ホーム
>> ヘッドライン
>>
PC修理のわたなべ
ホーム
>> ヘッドライン
>>
PC修理のわたなべ
| メイン | 簡易ヘッドライン |
 |

|
現在データベースには 510 件のデータが登録されています。
はじめに
ChatGPTと音声で会話をしたいと思った。
アレクサとChatGPTを介して、会話ができることがわかった。
参考サイト
(プログラミング不要)AlexaのChatGPTスキルを作成する方法

準備
Echo Show 5を準備
Amazon Developer アカウント
アレクサにスキル(今回であればChatGPTとの会話アプリ)を登録するために必要なアカウントです。
Alexaを利用しているAmazonアカウントで登録して下さい。
https://developer.amazon.com/ja/
Open AI アカウント
Chat GPTを利用するために必要です。
https://platform.openai.com/signup?launch
参考サイトにしたがって、Alexa×ChatGPTの音声会話を実現した。
結果
考察
ChatGPTと会話ができるようになった。
「Alexa」と呼ばなくても、会話が継続できるようになった。
「ずんだもん」などのキャラクターで返答できるようになったら、より楽しくなると思う。
はじめに
ネット環境が遅いので、改善してほしいと依頼された。
はじめにご訪問した際には、パソコンでスピードテストを試したところ、 10Mbpsしか出ていなかった 。
※インターネット回線の速度テスト

WiFi環境を改善
ONUとモデムを Cat8のLANケーブル で接続
モデムとハブを Cat8のLANケーブル で接続

TP-Link スイッチングハブ 5ポート PoE+ (4ポートPoE+、各30Wまで) 合計40W対応 TL-SG1005LP
0.5m-2本 KASIMO CAT8 LANケーブル カテゴリー8 フラット 40Gbps 2000MHz SFTP RJ45
ハブとWiFi 無線LANルーターを Cat8のLANケーブル で接続

TP-Link メッシュ WiFi 6 ルーター dual band 【 PS5 / ipad/Nintendo Switch/iPhone シリーズ メーカー動作確認済み 】 Alexa 認定製品 スマートテレビ 対応 メッシュWi-Fi無線LANルーター スマートホーム AX3000 (2402+574Mbps) Deco X60 2ユニット
10m KASIMO CAT8 LANケーブル カテゴリー8
Decoをブリッジモードに設定(※モデムにプロバイダー設定済み)

インターネット回線の速度テスト を無線LANで実施したところ、200Mbpsだった。
ハブとローカルPCを Cat8のLANケーブル で接続

インターネット回線の速度テストで1Gbpsが出ました
まとめ
ローカルPCで10Mbpsの回線速度が、WiFi環境を改善することにより、最大1Gbpsまで改善された。
・すべて、 Cat8のLANケーブル で接続
・WiFi無線ルーター WiFi 6規格 メッシュを使用
はじめに
dtab d-01k タブレットのバッテリー交換を依頼された

バッテリー交換
新しいバッテリーの用意

画面を外す

ピックやマイナスドライバなどで、少しずつ?がしていく。
両面テープで密着しているため、ドライヤーなどで温めながら、ゆっくりと剥がしていった。
モニターの分離

バッテリーケーブルを外す


モニターケーブルを外す


バッテリーを外す

両面テープにて強力に付着しています。
はじめは、ゆっくりと着実に剥がしていく。
ある程度剥がせて来たら、指で剥がせるようになった。

バッテリー交換終了
新しいバッテリーに交換し、ケーブルを付け直した。

はじめに
yayoiMixの生成画像を試してみると、日本人の人物を綺麗に表現できた。
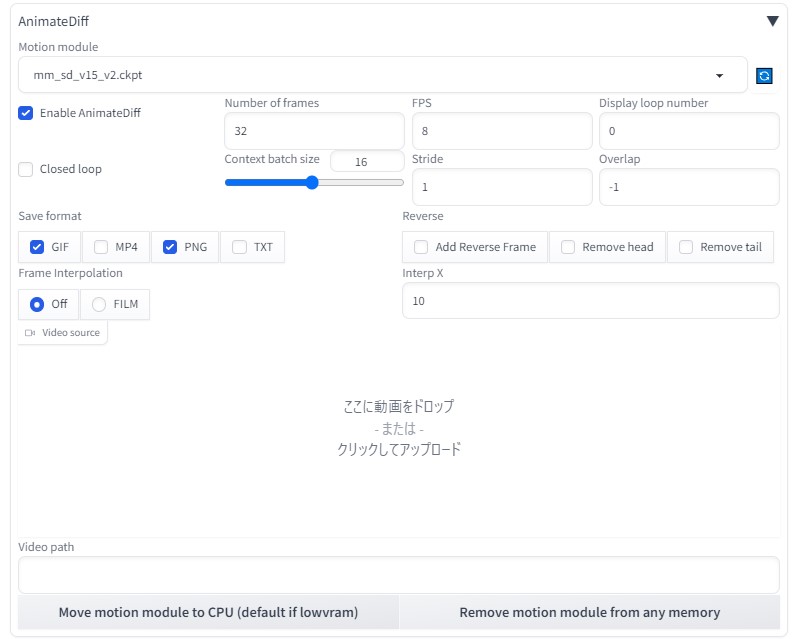
今回は、yayoiMixにて、sd-webui-AnimateDiff AI動画にチャレンジしてみました。
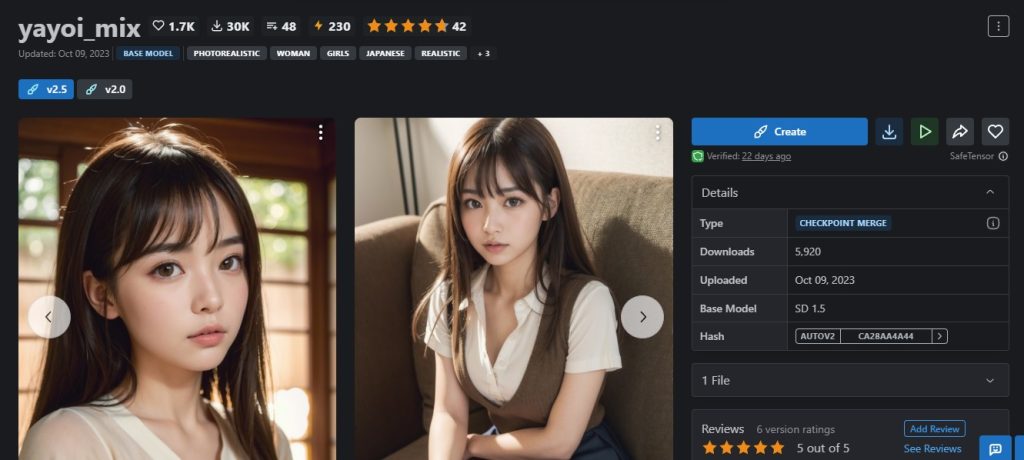
→ CIVIT AI (yayoi_Mix) ?から、ダウンロード可能
AnimateDiff (txt2img)
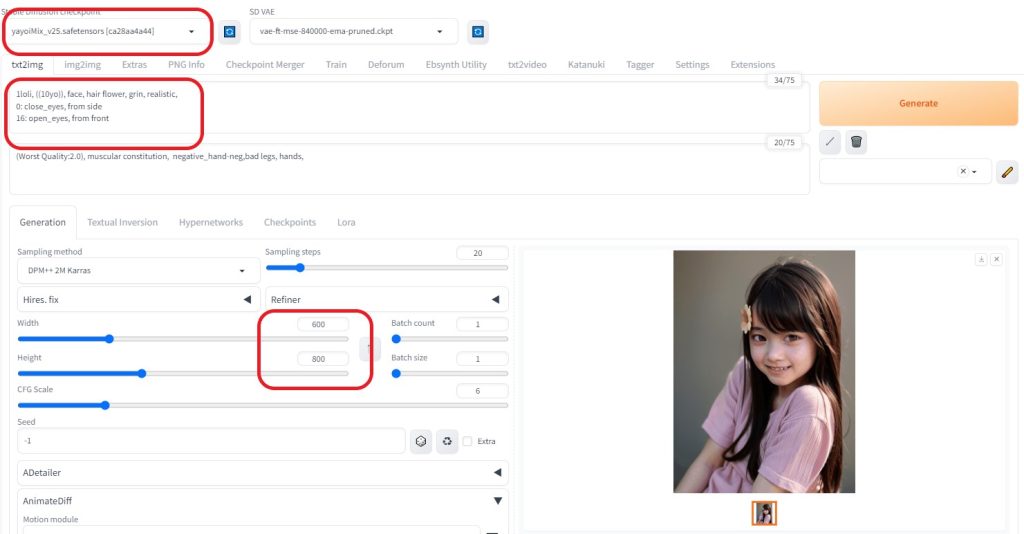
設定内容
※今回は、かわいらしい小さい女の子を表現できたらと思います
モデル:yayoiMix
プロンプト:
1loli, ((10yo)), face, hair flower, grin, realistic,
0: close_eyes, from side
16: open_eyes, from front
※AnimateDiffでは、呪文の単語数が少ないほうが、動きのある動画を表現できるように感じます。
大きさ:600×800
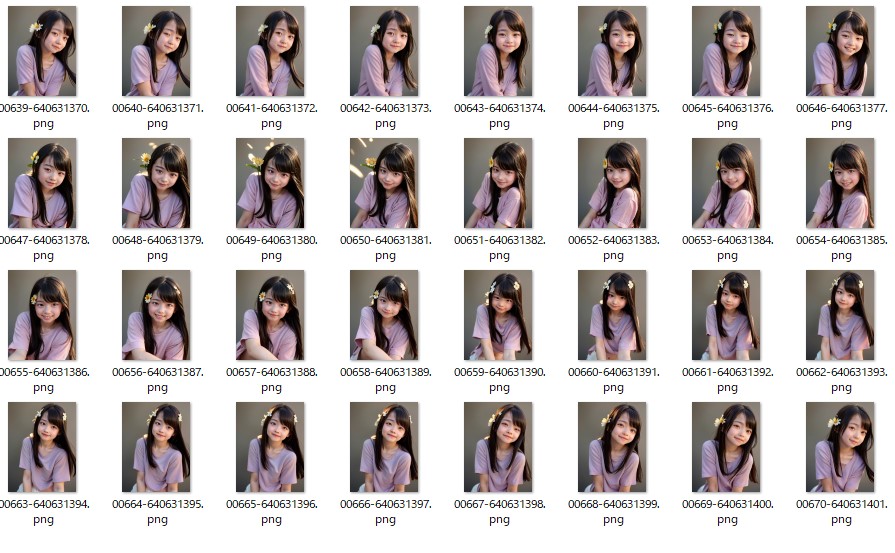
生成された32枚の画像
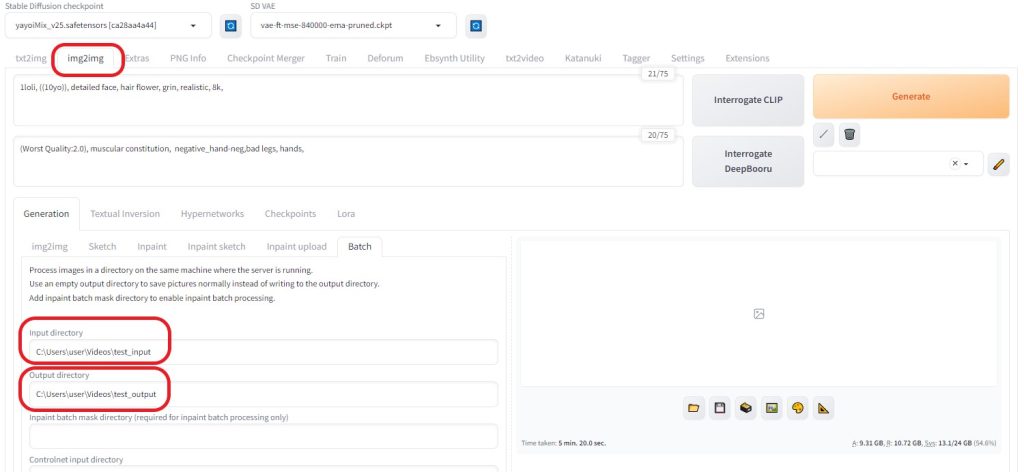
各画像をより綺麗に(img2img)
img2imgを利用し、生成された画像をより綺麗にしてみる。
- ピクチャフォルダに「test_input」フォルダを作成
- output用に「test_output」フォルダを作成
「test_input」フォルダに先ほど生成した32枚の画像をコピーする
「 Batch 」タブを選択し、以下のような設定にした。
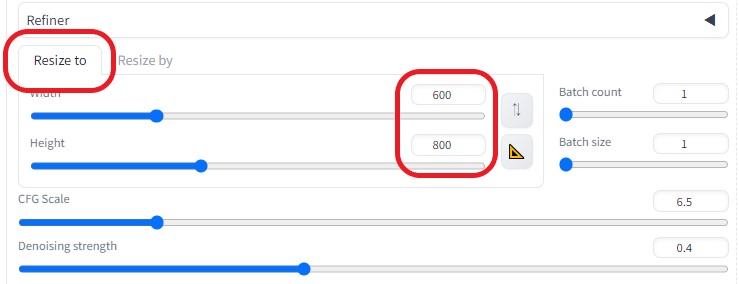
Resize to
※画像の大きさを作成した画像の大きさに合わせる(600×800)
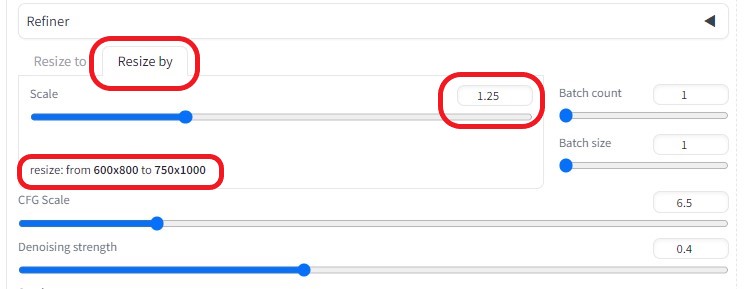
Resize by
※大きさを1.25倍に拡大(750×1000)
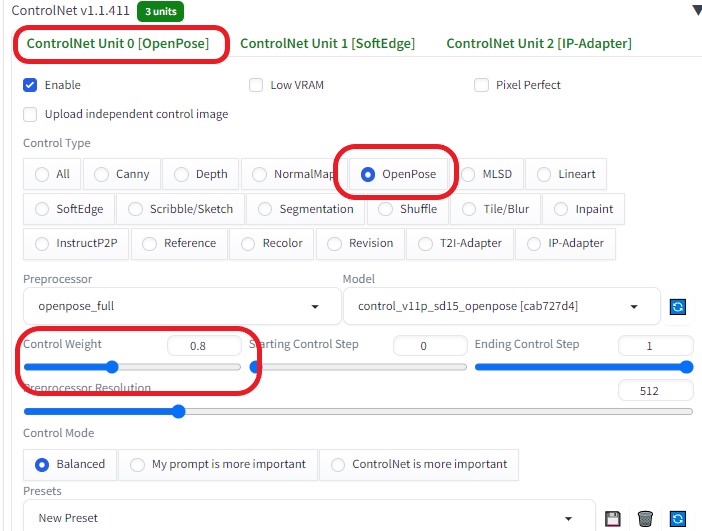
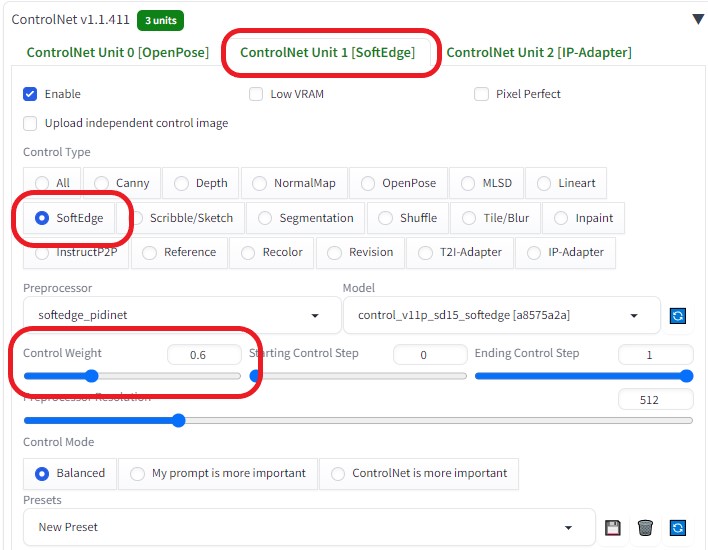
ControlNetを以下のように設定し、各画像の相関性を合わせるようにした
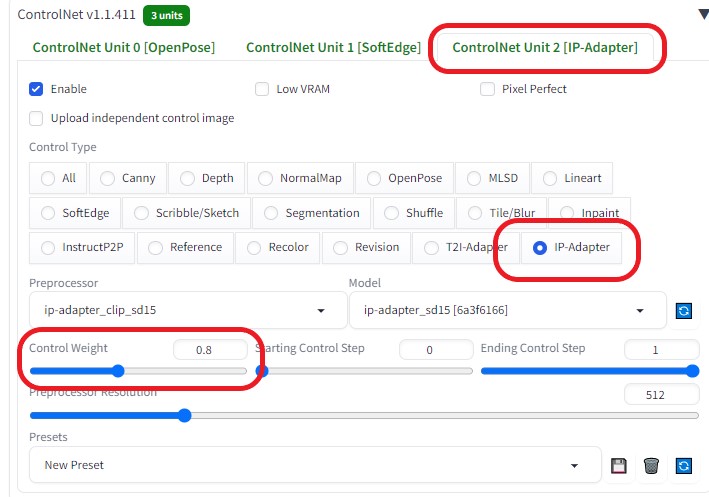
生成すると「test_output」フォルダに32枚の画像が生成される
動画生成(FILM使用)
生成した「test_output」フォルダの32枚の画像を FILMで綺麗な動画に変換 しました。
FILMの詳細は、以下をご確認ください。

動画の再生速度を変更(ffmpeg使用)
動画を2倍速
ffmpeg -i input.mp4 -vf setpts=PTS/2 -af atempo=2 output_fast.mp4
「-vf setpts=PTS/2 -af atempo=2」の箇所で、動画のテンポを変更
「-vf setpts=PTS/2」で動画の速度が2倍
「-af atempo=2」で音声の速度が2倍
※今回は、生成した動画(input.mp4)を12倍速に変更(cmd使用)
ffmpeg -i input.mp4 -vf setpts=PTS/12 -af atempo=12 output_fast.mp4

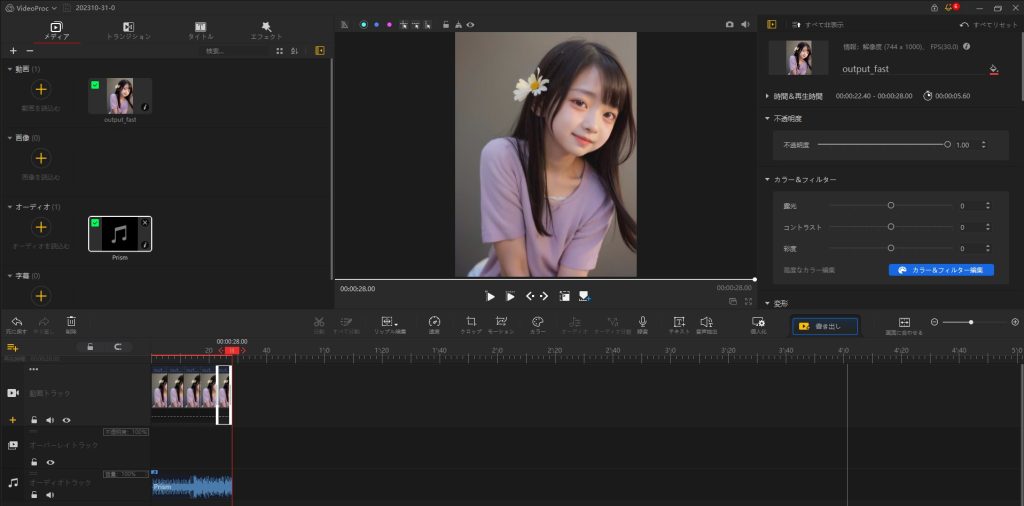
編集動画(BGM付き)
【 VideoProc Vlogger 編集画面】
考察
いろいろなモデルが登場してきました。
日本人モデルも以前に比べると多様な人物を表現できるようになりました。
くわえて、思い通りの動きができるようになれば、短編ムービーも可能になっていけると思います。
以前と比べると、LoRAを使用しなくても、かわいらしい女の子を表現できたのも画期的に感じます。
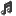 ポッドキャスト :
video/mp4
ポッドキャスト :
video/mp4
はじめに
AnimateDiffにある FILM の項目に興味をもった。
※FILM(Frame Interpolation for Large Motion)
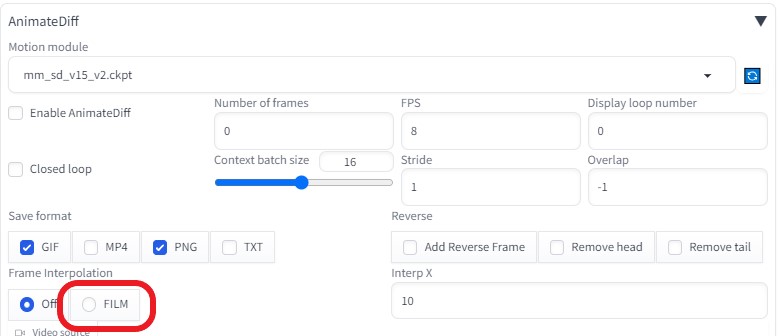
2枚の画像を入力するだけで、その間の動きを補間して、動かすという技術だそうです。
参考サイト
画像をぬるぬる動かすFrame Interpolation for Large Motion【FILM】

FILMインストール
Windows インストール手順

github
Anaconda
- Anacondaをインストール
- CMD.exe PromptのLaunchから起動
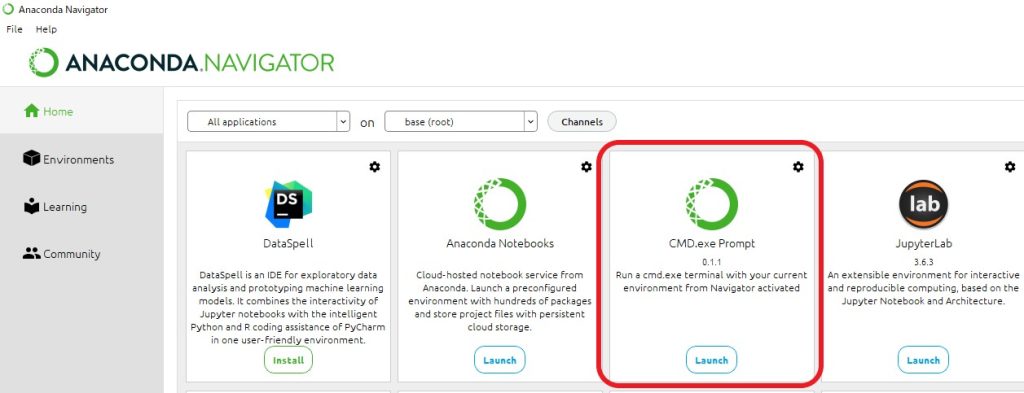
pip install --ignore-installed --upgrade tensorflow==2.6.0
python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
frame-interpolation> に「 pretrained_models 」フォルダを作成し、以下のデータをインストールする
git clone https://github.com/google-research/frame-interpolation
cd frame-interpolation
pip install -r requirements.txt
conda install -c conda-forge ffmpeg
FILM実行
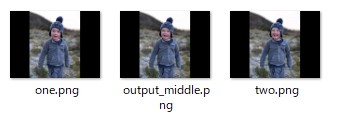
中間フレーム補間
python -m eval.interpolator_test --frame1 photos\one.png --frame2 photos\two.png --model_path <pretrained_models>
\film_net\Style\saved_model --output_frame photos\output_middle.png
多数のフレーム間補間
AI画像を生成
同様な画像を少しずつ変化を加えて5枚生成し、4枚を逆順に加える。
画像01.png?09.pngを「 photos 」フォルダ以下に配置
python -m eval.interpolator_cli --pattern "photos" --model_path <pretrained_models> \film_net\Style\saved_model
--times_to_interpolate 6 --output_video

完成動画
ポッドキャスト :
video/mp4
はじめに
最新のBRAV7がリリースされました。
最新BRAV7にて、sd-webui-AnimateDiff AI動画にチャレンジしてみました。
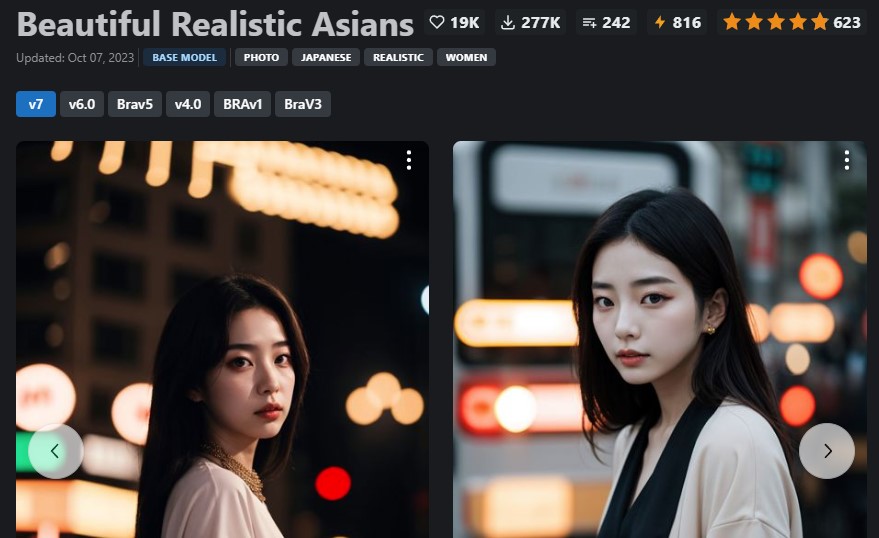
→ CIVIT AI (BRAV7) から、ダウンロード可能
BRAV7
Beautiful Realistic Asiansの新モデルは、以下のサイトを参考にしました。
待望のBRAV7がリリース!Beautiful Realistic Asiansの新モデル・プロンプトなど
roop用顔画像 (BRAV7使用)
Beautiful Realistic Asians( BRA )から、待望の新モデル V7 がリリースされました。
早速、生成してみました。
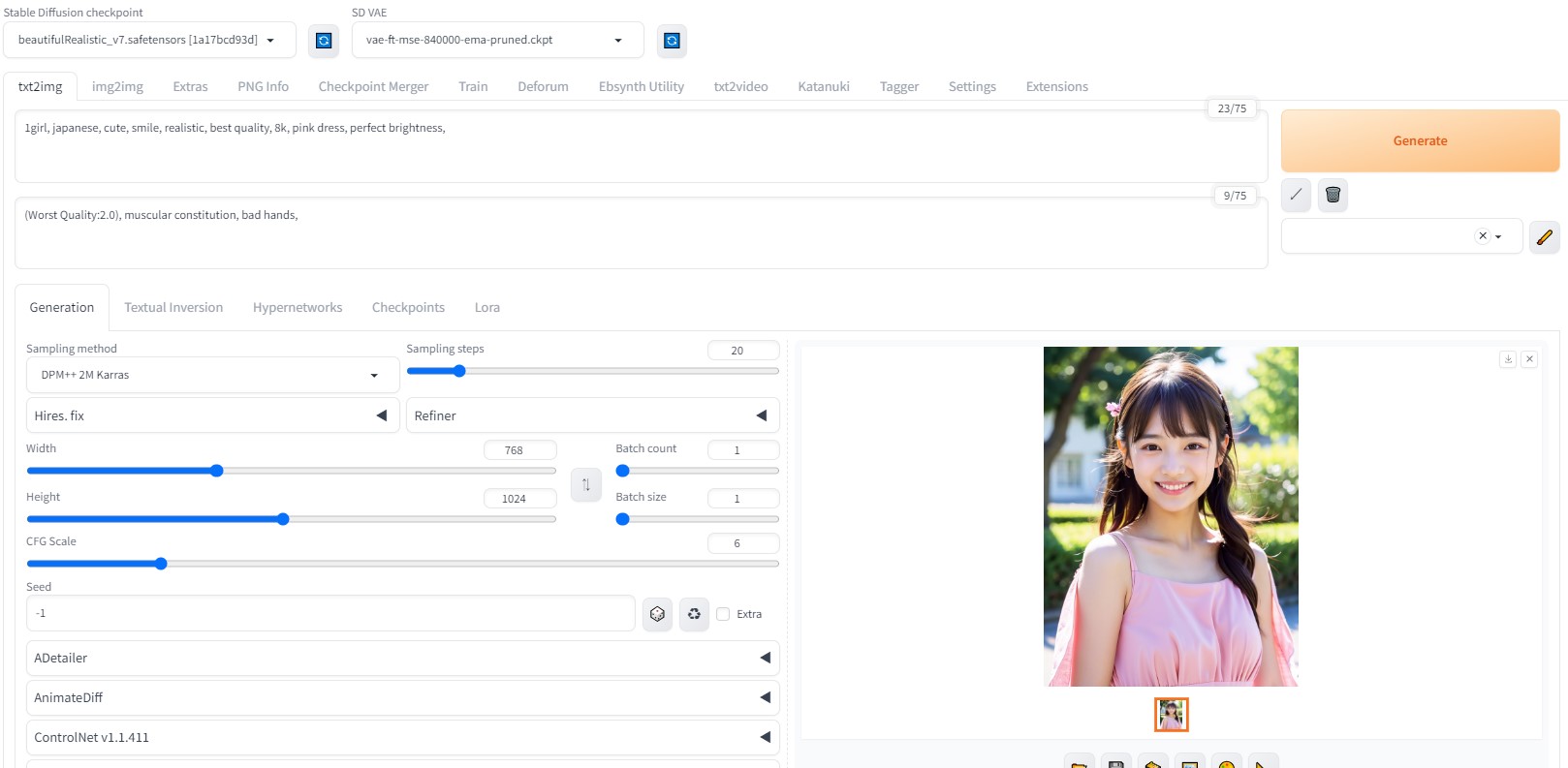
生成画像

画質も一段と綺麗になりました。
参考サイト(AnimateDiff)
AIでアニメーション制作!AnimateDiffの基本的な使い方【Automatic1111】

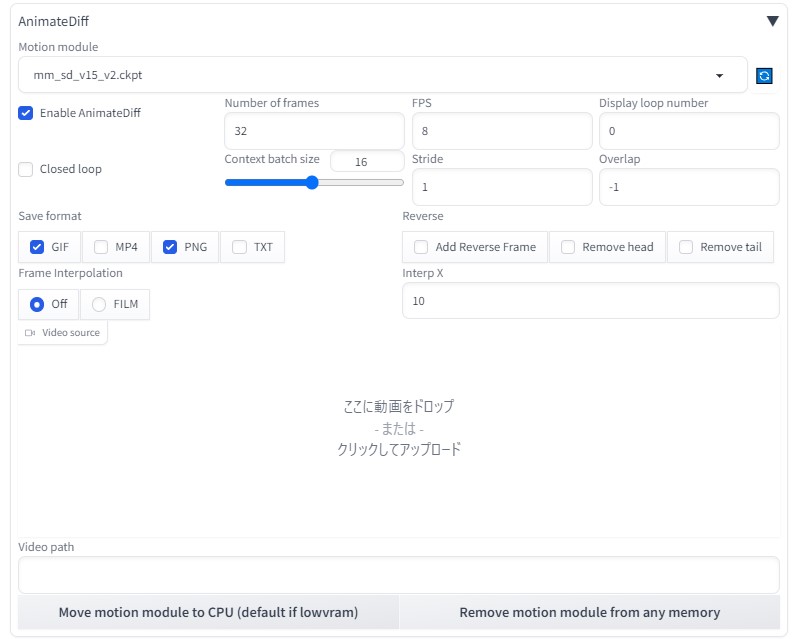
AnimateDiff (txt2img)
設定方法などは、以下をご覧ください。

モデル:beautifulRealistic_v7
プロンプト:
1girl, japanese, cute, smile, realistic, best quality, 8k, pink dress, perfect brightness,
0: standing
10: close_eyes
16: walking
20: open_eyes
<lora:sweet_dress_style2_v1:0.8> ,
設定内容
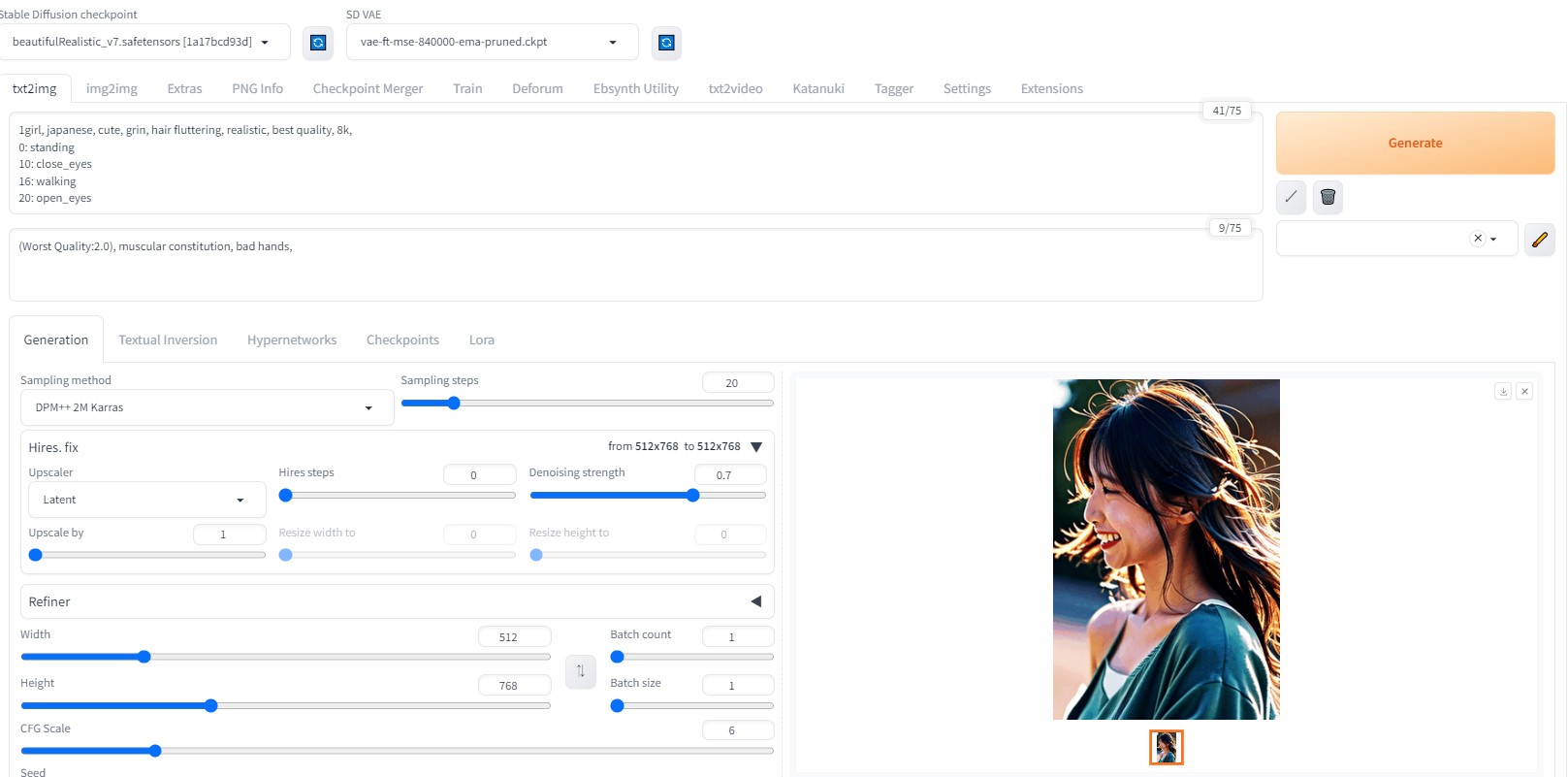
FPS8フレーム、総数32フレーム(4秒)
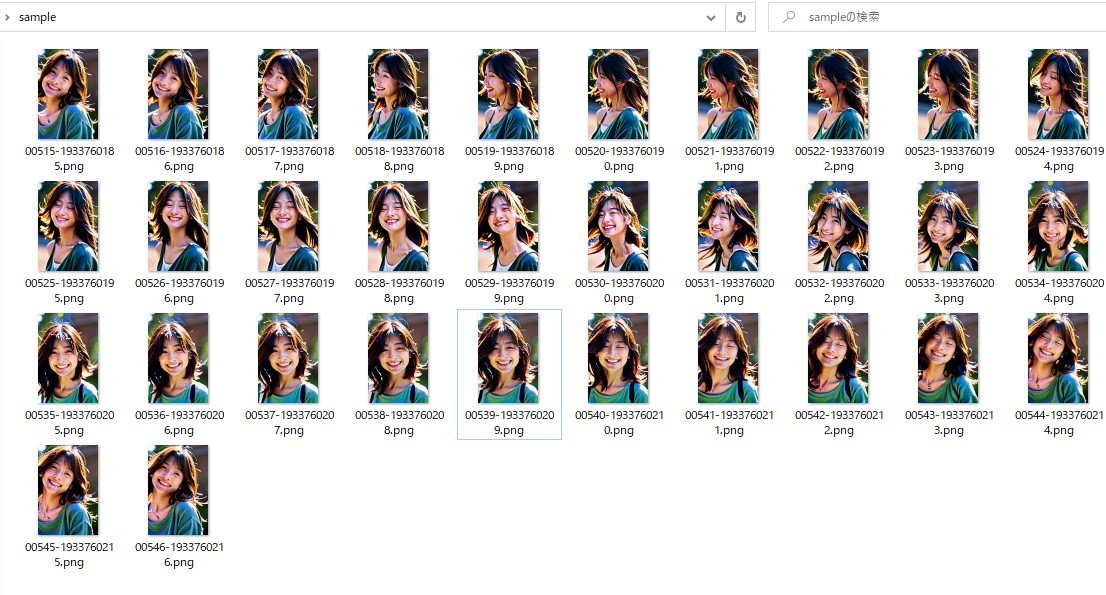
生成された32枚の画像
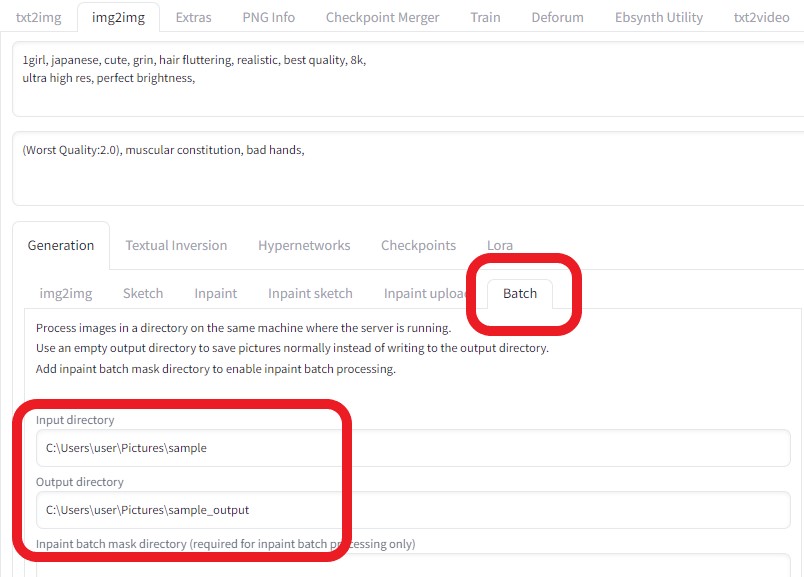
各画像をより綺麗に(img2img)
img2imgを利用し、生成された画像をより綺麗にしてみる。
- ピクチャフォルダに「 sample 」フォルダを作成
- output用に「 sample_output 」フォルダを作成
「 sample 」フォルダに先ほど生成した 32枚の画像をコピー する
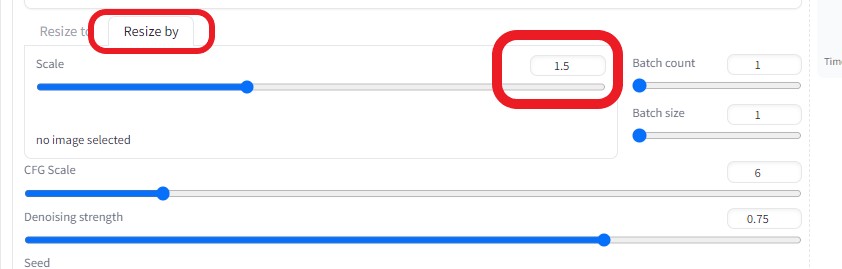
「Batch」タブを選択し、以下のような設定にした。
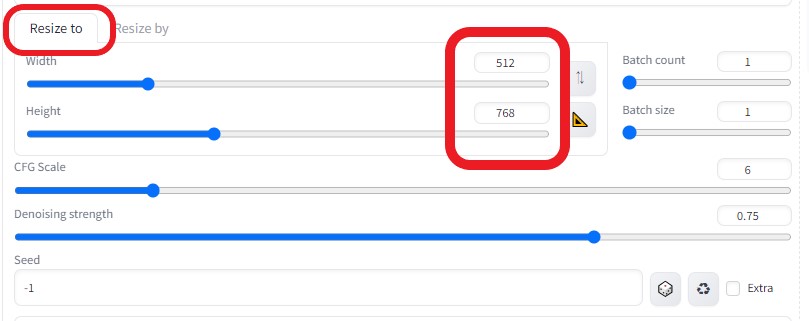
より綺麗な画像に変換したいので、画像サイズを1.5倍に上げた
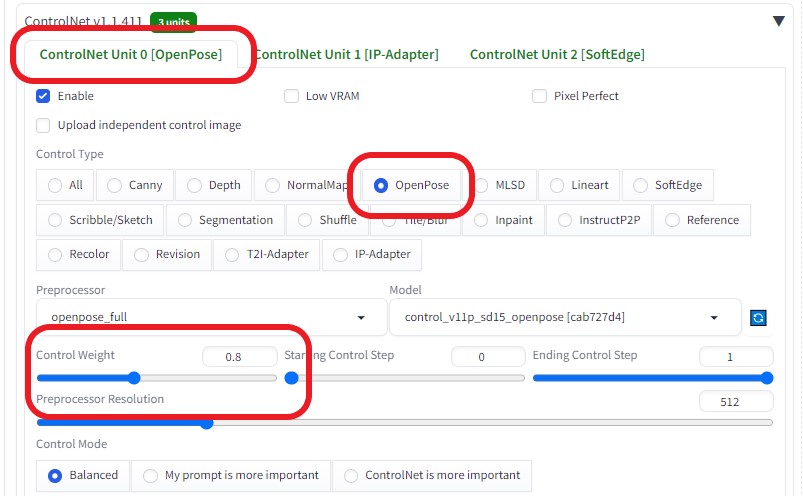
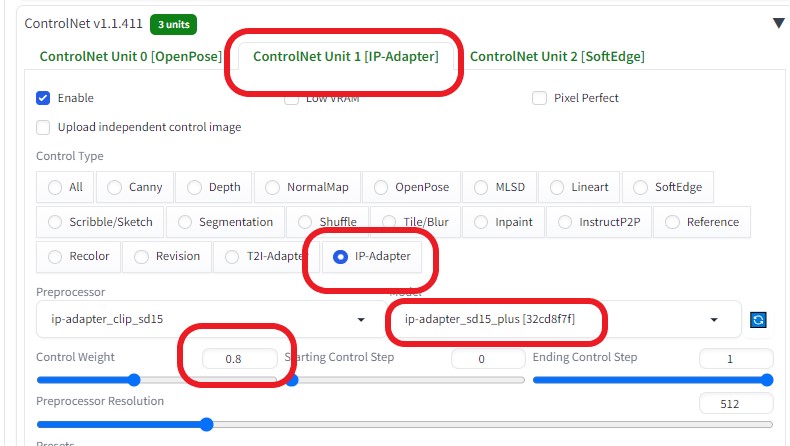
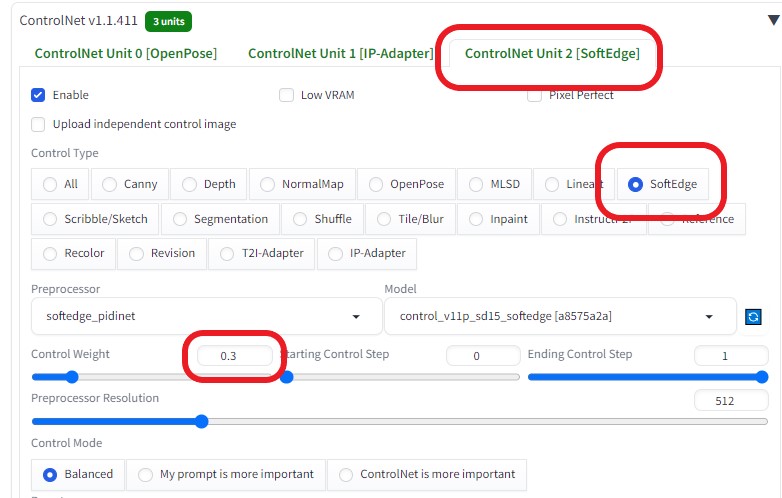
ControlNetを以下のように設定し、各画像の相関性を合わせるようにした
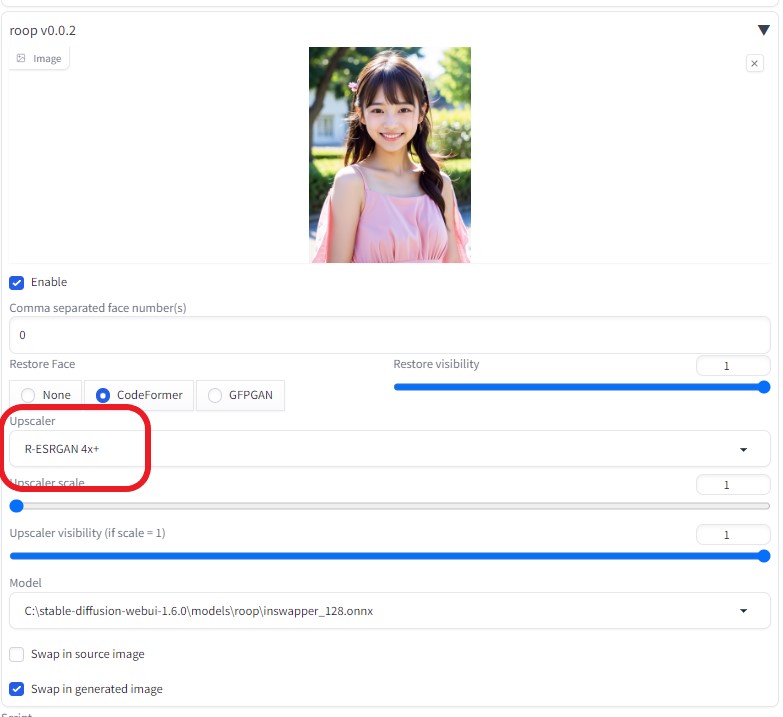
BRAV7で生成したAI画像をroop に 用いた
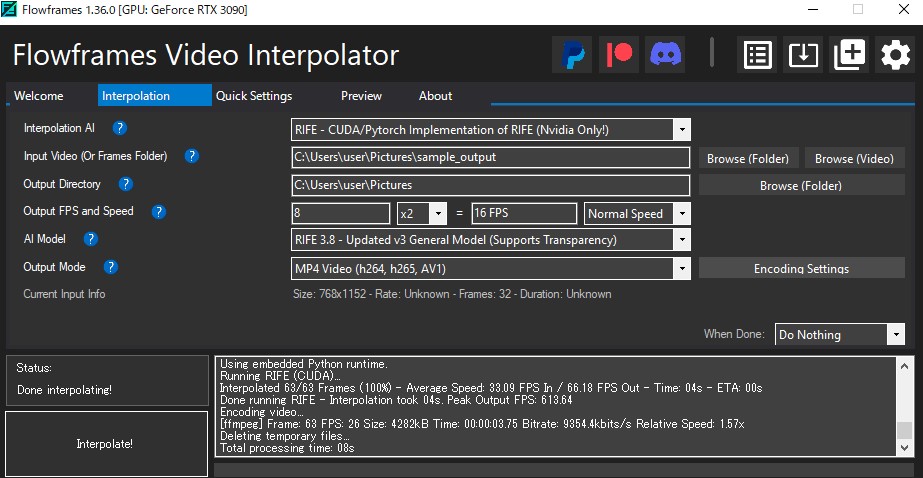
連続画像を動画に変換
連続画像を動画に変換する
- Flowframes を使用
詳細は、以下を参考にしてください
編集などの設定は、以下の通りです。
完成動画
sample_output-2x-RIFE-RIFE3.8-16fps.mp4
YouTube用 編集動画
YouTube用に編集した。
VideoProc Vlogger を使用し、BGMやモーション設定などを追加した。
音源
フリーBGM「センチメンタル・リバー (instrumen…」

【 VideoProc Vlogger 編集画面】
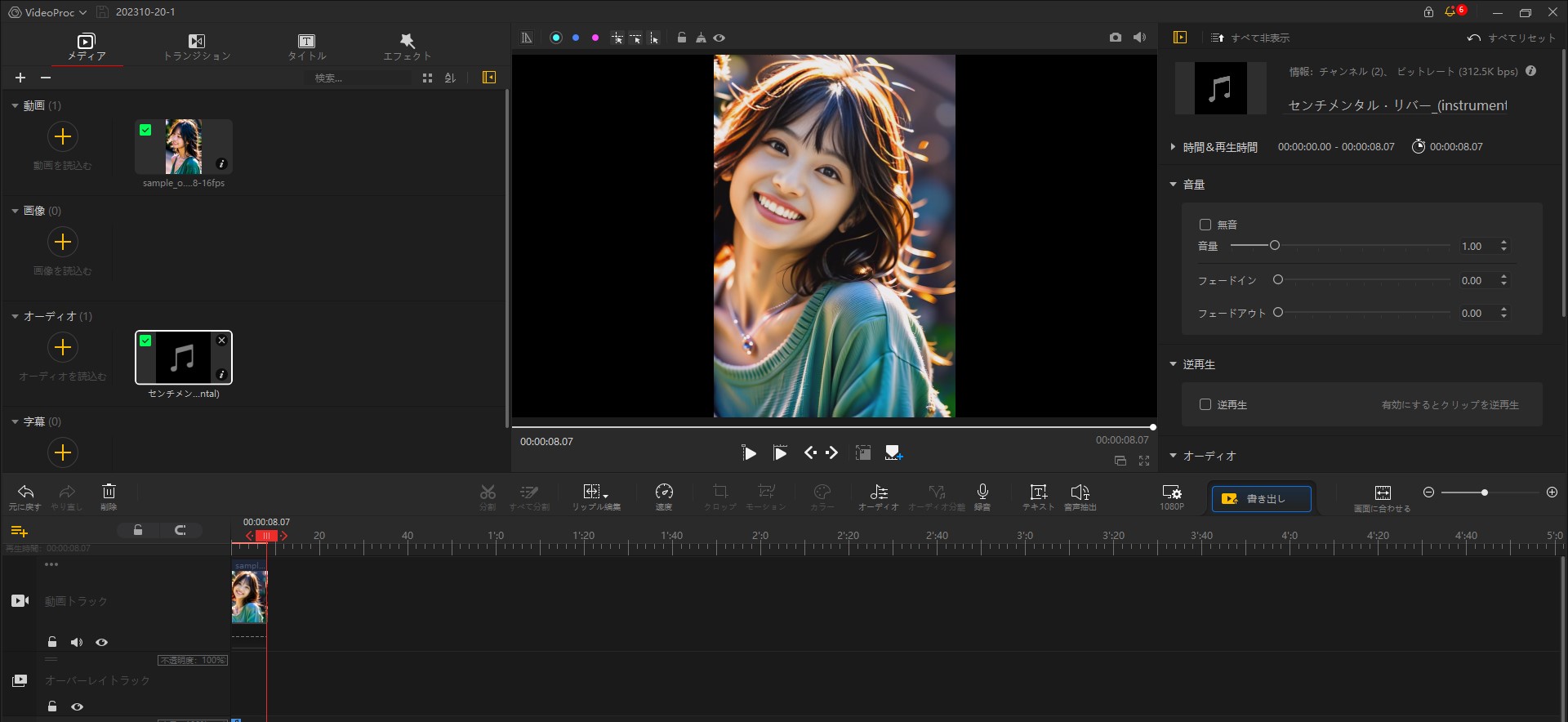
完成動画(YouTube用)
※高画質に変更してから 、 ご確認ください
↓(高画質) 1080p60HD で確認するとより綺麗な動画になります↓
ポッドキャスト :
video/mp4
はじめに
前回、sd-webui-AnimateDiff AI動画 (img2img)で動画を生成した。
しかし、AnimateDiffのみを使用した際の滑らかな(ヌルヌルした)動画を作成することができなかった。
そこで、animatediff+openposeで何かできないかと検索していたところ、以下のようなサイトを見つけた
ComfyUIにて作成していたため、sd-webuiで生成できるように考案した。
準備
Openpose画像(openpose_samples.zip)を以下のサイトから、ダウンロードする
※下記サイト様より、Openpose画像をお借りしました
【AIアニメ】ComfyUIとControlNetでAnimateDiffを楽しむ

【こちらからもダウンロード可能( openpose_samples.zip )】
連続画像を動画に変換する
Openpose画像を動画にするため、Flowframesを使用した

編集などの設定は、以下の通りです。
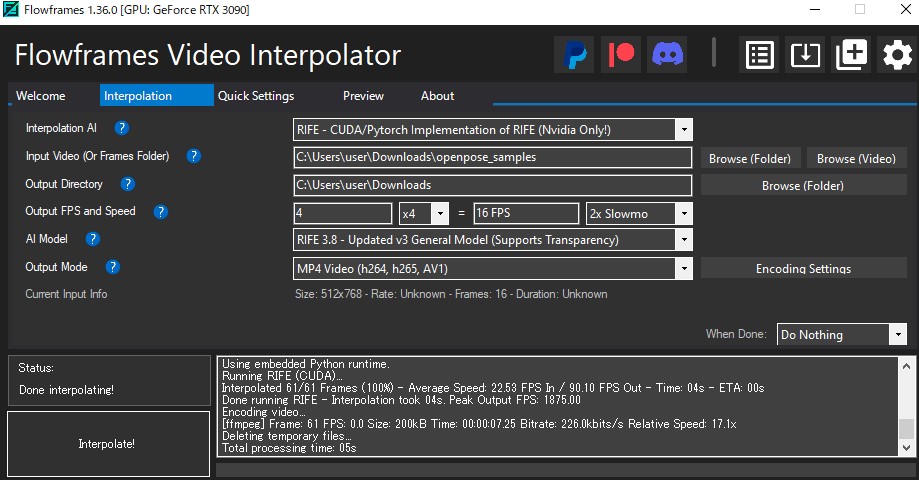
Openpose画像を動画にした
※ゆっくりバージョン
openpose_samples-4x-RIFE-RIFE3.8-16fps.mp4
動画生成
画像準備
モデル: BracingEvoMix_v1.safetensors
プロンプト:
1girl, grin, smile,standing,hair fluttering, tilting head,wave hand,perfect light,
pink dress, on stage,realistic, best quality, <lora:sweet_dress_style2_v1:0.8> ,
Sampling method: DPM++ 2M Karras
Hires. fix:1.2
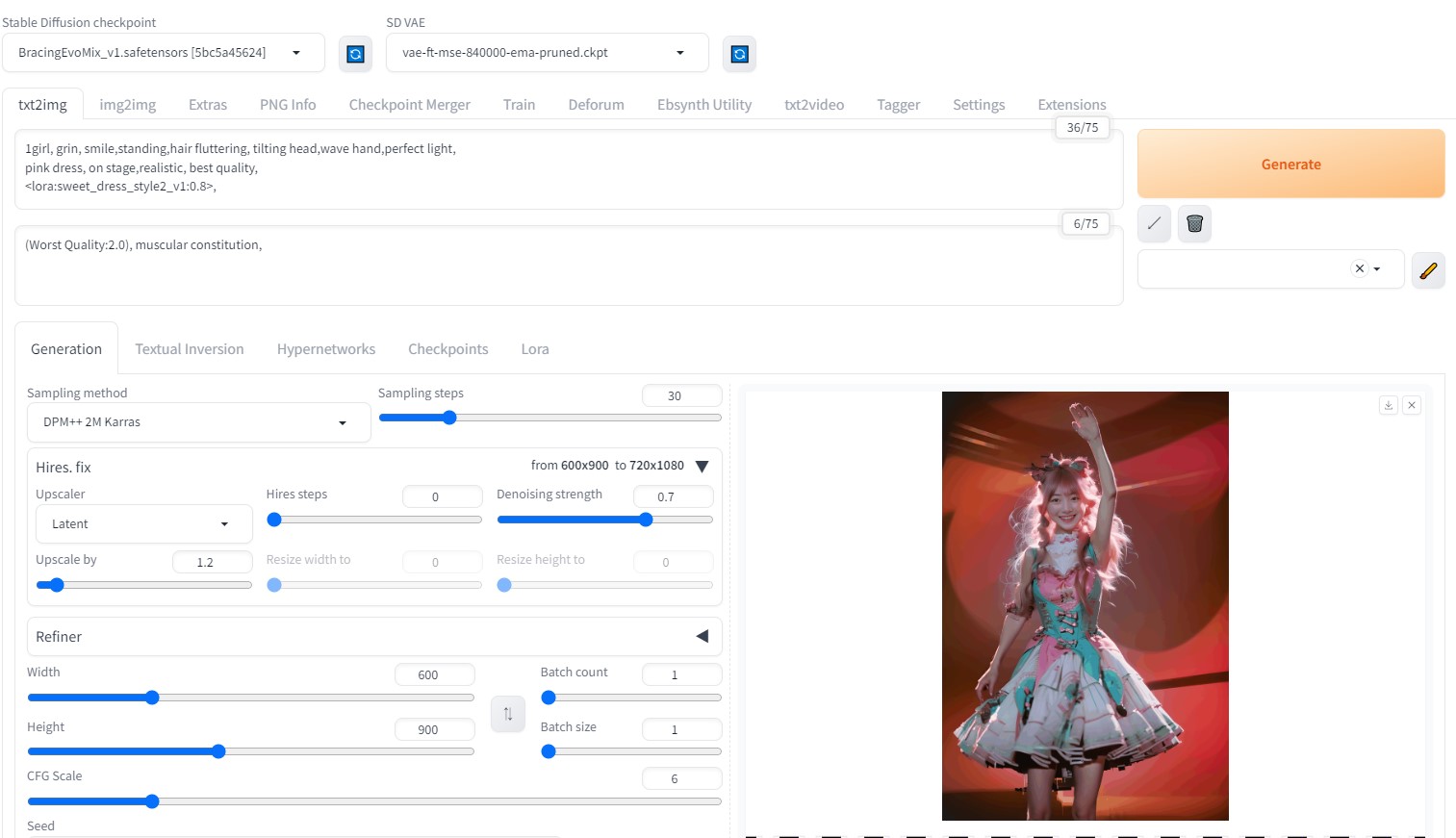
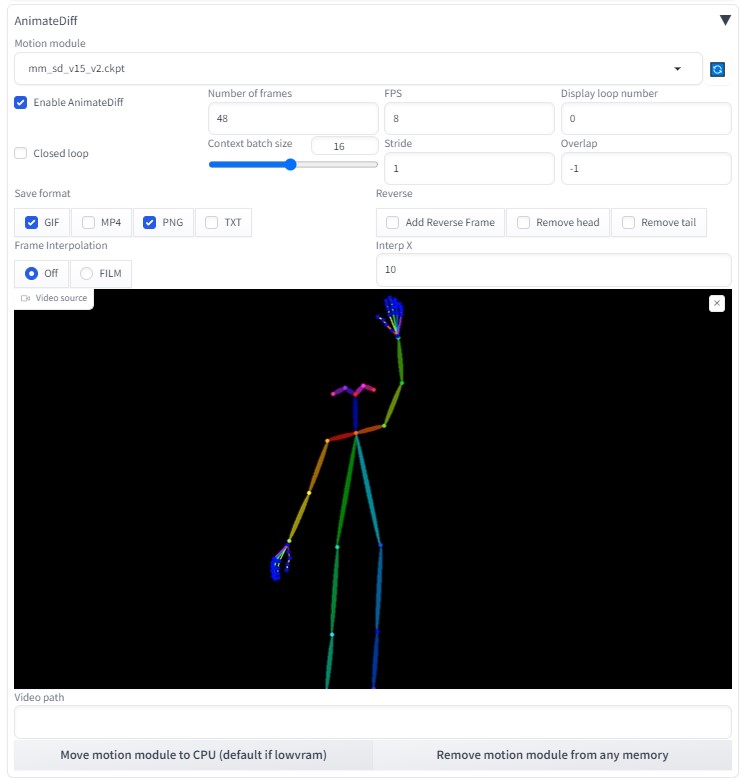
Number of frames:48 (6秒)
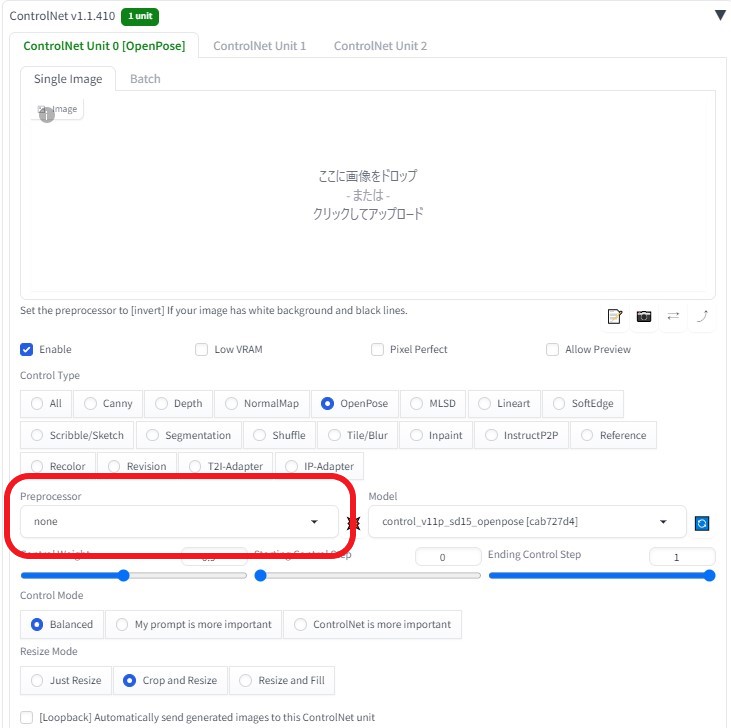
ControlNetにて、「OpenPose」を使用
動画元が、 OpenPose 動画のため、Preprocessorを 「 none」 に変更 (←※重要)
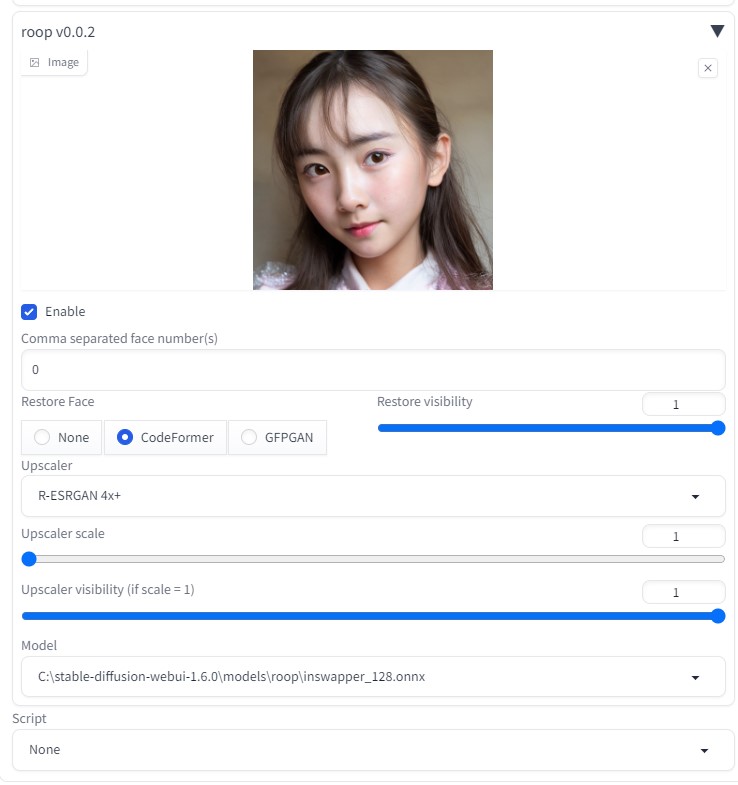
roopで顔を固定する (Upscaler scale は R-ESRGAN 4x+ 選択)
完成動画
VideoProc Vlogger使用(BGM追加など)
考察動画
今回作成したAI動画と元のOpenPose動画の比較
考察
連番画像を動画に変更することにより、動作をある程度固定した状態で、綺麗な動画(ヌルヌルした動画)を生成することができた。
なおかつ、Flowframesソフトを活用することにより、OpenPoseを動画にすることも簡単に作成できた。
はじめに
前回、sd-webui-AnimateDiff AI動画を生成できた。
img2imgを用いても生成できることが分かった。
画像を2枚用意することによって、最初と最後のポーズを決められる。
これにより、連番のような画像を用意することにより、継続する動画を作成することができるようになると思われる。
参考サイト
sd-webui-AnimateDiffをイメージtoイメージで使う方法【AIアニメーション】
txt2img
連番画像の準備
連番画像生成(6枚)
txt2imgにて、似たような画像(連番画像)を6枚生成
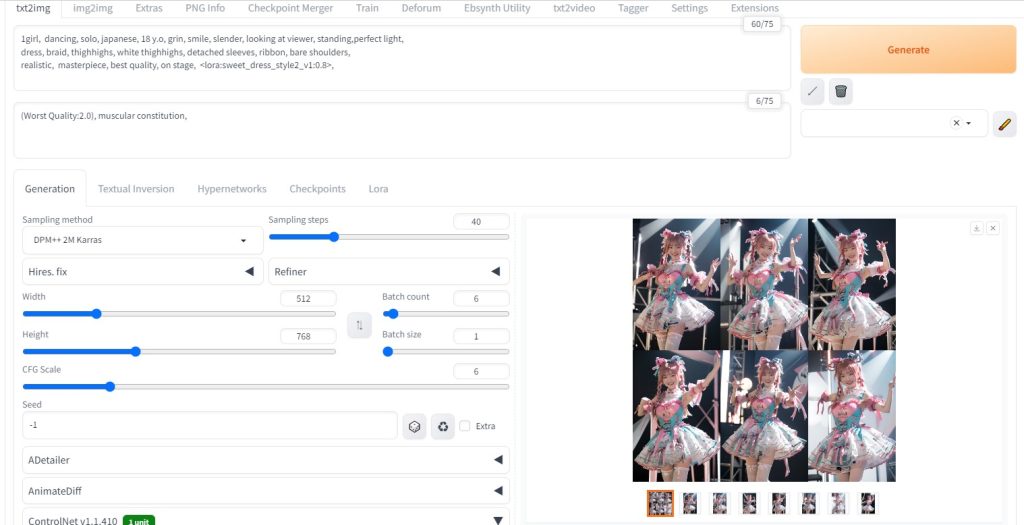
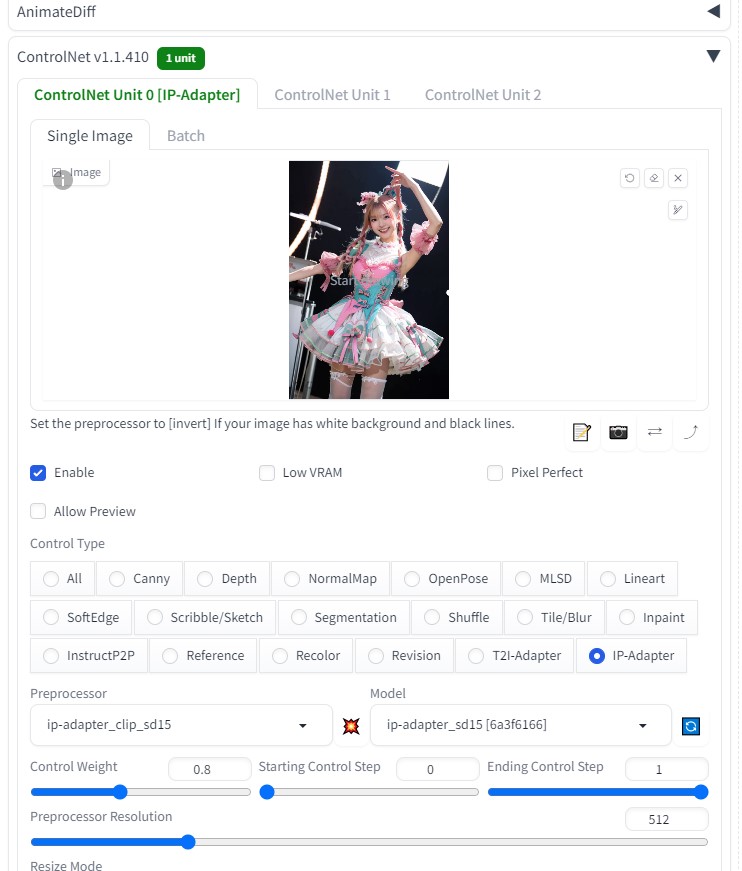
ControlNet> IP-Adapter で衣装をある程度固定する
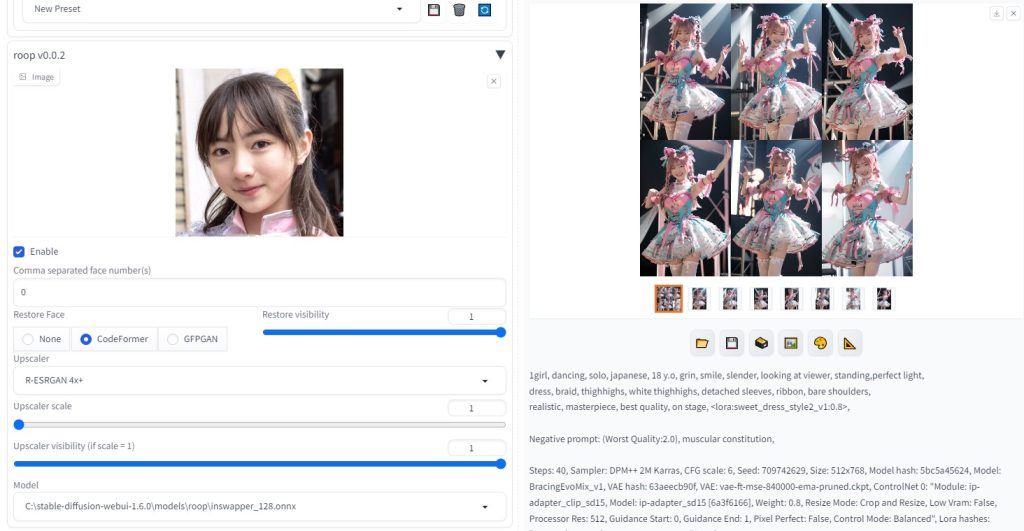
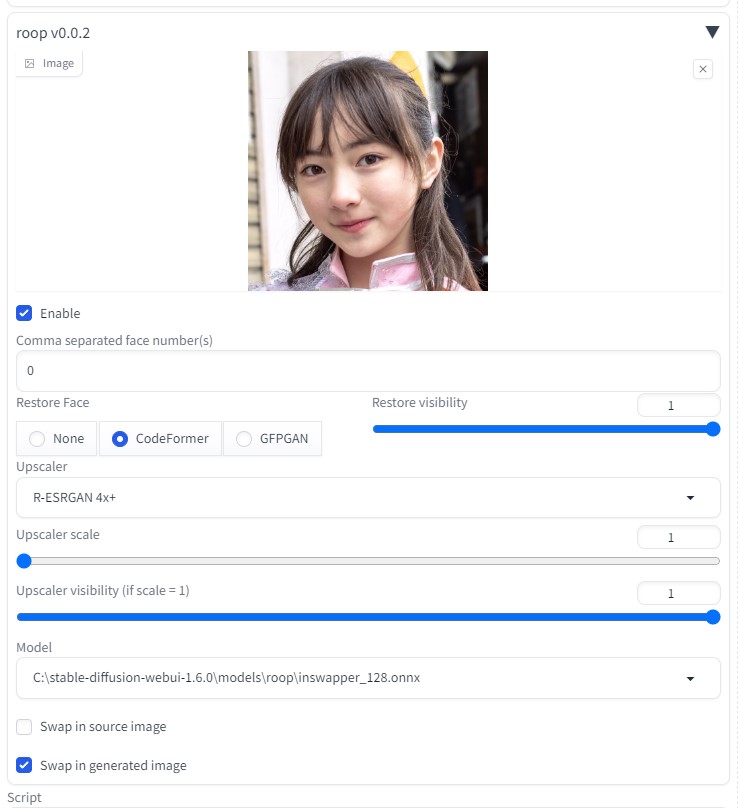
roopにて、顔画像をある程度固定する。
生成されたAI画像に連番を振る

img2img
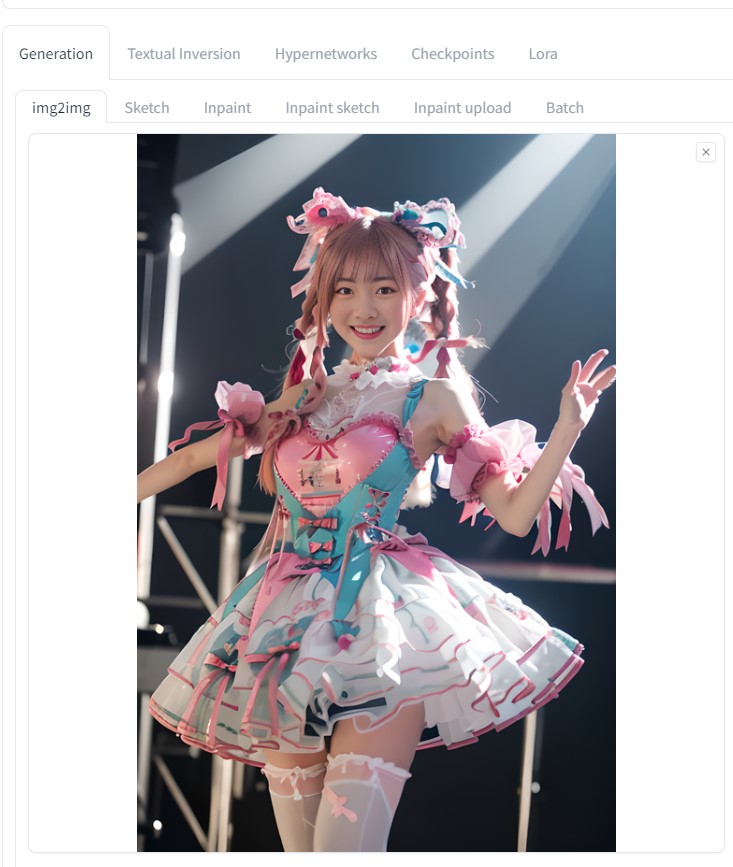
先ほど作成した、「 001.png 」をimg2imgに貼り付ける (動画 最初の画像 )
他の設定などは、以下の通りです。
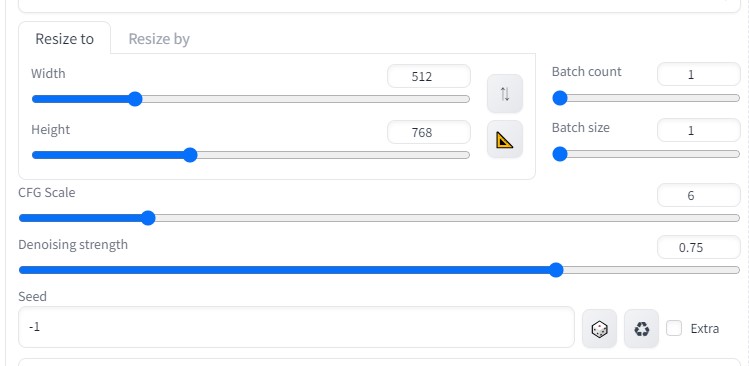
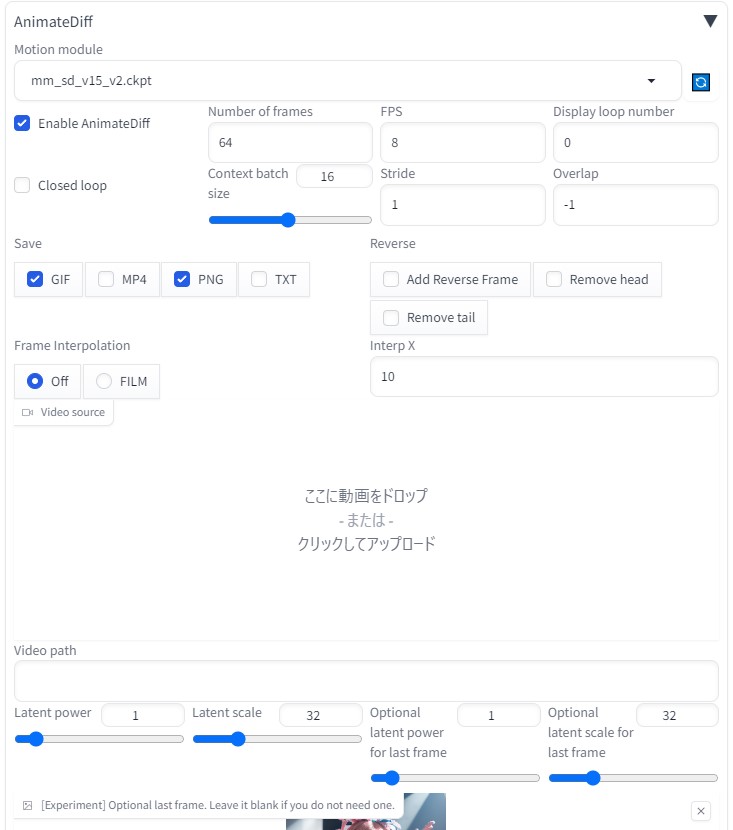
Latent power より下の場所に、「 002.png 」をimg2imgに貼り付ける(動画 最後の画像 )
roopにて、顔画像をある程度固定する。
生成途中の画像は、以下のようになる。
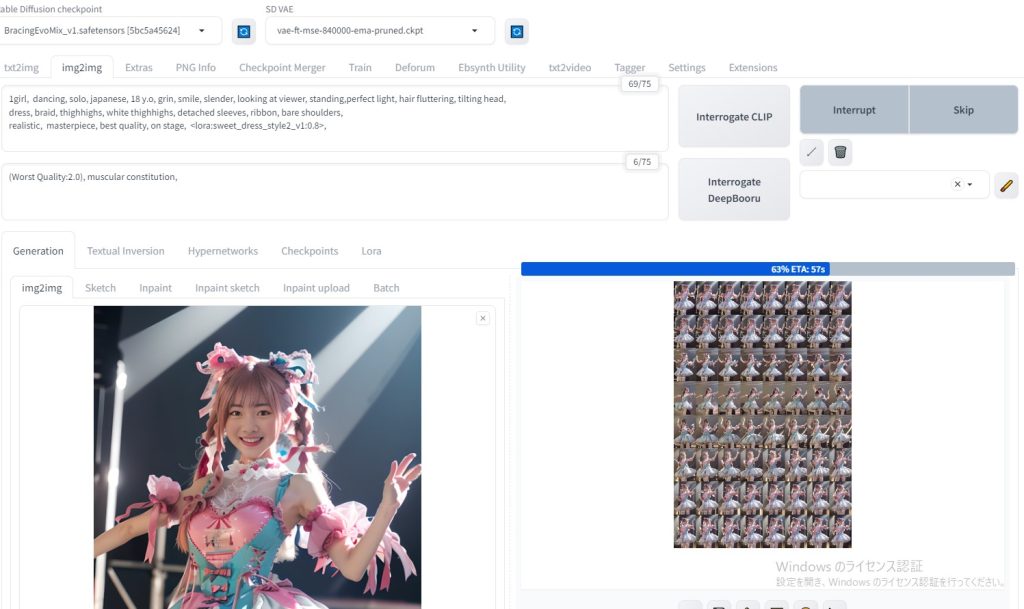
1つの動画生成を終了後、 最初の画像 と 最後の画像 を変更する
最初の画像 を「001.png」から「 002.png
」にする
最後の画像 を「002.png」から「 003.png 」にする
これを連番ごとに変更することにより、動画の継続性が保たれる。
作成したい動画の最後のフレームを、最初の画像に戻すとループ状に動画が動く
一番最後の動画生成の 最後の画像 を「 001.png
」にすることにより、全体の動画がループ状となる。
最初の画像 を「 006.png 」にする
最後の画像 を「 001.png 」にする
動画編集
img2imgで生成した6つの動画を編集ソフトでまとめる
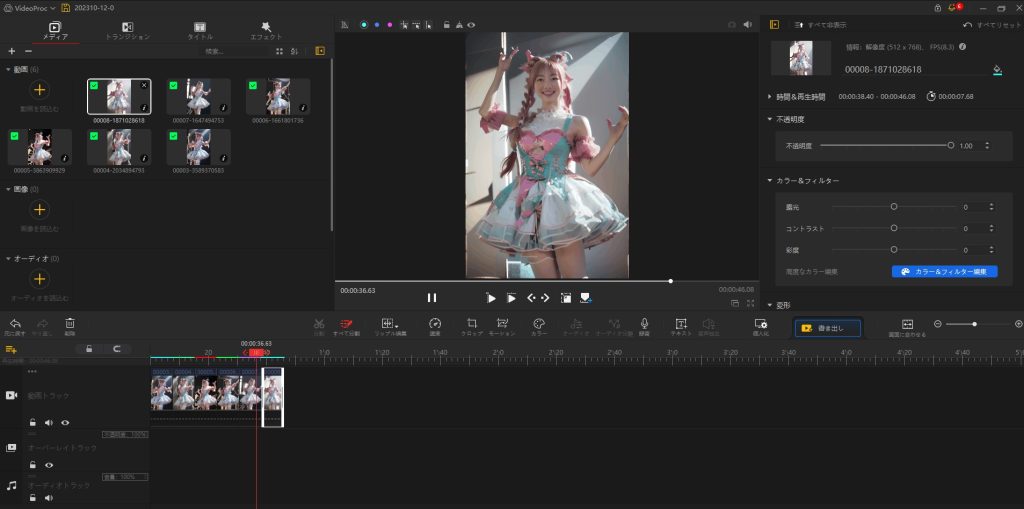
これで、1つの動画を生成できた。
EBsynth生成(背景交換)
背景をEBsynthを用いて変更する
詳細は、以下をご覧ください。

動画編集 (BGM追加など)
VideoProc Vlogger 使用(BGM追加、フォーカスの動き、ダンスのスピード速度の変更など)
音源(フリー素材): また明日
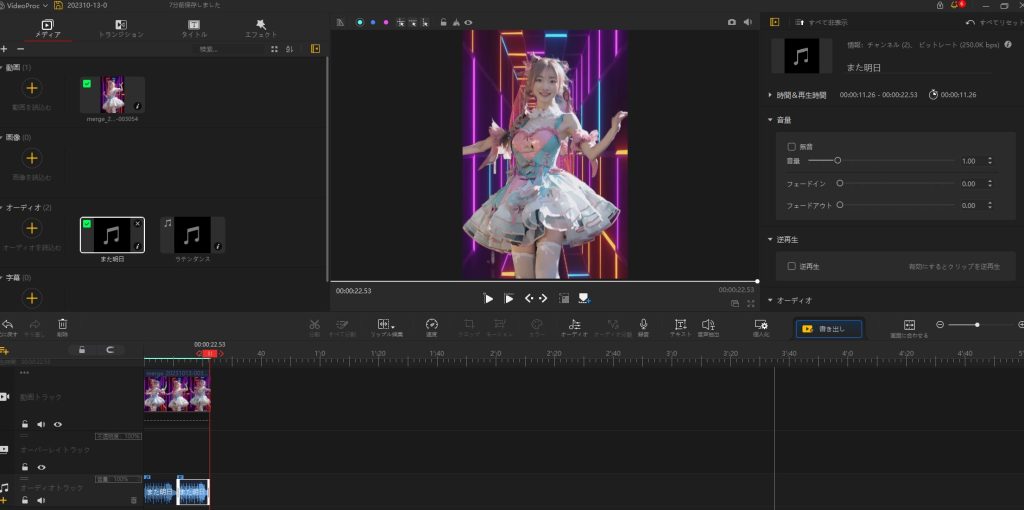
完成動画
ポッドキャスト :
video/mp4
はじめに
AIアニメーションがさらに向上した。
- AnimateDiff
PoseMy.Art
FFmpeg
EBsynth
VideoProc Vlogger
参考サイト
【必見】Control netやdeforumと連携したsd-webui-AnimateDiffのアップデートを確認しよう【AIアニメーション】
動画生成
AnimateDiff
AnimateDiffは、以下をご覧ください。
PoseMy.Art
Opening video を作成する。
PoseMy.Artサイトより、ダンスムービーを作成。
Windows10の標準機能にて、画面録画できます。

作成したダンスムービーは以下の通りです。
Taggerの設定
ダンス衣装プロンプトをTaggerで生成
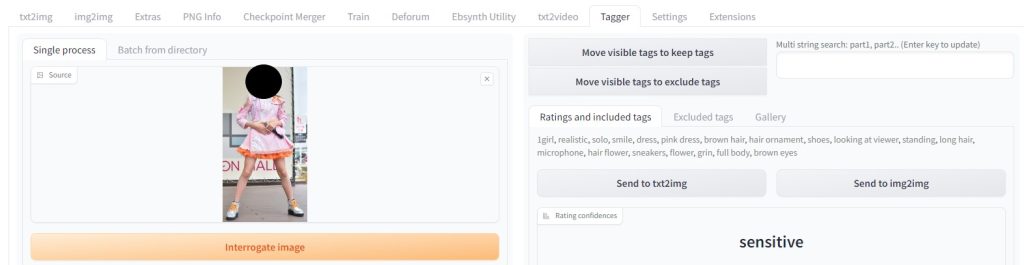
tagger:1girl, realistic, solo, smile, dress, pink dress, brown hair, hair ornament, shoes, looking at viewer, standing, long hair, microphone, hair flower, sneakers, flower, grin, full body, brown eyes
AnimateDiffの設定
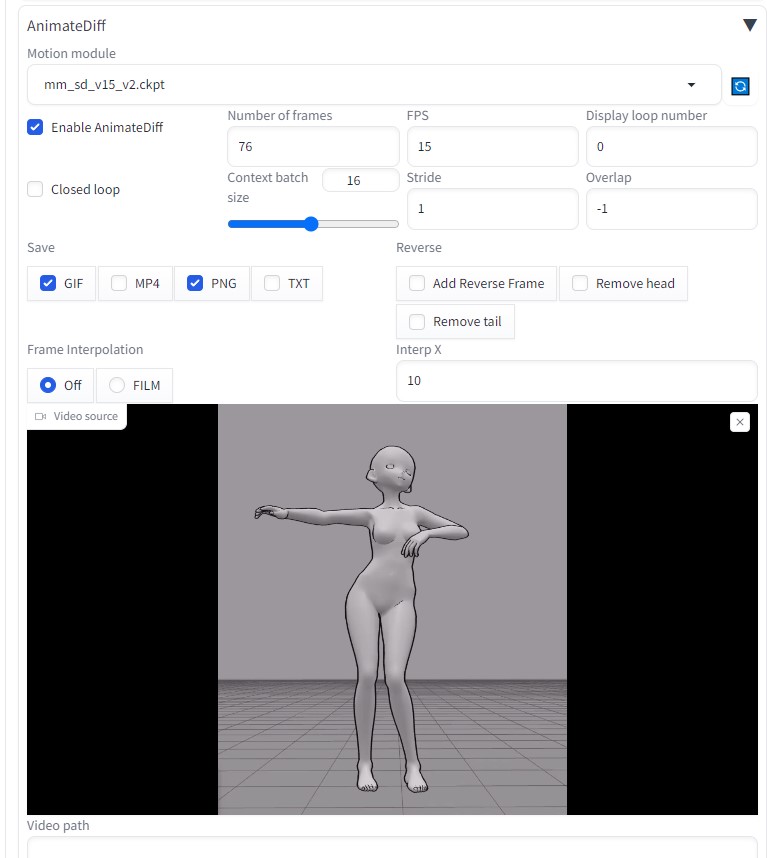
ControlNetにて、「OpenPose」と「IP-Adapter」を使用しました。
はじめに
現在、Stable Diffusion でSDXL画像を生成している。
しかし、簡単にSDXL画像を生成するUIが発表されていた。
今回は、SDXLを手軽に扱える「 Fooocus 」を考察したい。
- Fooocus
参考サイト
SDXLを手軽に扱える「Fooocus」のインストール方法・使い方まとめ!簡単操作でハイクオリティな画像を生成しよう

Fooocusのインストールから簡単な使い方を紹介【SDXLを手軽に高速に使える!低スペックでも安心です】Stable Diffusion WebUIのインストール方法

生成AIグラビアをグラビアカメラマンが作るとどうなる?第八回:シンプルで高機能なSDXL専用インターフェースFooocusとFooocus-MREの使いかた (西川和久)

Fooocusのインストール方法
圧縮ファイルをダウンロード
Click here to download から圧縮ファイルをダウンロード
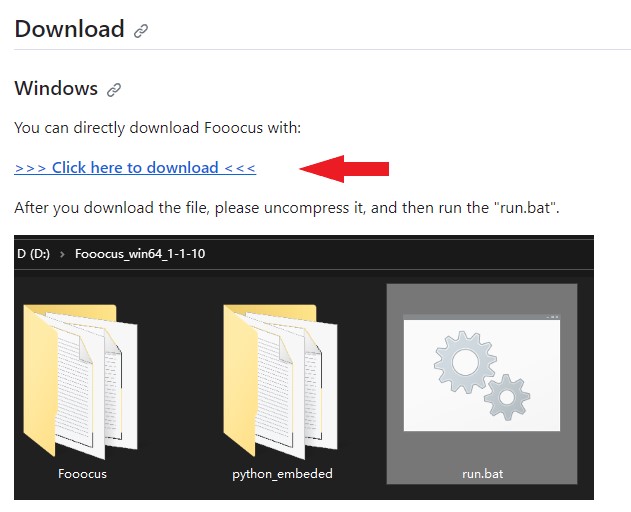
ダウンロードしたファイルを適当な場所に展開してください
※Cドライブ直下がおすすめ
2つのモデルファイルを事前にダウンロード
- sd_xl_base_1.0_0.9vae.safetensors
- sd_xl_refiner_1.0_0.9vae.safetensors


Fooocus> models> checkpoints へ配置
最後に、Fooocus> run.bat を実行
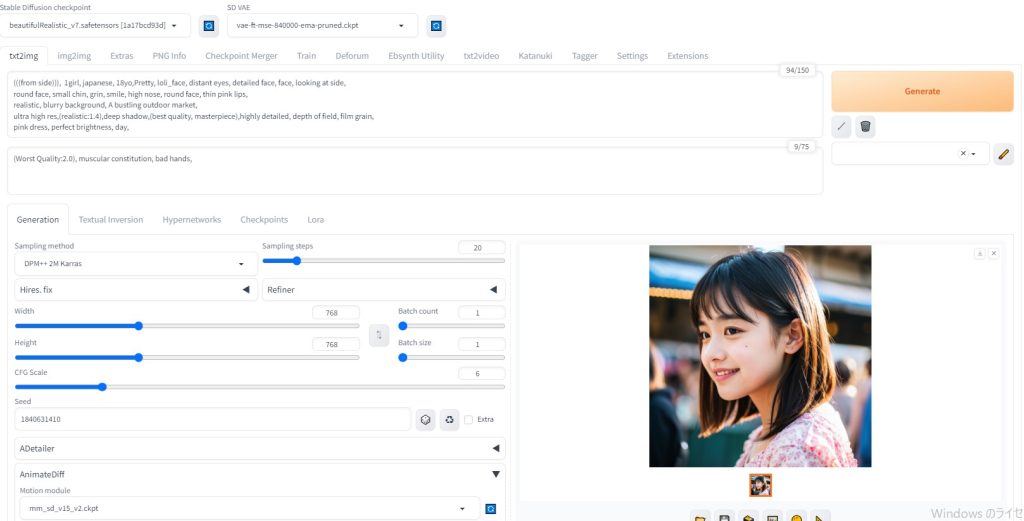
AI画像生成
人物
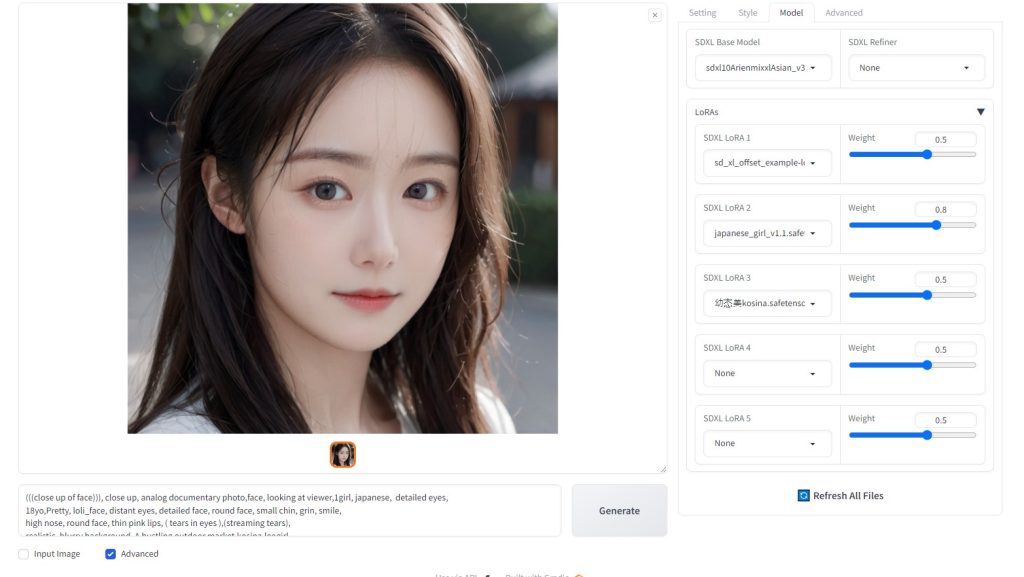
プロンプト:
(((close up of face))), close up, analog documentary photo,face, looking at viewer,1girl, japanese, detailed eyes,
18yo,Pretty, loli_face, distant eyes,
detailed face, round face, small chin, grin, smile,
high nose, round face, thin pink lips, ( tears in eyes ),(streaming tears),
realistic, blurry
background, A bustling outdoor market,kosina,leogirl,
ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of
field, film grain, crying,
(redness around the eyes), (masterpiece,best quality:1.5),jpn-girl,
Model:sdxl10ArienmixxlAsian_v30Pruned.safetensors
Lora:japanese_girl_v1.1.safetensors, 幼?美kosina.safetensors

犬
プロンプト:1dog,realistic, blurry background,ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of field, film grain,

猫
プロンプト:1cat,realistic, blurry background,ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of field, film grain,

アンドロイド
プロンプト:cyborg, realistic, blurry background,ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of field, film grain,

考察
Stable Diffusion でSDXL画像を生成していた。
しかし、Fooocusを用いることによって、SDXL画像をお手軽に生成できることが分かった。
今後、SDXLを用いて、Lora学習をしてみたい。
Fooocus(SDXL)を用いることにより、飛躍的に画像生成が綺麗になったことが理解できた。