ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
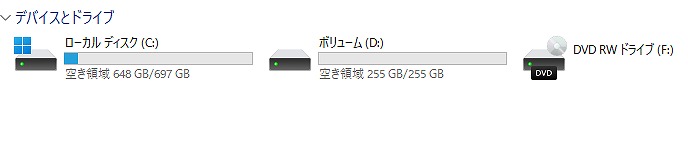
現在データベースには 510 件のデータが登録されています。
美品/第6世代i5/メモリ8GB/Webカメラ/Office/Win11/新品バッテリー
ギャラリー






説明
Intel Core i5プロセッサー&メモリ8GB搭載で、動作も快適♪
- SSD 1TB(1000GB)【新品】
バッテリー交換【新品】
- 高性能なCPUの Core i5 、大容量の新品 SSD 1TB (1000GB) (読み書きが速い!)と,大容量 メモリ8GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
使用感も少なく、ある程度美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | TOSHIBA |
| 型番 | Dynabook AZ45/BG |
| カラー | サテンゴールド |
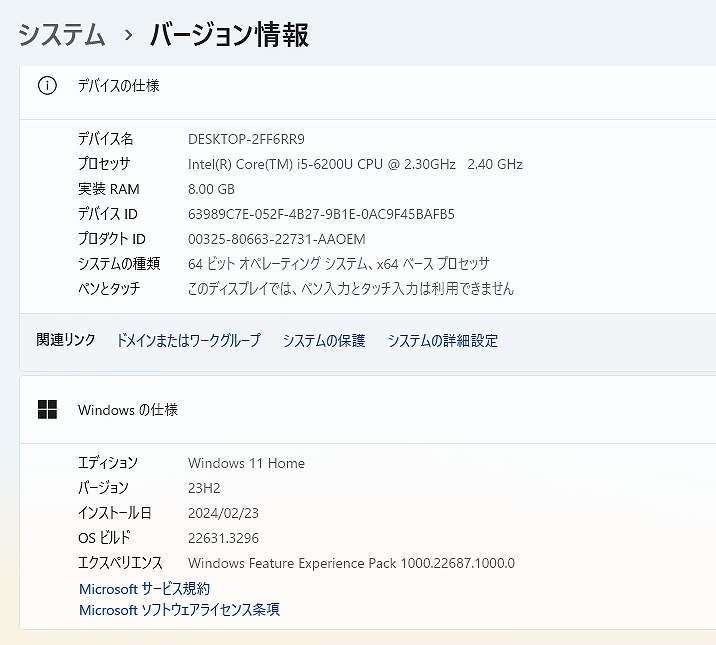
| CPU | Intel CORE i5-6200U 2.30-2.80GHz |
| メモリ | 8 GB |
| ストレージ | SSD 1TB (1000GB)【新品】 |
| 表示能力 | 15.6 型 |
| 解像度 | 1366×768ドット |
| OS | Windows11 Home ? |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | DVDスーパーマルチレコーダー |
| ネットワーク | 有線:〇 / 無線:○ |
| 接続端子 | USB: 3.0×2個 2.0×2個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| インターフェース | HDMI端子 SDカードスロット |
| 付属品 | 電源アダプタ / ACケーブル |
| 外形寸法 | 379×23.7×258 mm, 2.4 kg |
料金
税込 74800円 (税抜68000円)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
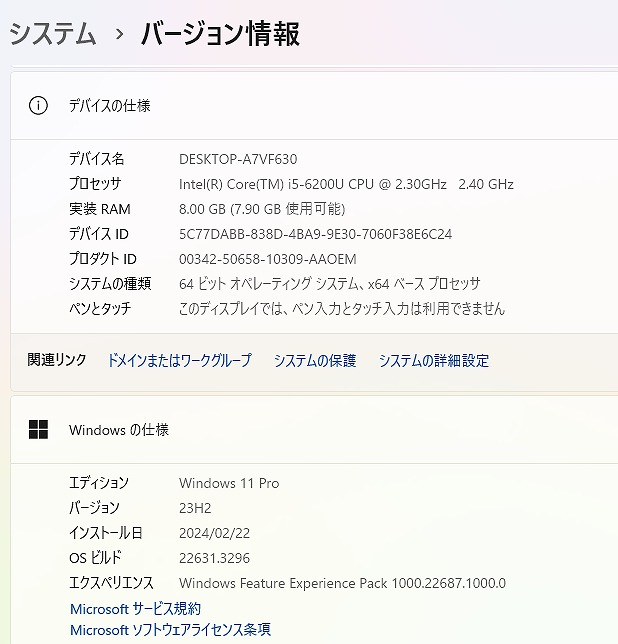
高性能第6世代i5搭載/超美品/新品M.2 SATA512GB+HDD512GB/メモリ8GB/Webカメラ/Office/Win11/
ギャラリー








説明
Intel Core i5 プロセッサー& メモリ8GB 搭載で、動作も快適♪
ハードディスクも追加で、 新品M.2 SSD 512GB へ換装済み!

- M.2 SSD Type 2280 512GB【新品】 追加
※一般的なSSDより高速
- 高性能なCPUの Core i5 (第6世代)、大容量の新品 M.2 SSD 512TB (読み書きが速い!)と,大容量 メモリ8GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
新品に近く使用感も少なく、美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | HP |
| 型番 | ProBook 450 G3 |
| カラー | ブラック |
| CPU | Intel CORE i5-6200U 2.30-2.80GHz |
| メモリ | 8?GB |
| ストレージ | M.2 SSD 512GB 【新品】 +HDD 512 GB 【計1TB(1000GB)】 |
| 表示能力 | 15.6 インチ? |
| 解像度 | 1366×768 |
| OS | Windows 11?Pro?64?bit? |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | DVDスーパーマルチ |
| ネットワーク | 有線:○ / 無線:○ |
| 接続端子 | USB: 3.0x2個 2.0x2個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| 付属品 | 電源アダプタ / ACケーブル |
料金
税込? 46200 円 ?(税抜42000円)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
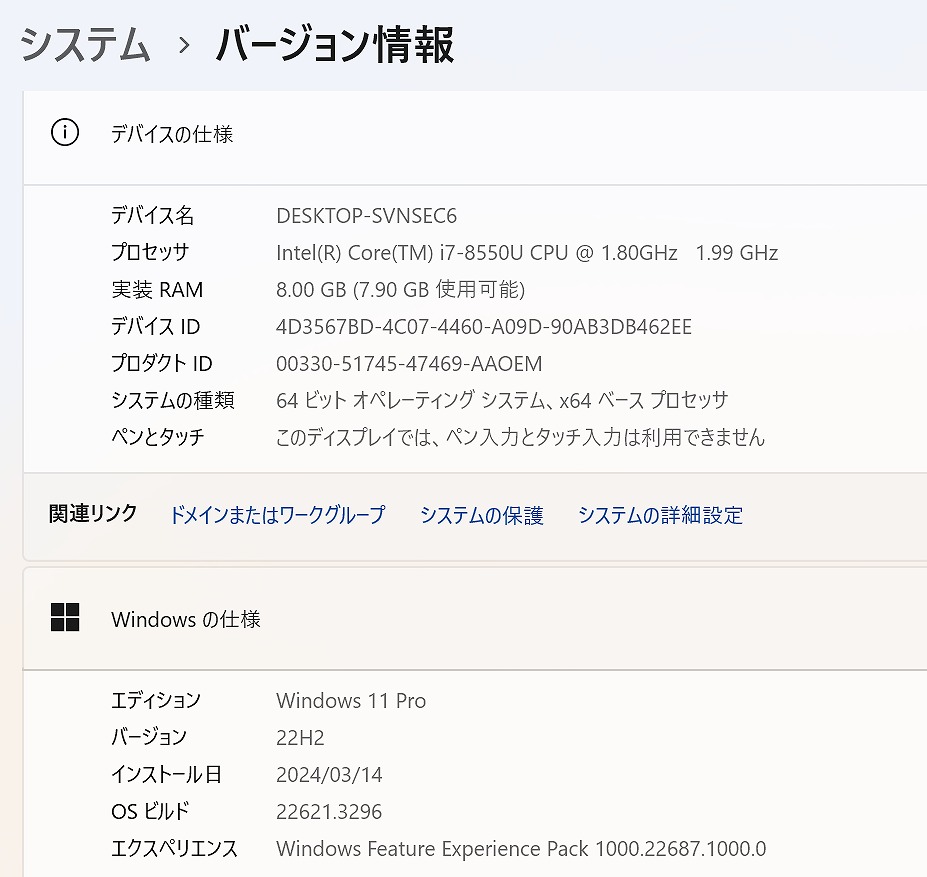
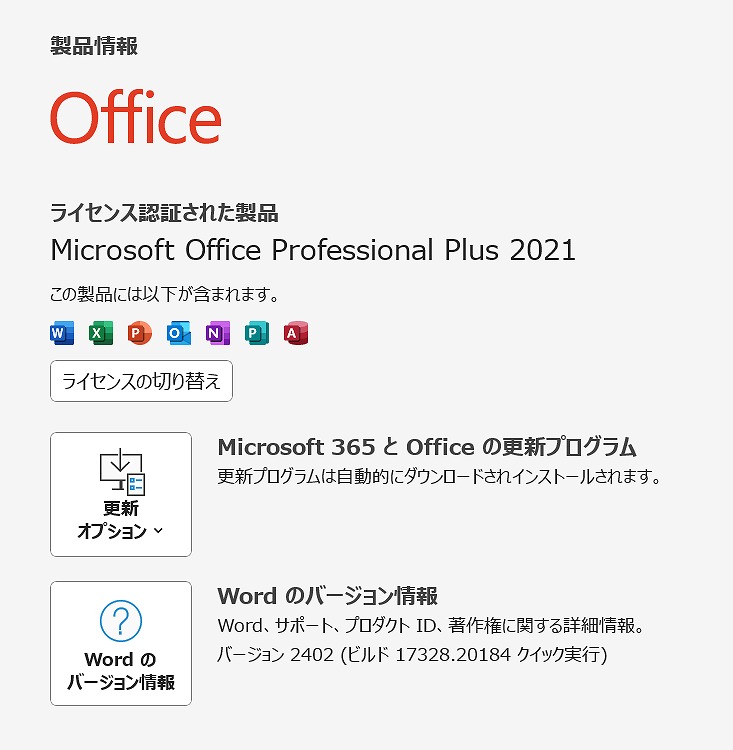
【爆速SSD☆Win11 Pro】 VAIO VJPG11C11N ☆新品M.2 SSD500GB!/Core i7 -8550U /メモリ8GB/Office 2021
参考資料
ある学校に配布されたパソコン販売パンフレット

ギャラリー






説明
Intel Core i7プロセッサー&メモリ8GB搭載で、動作も快適♪

- M.2 NVMe SSD 500GB【新品】
※一般的なSSDより高速
- 超軽量で丈夫なモデルです。その上、性能も申し分ありません。
- 高性能なCPUの Core i7 、大容量の新品 M.2 SSD500GB (読み書きが速い!)と,大容量 メモリ8GB で、動画編集もいけます。
- 最新の Microsoft office 2021 Professional Plus インストール済み!
無線LAN内蔵なので、家の中でもケーブル不要・場所を選ばずネットが出来ます!
使用感も少なく、ある程度美品に思います。
| 状態 | 中古品【美品】 |
|---|---|
| パソコンメーカー | VAIO |
| 型番 | VJPG11C11N |
| カラー | ブラック |
| CPU | Intel Core i7-8550U 1.80GHz(8CPUs) ターボブースト時最大8GB |
| メモリ | 8 GB |
| ストレージ | M.2 NVMeSSD P1 500GB【新品】 |
| 表示能力 | 13.3型 |
| 解像度 | 1920×1080ドット |
| OS | Windows11 Pro |
| ソフト | Microsoft Office Professional plus 2021 |
| 光学ドライブ | 無 |
| ネットワーク | 有線:〇 / 無線:○ |
| 接続端子 | USB:3個 |
| 内蔵機能 | WEBカメラ / Bluetooth / スピーカー / テンキー |
| インターフェース | SDカードスロット(SDHC・SDXC対応) HDMI ® 出力端子×1 |
| 付属品 | 電源アダプタ / ACケーブル |
| 外形寸法 | 約 1.06 k g |
料金
税込? 74800円 ?(税抜68000円)
お問い合わせ
※商品タイトルを「題名」にコピーして送信してください
[contact-form-7]
はじめに
知人からLINEにてモノクロ写真が送られてきた。

画素数が低いので、カラー化するためには少し難しいと思われた。
しかし、いざAI写真加工をしてみると意外とよい結果になったのでご報告させていただく。
ギャラリー




考察
低分解能でもある程度、AI写真加工は上手く処理されると思われる。
また、ブレている写真でピンボケしている写真でもある程度シャープな写真に加工してくれることが分かった。

はじめに
HitPaw Photo AI のAI写真加工について考察してみた。

HitPaw Photo AI サイト: https://www.hitpaw.jp/photo-enhancer.html
参考サイト
【HitPaw Photo AI】使い方。画像サイズの倍率・出力先などの設定を解説。
Hitpaw Photo AI モデルの比較
元画像

フェースモデル:顔のディテールを強化するための特化モデル
柔らかい

柔らかいV2

鋭い

【マルチ】カラー化モデル

ジェネラルモデル:一般的な画像向けの高画質化モデル

デノイズモデル:ノイズを除去し、クリアな画像を得るためのモデル

【マルチ】モデルによる処理結果の最適化

カラー化モデル:色の再現性を高めるためのモデル

色補正:露出や彩色不足の画像を補修

【マルチ】デノイズモデル

スクラッチリペア:傷のある写真を修復

【マルチ】フェースモデル

ナイトモード:暗い場所で撮影された写真を明るくする

元画像とAI加工後の画像比較
元画像とAI加工後の比較(スライダーを左右に動かしてください)


無料体験あり
HitPaw Photo AI サイト: https://www.hitpaw.jp/photo-enhancer.html
ノートパソコン用
2個セット
-

512MB×2
PC2-5300S
1000円 -

512MB×2
PC2-5300S
1000円 -

1GB×2
PC3-8500S
1200円 -

1GB×2
PC3-8500S
1200円 -

2GB×2
PC2-6400S
1500円 -

2GB×2
PC3-10600S
1800円
(税込み価格)
単品
-

2GB
DDR3-1066
1000円 -

2GB
PC3-10600S
1000円 -

2GB
PC2-6400S
1000円 -

2GB
PC2-6400S
1000円 -

4GB
PC4-2400T
(PC4-19200S)
1800円 -

4GB
DDR4-2400
1800円
(税込み価格)
デスクトップ用
2個セット
-

512MB×2
PC2-5300U
1000円 -

1GB×2
DDR-800(CL5)
PC2-6400U
1000円 -

1GB×2
DDR3-1333
PC3-10600
1000円 -

2GB×2
DDR?800Mhz
PC2-6400
1500円 -

2GB×2
PC3-10600U
1800円 -

2GB×2
PC3-12800U
1800円 -

4GB×2
PC3L-12800U
2400円 -

4GB×2
PC3-12800U
2400円 -

4GB×2
PC3-12800U
2400円 -

8GB×2
DDR4-3200
PC4-25600
4800円
(税込み価格)
単品
-

1GB
DDR?-800MHz
PC2-6400
600円 -

2GB
PC3-10600E
1000円 -

2GB
PC3-10600U
1000円 -

4GB
DDR3-1333
PC3-10600
1800円 -

8GB
PC3L-12800U
2400円 -

8GB
DDR?-1600MHz
PC3-12800
2400円
(税込み価格)
はじめに
SSD搭載のパソコンが急に遅くなったと持参された。
【DELL XPS】

解決方法
メモリを他のスロットに差し替えることにより、起動が通常通り高速になった。
差していたメモリスロットに不具合が生じたように考えられる。

ACアダプタ(在庫品)
※画像をクリックすると拡大します
-

lenovo -

lenovo -

lenovo -

lenovo -

hp -

NEC -

NEC -

NEC -

FUJITSU -

FUJITSU -

FUJITSU -

FUJITSU -

FUJITSU -

SHARP -

IBM -

TOSHIBA -

SONY
メーカー
- lenovo
- hp
- NEC
- FUJITSU
- SHARP
- IBM
- TOSHIBA
- SONY など
中古品となります。
電源ケーブルをお探しの方は、お気軽にご相談ください。
料金
税込 2800円
はじめに
古い写真をお持ちの方に多数の写真をお借りしました。
大正時代から昭和中期までの白黒写真をAI画像加工を利用してカラー化してみた。
ギャラリー
-

大正天皇 -

大正天皇(カラー化) -

-

-

-

-

皇居 S33 -

皇居(カラー化) -

国立図書館 S27 -

国立図書館(カラー化) -

筑波山ケーブルカー -

筑波山ケーブルカー (カラー化) -

銚子大橋 S38 -

銚子大橋(カラー化) -

東京湾 S27 -

東京湾(カラー化) -

筑波神社 S30 -

筑波神社(カラー化) -

日光東照宮 S38 -

日光東照宮(カラー化) -

-

撮影場所
- 大正天皇
- 皇居
- 国立図書館
- 筑波山ケーブルカー
- 銚子大橋
- 東京湾
- 筑波神社
- 日光東照宮 など
ギャラリー
-

DVDセット -

DVDセット -

DVDセット -

DVDセット -

CD(ソナタ) -

CD(ソナタ) -

CD(ソナタ) -

CD(オルゴール) -

CD(オルゴール) -

CD(オルゴール) -

CD(オルゴール) -

CD(オルゴール) -

冬のソナタ セット -

クリアファイル 2枚
内容
知人からの依頼となります。
コレクションで集めていたそうです。
どなたか興味のある方へ、お譲りできれば売却したいとのことでした。
私見となりますが、すべて大切に保管していたように拝見できます。
経過劣化はそれなりに見えますが、綺麗な状態に見えます。
韓国語の学習にいかがでしょうか?
話のネタとして、おばあちゃん・お母さんなどにも、お声掛けいただけると有難いです。
DVD BOX
冬のソナタ DVD-BOX vol.1(DVD 3枚組) : 定価14400円
冬のソナタ DVD-BOX vol.2(DVD 4枚組): 定価19200円
CD(ソナタ)
冬の恋歌(ソナタ) サウンドトラック (国内盤): 定価2500円
CD(オルゴール)
冬のソナタ オルゴール・サウンドコレクション: 定価2200円
クリアファイル
ペ・ヨンジュン 2枚
合計 38300円 となります
販売価格
税込 13200円 (税抜12000円)