はじめに
ロゴ素材を作成したいと思い、探していたところ、興味深いサイトをみつけた。
参考サイト
『Stable Diffusion WEB UIで簡単! ステッカー・アイコン・ロゴ素材の作り方』

作成過程
参考サイトと同様な素材を作成してみました。
?プリントステッカー風
(high resolution:1.5),logo design art,Vivid Colors,cool,Messily painted,smooth vector,(white background),punk and wolf
motif,
neg:(worst quality:2),(low quality:2),

?ステッカーロゴ風
(high resolution:1.5),2d ferocious wolf head, vector illustration, angry eyes, team emblem logo, 2d flat, centered
nega:(worst quality:2),(low quality:1.4),((3d, cartoon)),

?アートロゴ風
(high resolution:1.5),futuristic minimalistic centered stylized logo of a subject,botanical motif white with black
background, smooth vector, typo
nega:(worst quality:2),(low quality:1.4),((3d, cartoon)),

?モダンアイコン風
(high resolution:1.5),Clean, sharp, vectorized, Company logo,castle and sword motif,icon,trending,modern and
minimalist,monochrome,
neg:(worst quality:2),(low quality:1.4),((3d, cartoon)),

?アイコン風
(highly detailed),Simple and iconic logo design chart of combining (castle:1.2) motifs, (chain) accent, vector drawing,
trending on behance ,simple, minimal
nega:(worst quality:2),(low quality:2),

?シンプルロゴ風
simple symbol logo,stylish,cool,white background,vector,flat,
nega:(worst quality:2),(low quality:1.4),((3d, cartoon)),

息抜きをも兼ねて、遊ばせていただきました。
63800円 →? 58000 円(※在庫処分)
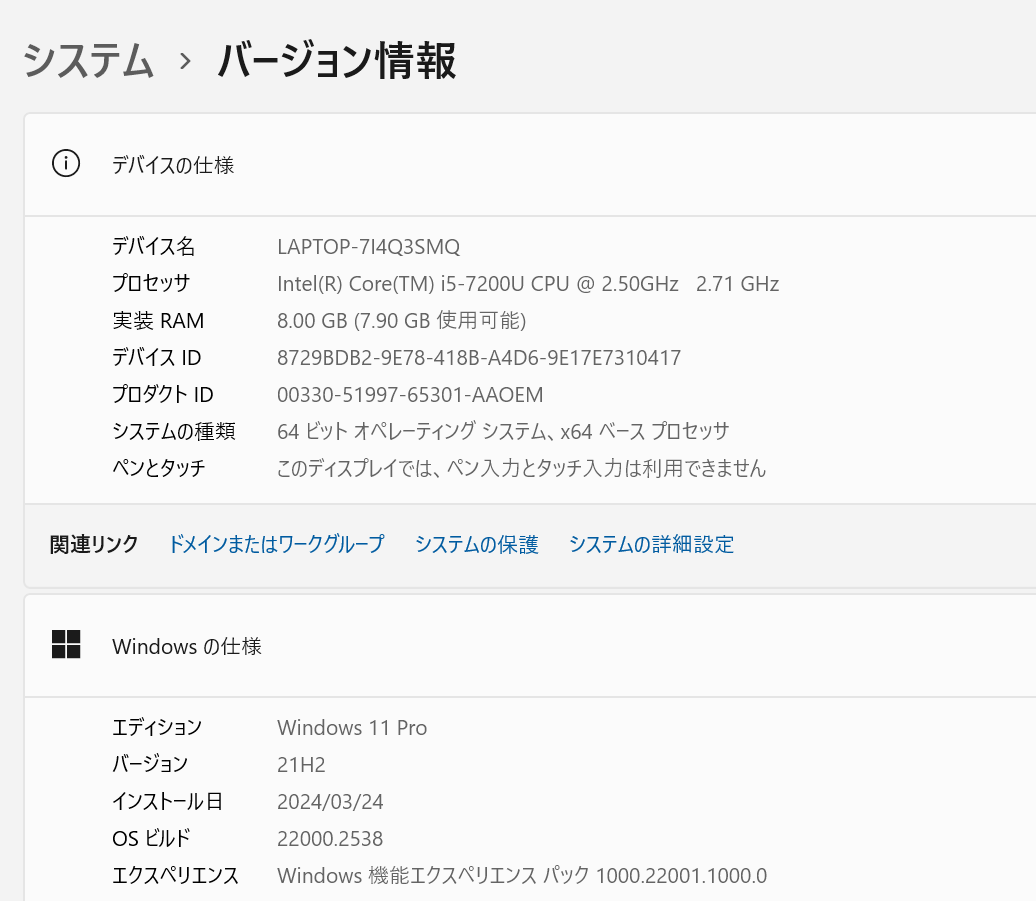
第7世代☆VAIO☆VJPG11C11N☆Core i5 2.50GHz/8GB/SSD256GB/無線/Bluetooth/WEBカメラ/ Office 2021 /Win11
参考資料
ある学校に配布されたパソコン販売パンフレット

ギャラリー






説明
Intel Core i5プロセッサー&メモリ8GB搭載で、動作も快適♪
- Core i5
- SSD 256GB
- 超軽量で丈夫なモデルです。その上、性能も申し分ありません。
- 高性能なCPUの Core i5 、 SSD256GB (読み書きが速い!)と,大容量 メモリ8GB です。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
使用感も少なく、ある程度美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | VAIO |
| 型番 | VJPG11C11N |
| カラー | ブラック |
| CPU | Core i5-7200U プロセッサー 2.50 GHz (最大3.10 GHz) |
| メモリ | 8 GB |
| ストレージ | SSD 256GB |
| 表示能力 | 13.3型 |
| 解像度 | 1920×1080ドット |
| OS | Windows11 Pro |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | 無 |
| ネットワーク | 有線:〇 / 無線:○ |
| 接続端子 | USB (USB 3.0) 給電機能付き × 1、USB (USB 3.0) × 2 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| インターフェース | SDカードスロット(SDHC・SDXC対応) HDMI ® 出力端子×1 |
| 付属品 | 電源アダプタ / ACケーブル |
| 外形寸法 | 約 1.06 k g |
料金
税込? 63800円 ?(税抜58000円)→? 58000 円(※在庫処分)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
79200円 → 72000 円 ?(※在庫処分)
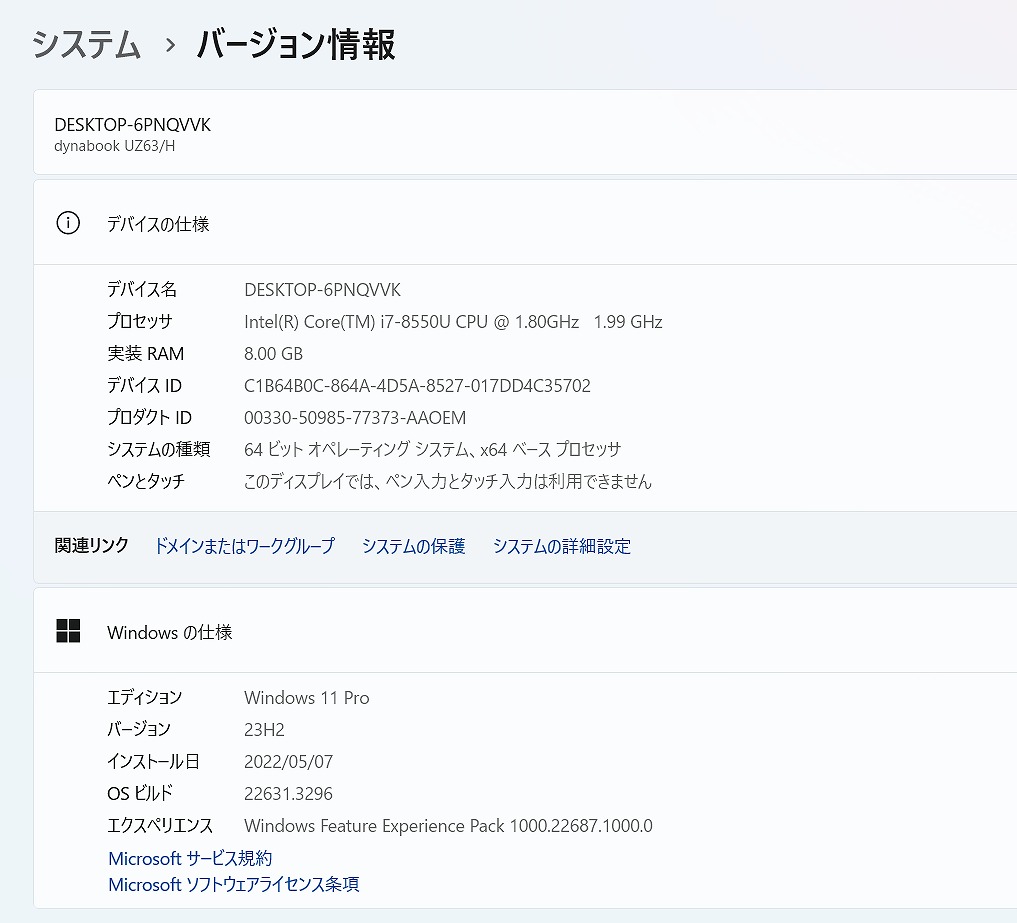
【爆速SSD☆Win11 Pro】TOSHIBA dynabook UZ63/H ☆新品M.2 SSD1TB!/Core i7/新品キーボード/新品バッテリー/メモリ8GB/MS Office 2021
参考資料
ある学校に配布されたパソコン販売パンフレット
ギャラリー







説明
Intel Core i7プロセッサー&メモリ8GB搭載で、動作も快適♪

- M.2 NVMe SSD 1TB(1000GB)【新品】
※一般的なSSDより高速 - キーボード換装 【新品】
- バッテリー換装 【新品】
- 超軽量で丈夫なモデルです。その上、性能も申し分ありません。
- 新品キーボードに換装 しましたので、きれいな状態です。
- バッテリーも純正新品に換装 しましたので、外出先での使用も安心です。
- harman/kardonのスピーカーシステムでいい音です。
- 高性能なCPUの Core i7 (第8世代)、大容量の新品 M.2 SSD1TB (読み書きが速い!)と,大容量 メモリ8GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
使用感も少なく、ある程度美品に思います。
| 状態 | 中古品 |
|---|---|
| パソコンメーカー | TOSHIBA |
| 型番 | dynabook UZ63/H |
| カラー | ブラック |
| CPU | インテル Core i7-8550U |
| メモリ | 8 GB |
| ストレージ | M.2 NVMeSSD 1TB(1000GB)【新品】 |
| 表示能力 | 13.3型 FHD |
| 解像度 | 1,920×1,080ドット |
| OS | Windows11 Pro |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | 無 |
| ネットワーク | 無線:○ |
| 接続端子 | USB:1個 SDカードスロット |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| インターフェース | マイク入力/ヘッドホン出力端子×1 Thunderbolt™ 3(USB Type-C™)コネクタ(電源コネクタ)×2 HDMI ® 出力端子×1 |
| 付属品 | 電源アダプタ / ACケーブル |
| 外形寸法 | 約316.0(幅)×227.0(奥行)×15.9(高さ)mm 約1,090g |
料金
税込? 79200円 ?(税抜72000円)→ 税込? 72000 円 ?(※在庫処分)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
74800円 → 税込? 68000 円 ?(※在庫処分)
Dynabook S73/HS・第11世代Corei3・メモリ16G・新品SSD500G・Win11Pro・13.3型FHD・office2021
参考資料
ある学校に配布されたパソコン販売パンフレット
ギャラリー






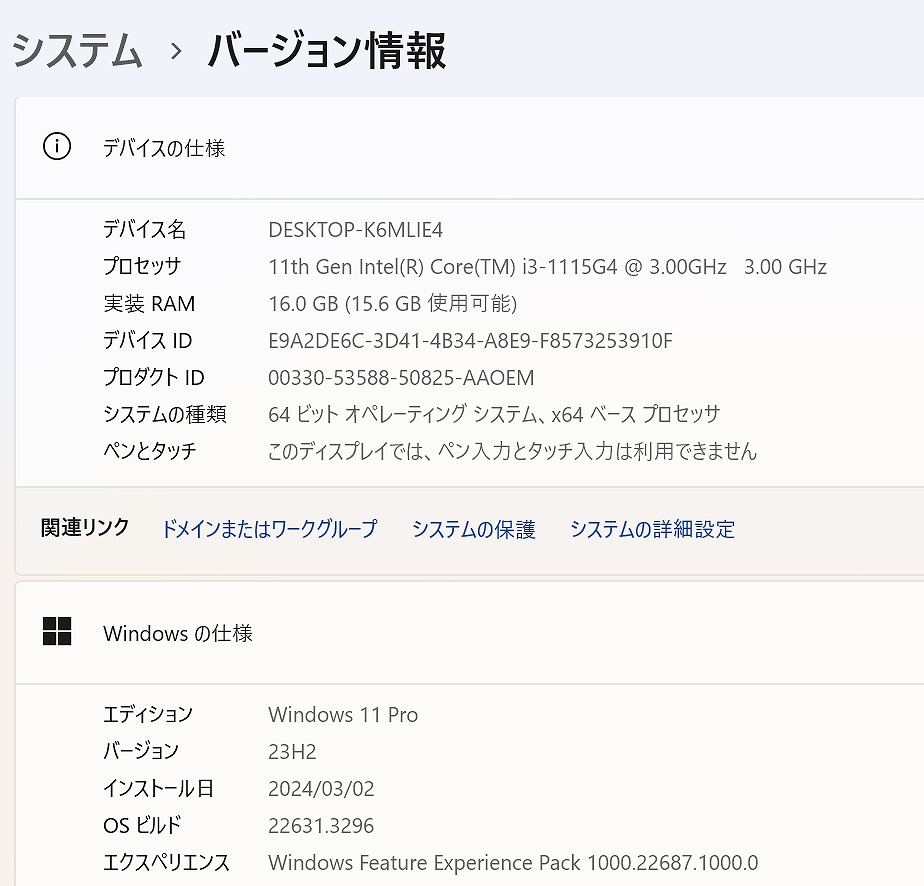


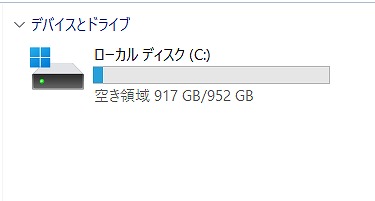
説明
Intel Core i3プロセッサー&メモリ16GB搭載で、動作も快適♪
- M.2 NVMe SSD 500GB【新品】
※一般的なSSDより高速
- 超軽量で丈夫なモデルです。その上、性能も申し分ありません。
- 高性能なCPUの Core i3 、大容量の新品 M.2 SSD 500GB (読み書きが速い!)と,大容量 メモリ16GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
新品に近く使用感も少なく、ある程度美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | TOSHIBA |
| 型番 | Dynabook S73/HS |
| カラー | ブラック |
| CPU | Core i3-1115G4 |
| メモリ | 16 GB |
| ストレージ | M.2 NVMeSSD 500GB【新品】 |
| 表示能力 | 13.3型 |
| 解像度 | 1920×1080ドット |
| OS | Windows11 Pro |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | 無 |
| ネットワーク | 有線:〇 / 無線:○ |
| 接続端子 | USB3.1 Gen1(USB3.0) Type-Ax2/Type-Cx1 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| インターフェース | HDMIx1 microSDスロット |
| 付属品 | 電源アダプタ / ACケーブル |
| 外形寸法 | 316 x 19.9 x 227 mm, 1.269 kg |
料金
税込? 74800円 ?(税抜68000円)→ 税込? 68000 円 ?(※在庫処分)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]