ヘッドライン
| メイン | 簡易ヘッドライン |
簡易ヘッドライン

PC修理のわたなべ 最終更新日 2025-4-6 9:20:54
パソコン修理・パソコン販売・ホームページ制作など、パソコンのことなら、なんでもおまかせ!【茨城県坂東市・常総市・守谷市】
現在データベースには 488 件のデータが登録されています。
dtab d-01k タブレット バッテリー交換 (2023-11-21 15:55:55)
はじめにdtab d-01k タブレットのバッテリー交換を依頼された  バッテリー交換新しいバッテリーの用意
画面を外す ピックやマイナスドライバなどで、少しずつ?がしていく。 両面テープで密着しているため、ドライヤーなどで温めながら、ゆっくりと剥がしていった。 モニターの分離
バッテリーケーブルを外す   モニターケーブルを外す

 バッテリーを外す
 両面テープにて強力に付着しています。 はじめは、ゆっくりと着実に剥がしていく。 ある程度剥がせて来たら、指で剥がせるようになった。  バッテリー交換終了新しいバッテリーに交換し、ケーブルを付け直した。 
|
AnimateDiff AI動画 (yayoiMix使用) (2023-10-31 15:36:05)
はじめにyayoiMixの生成画像を試してみると、日本人の人物を綺麗に表現できた。 今回は、yayoiMixにて、sd-webui-AnimateDiff AI動画にチャレンジしてみました。
 → CIVIT AI (yayoi_Mix) ?から、ダウンロード可能 AnimateDiff (txt2img)設定内容※今回は、かわいらしい小さい女の子を表現できたらと思います モデル:yayoiMix プロンプト:
※AnimateDiffでは、呪文の単語数が少ないほうが、動きのある動画を表現できるように感じます。 大きさ:600×800 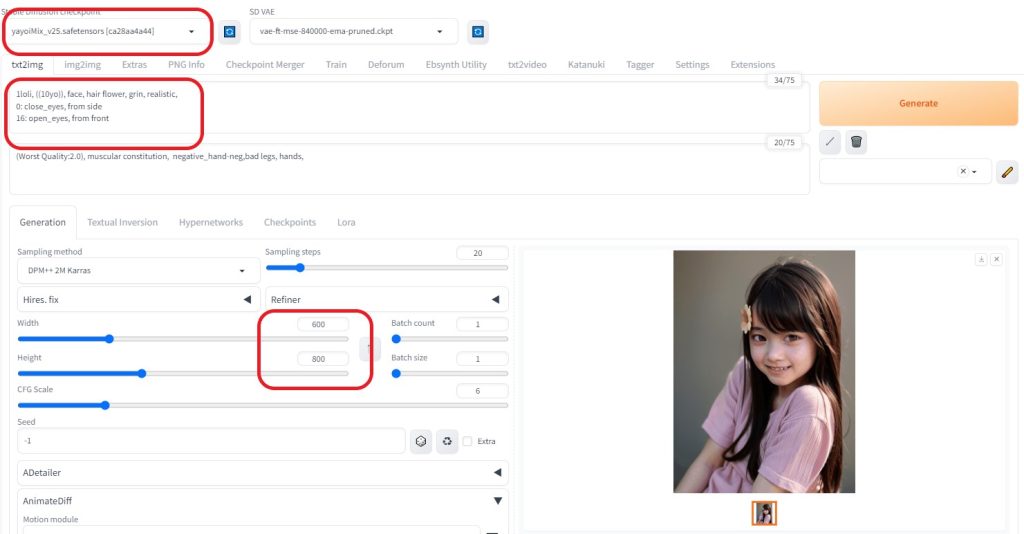
 生成された32枚の画像
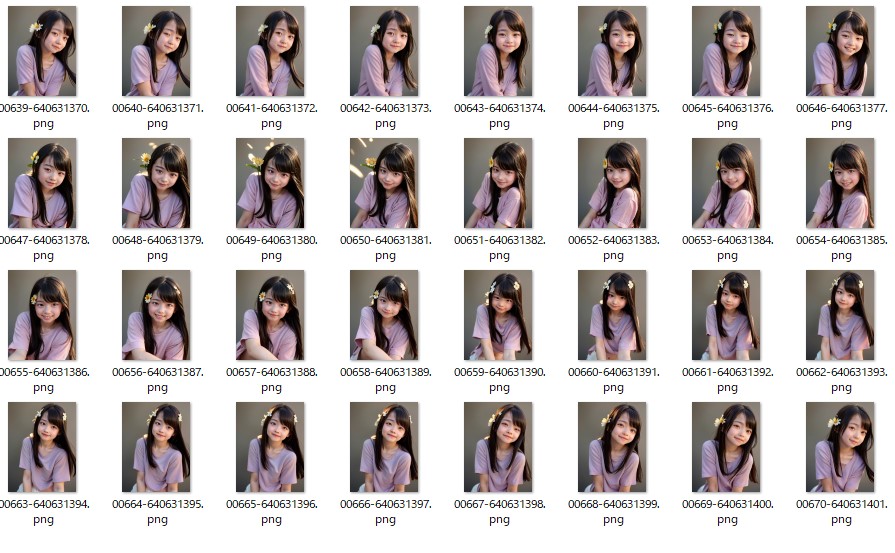
各画像をより綺麗に(img2img)img2imgを利用し、生成された画像をより綺麗にしてみる。
「test_input」フォルダに先ほど生成した32枚の画像をコピーする 「 Batch 」タブを選択し、以下のような設定にした。
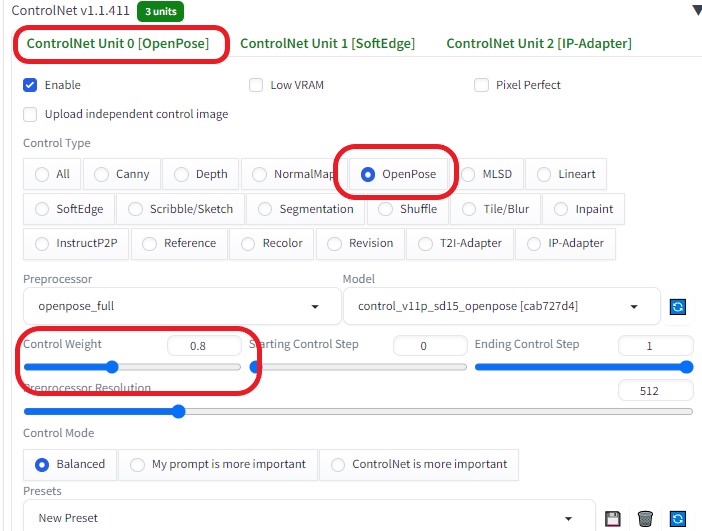
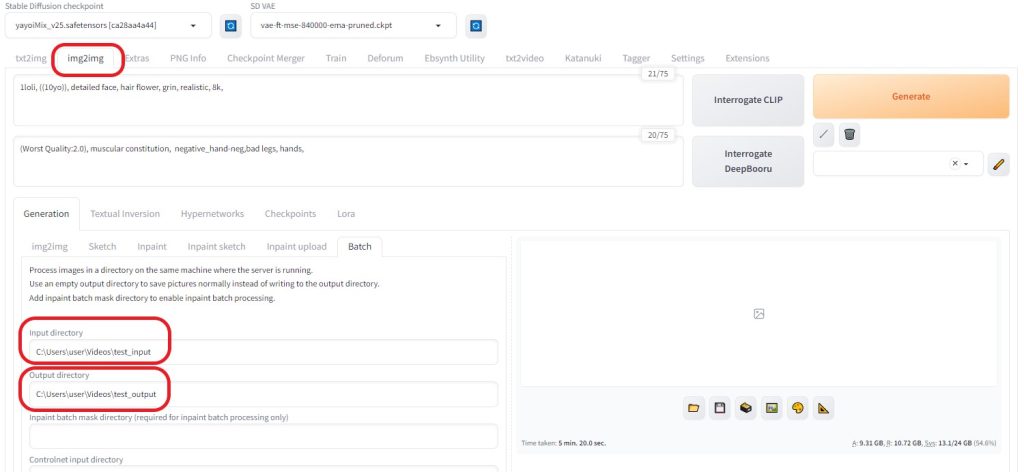 Resize to※画像の大きさを作成した画像の大きさに合わせる(600×800) 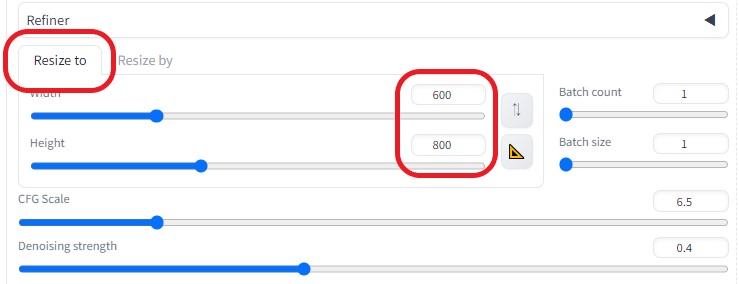 Resize by※大きさを1.25倍に拡大(750×1000) 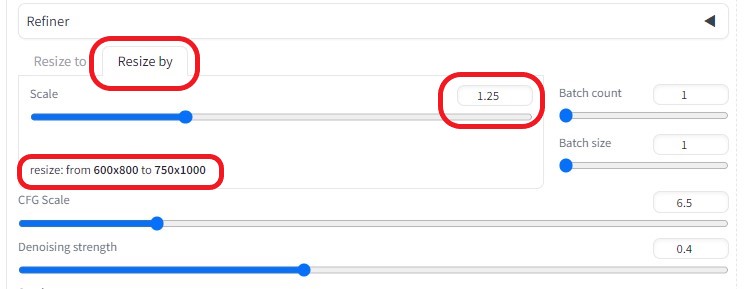 ControlNetを以下のように設定し、各画像の相関性を合わせるようにした
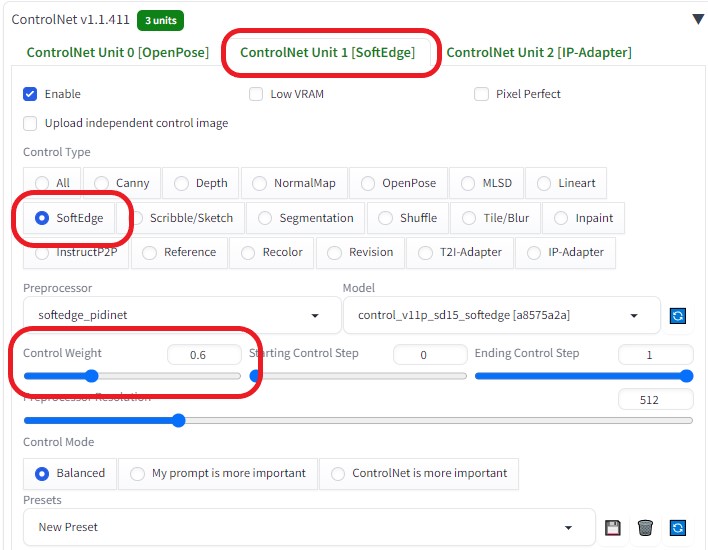
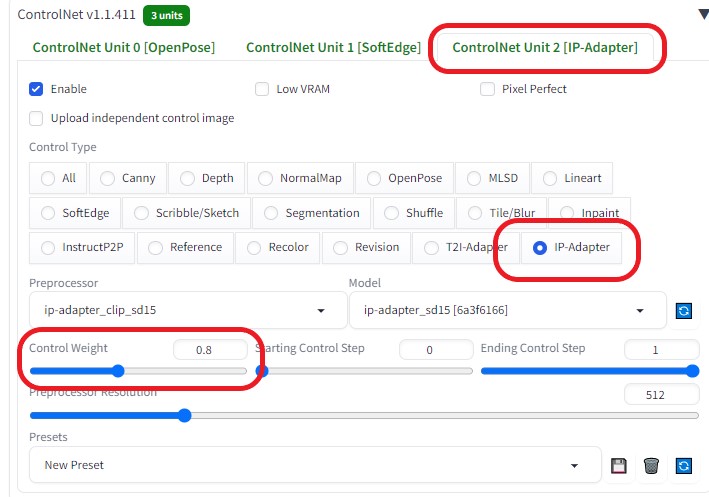 生成すると「test_output」フォルダに32枚の画像が生成される
動画生成(FILM使用)生成した「test_output」フォルダの32枚の画像を FILMで綺麗な動画に変換 しました。 FILMの詳細は、以下をご確認ください。
動画の再生速度を変更(ffmpeg使用)
※今回は、生成した動画(input.mp4)を12倍速に変更(cmd使用)
編集動画(BGM付き)【 VideoProc Vlogger 編集画面】 
考察いろいろなモデルが登場してきました。 日本人モデルも以前に比べると多様な人物を表現できるようになりました。 くわえて、思い通りの動きができるようになれば、短編ムービーも可能になっていけると思います。 以前と比べると、LoRAを使用しなくても、かわいらしい女の子を表現できたのも画期的に感じます。 |


Frame Interpolation for Large Motion【FILM】 (2023-10-21 17:52:21)
 ポッドキャスト :
video/mp4
ポッドキャスト :
video/mp4
はじめにAnimateDiffにある FILM の項目に興味をもった。 ※FILM(Frame Interpolation for Large Motion) 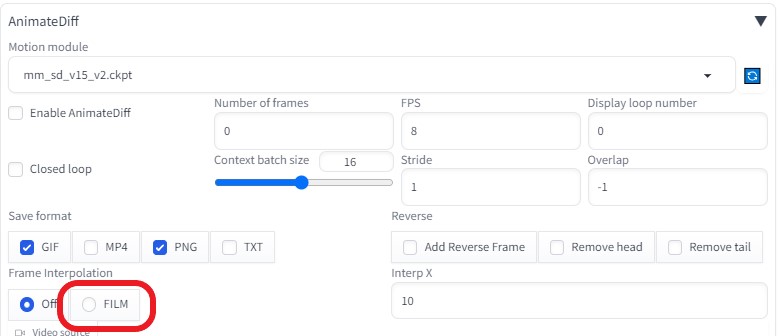 2枚の画像を入力するだけで、その間の動きを補間して、動かすという技術だそうです。 参考サイト画像をぬるぬる動かすFrame Interpolation for Large Motion【FILM】  画像をぬるぬる動かすFrame Interpolation for Large Motion【FILM】
ディープラーニングの使いどころはたくさんあると思います。今までいろいろなモデルをいじってきた私が考える、ディープラーニングの使い方の真骨頂は「補間」です。今回、試してみるのは"THE補間"ともいえる技術のFrame
In farml1.com
FILMインストールWindows インストール手順 
https://github.com/google-research/frame-interpolation/blob/main/WINDOWS_INSTALLATION.md github.com github GitHub - google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 2022.
FILM: Frame Interpolation for Large Motion, In ECCV 2022. - GitHub -
google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 20... github.com
Anaconda
frame-interpolation> に「 pretrained_models 」フォルダを作成し、以下のデータをインストールする  pretrained_models - Google ドライブ drive.google.com
FILM実行中間フレーム補間
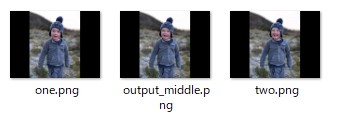 多数のフレーム間補間AI画像を生成 同様な画像を少しずつ変化を加えて5枚生成し、4枚を逆順に加える。 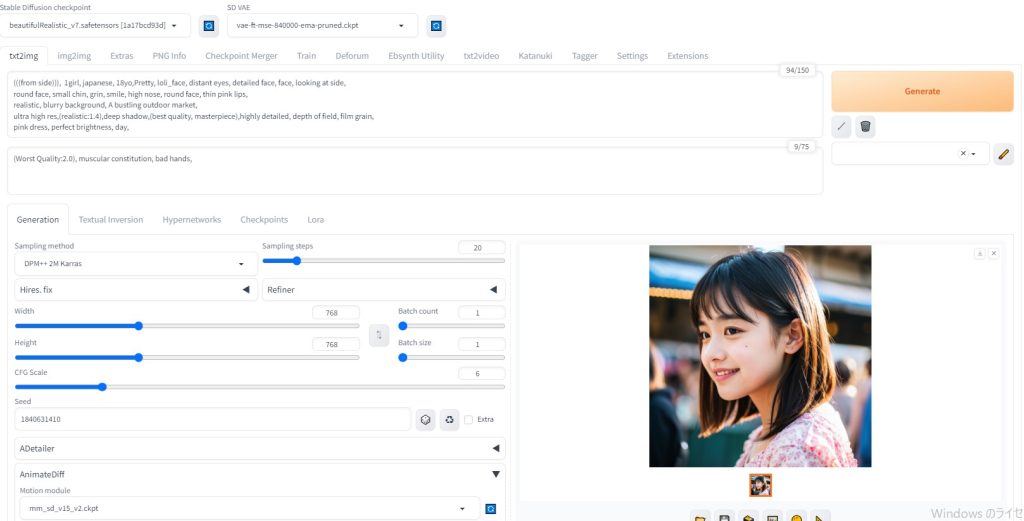 画像01.png?09.pngを「 photos 」フォルダ以下に配置
 完成動画
|
AnimateDiff AI動画 (最新BRA V7使用) (2023-10-21 0:31:38)
ポッドキャスト :
video/mp4
はじめに最新のBRAV7がリリースされました。 最新BRAV7にて、sd-webui-AnimateDiff AI動画にチャレンジしてみました。
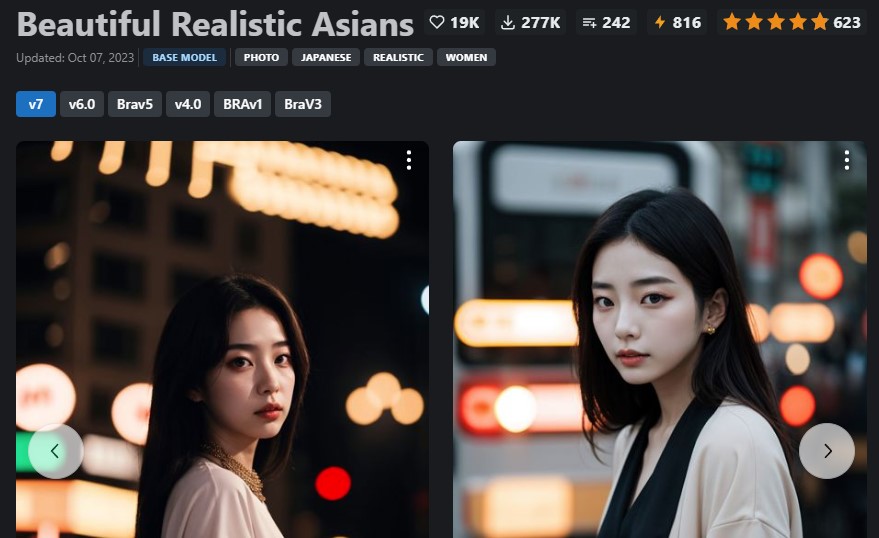 → CIVIT AI (BRAV7) から、ダウンロード可能 BRAV7Beautiful Realistic Asiansの新モデルは、以下のサイトを参考にしました。 待望のBRAV7がリリース!Beautiful Realistic Asiansの新モデル・プロンプトなど 
待望のBRAV7がリリース!Beautiful Realistic Asiansの新モデル・プロンプトなど Stable Diffusion等の画像生成AIで大人気のモデルBeautiful Realistic
Asians(BRA)から、新モデルV7がリリースされました。V5、V6との比較や、おすすめのプロンプトなどをご紹介。 ai-freak.com roop用顔画像 (BRAV7使用)Beautiful Realistic Asians( BRA )から、待望の新モデル V7 がリリースされました。 早速、生成してみました。 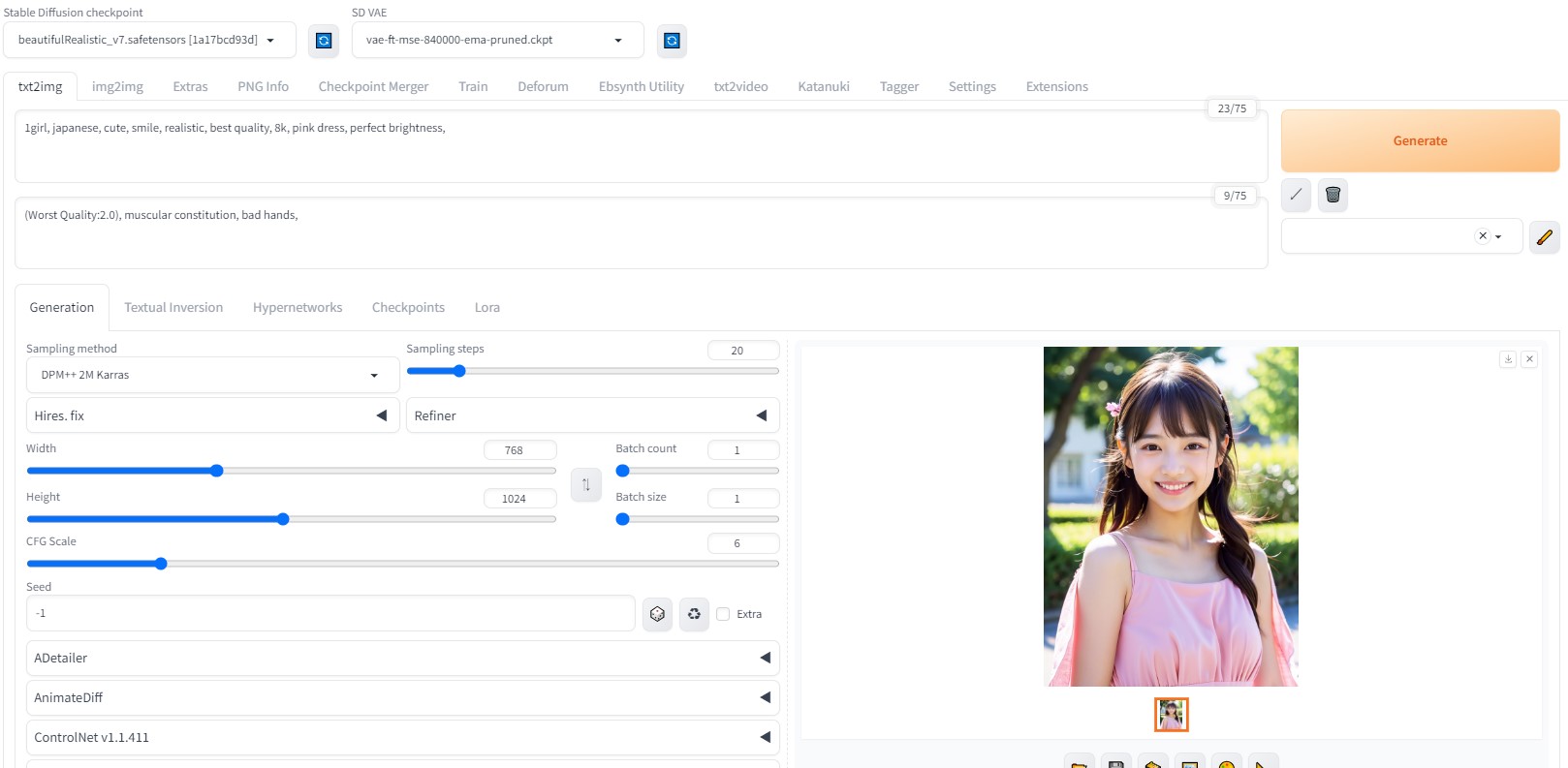 生成画像  画質も一段と綺麗になりました。 参考サイト(AnimateDiff)AIでアニメーション制作!AnimateDiffの基本的な使い方【Automatic1111】  AIでアニメーション制作!AnimateDiffの基本的な使い方【Automatic1111】 | SoreNuts Stable Diffusion Web
UI(Automatic1111)の拡張機能「AnimateDiff」の使い方です。MotionLoRAの併用方法、MP4の書き出しエラーの対処法などを掲載しています。一貫性のある短いアニメーションならこの拡張機能がおすすめです。
sorenuts.jp AnimateDiff (txt2img)設定方法などは、以下をご覧ください。
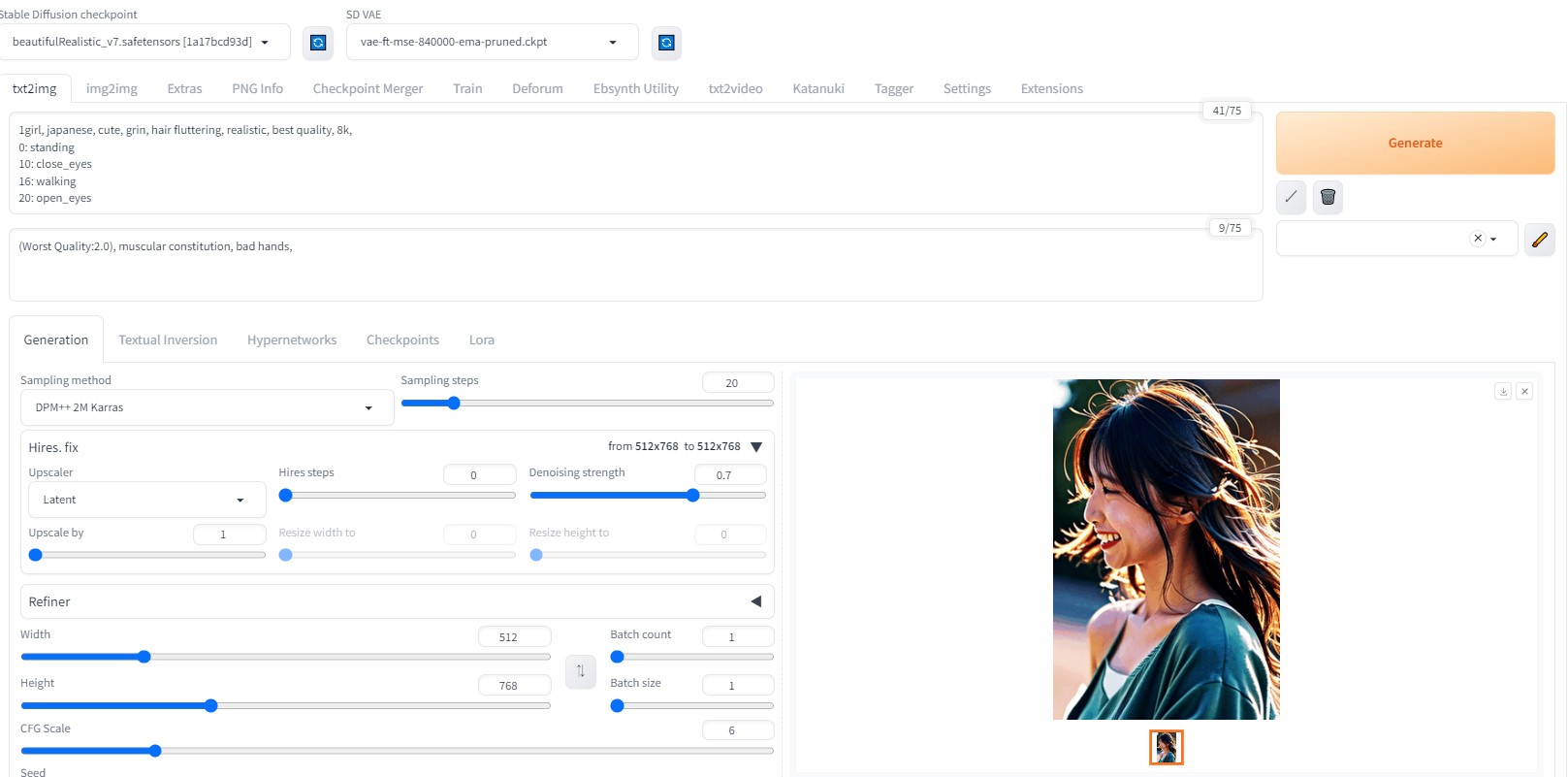
モデル:beautifulRealistic_v7 プロンプト:
設定内容
 FPS8フレーム、総数32フレーム(4秒) 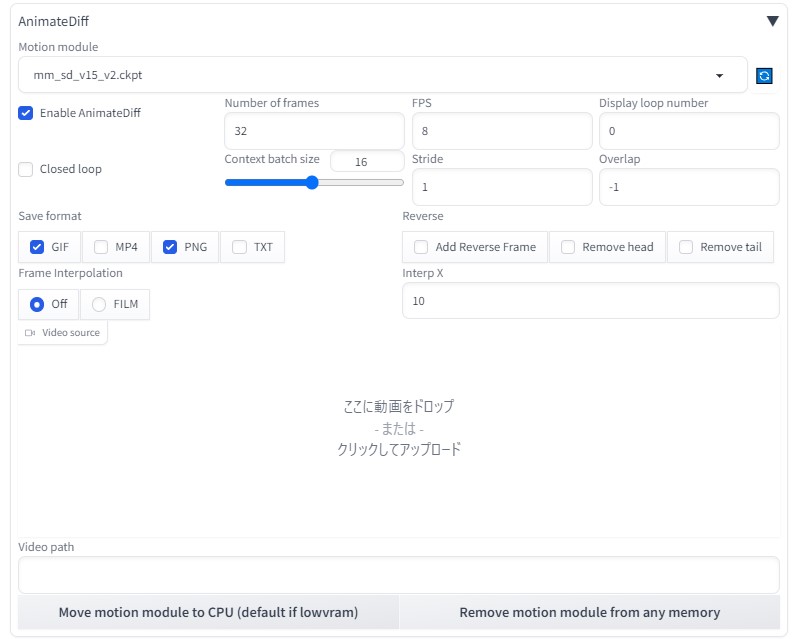 生成された32枚の画像 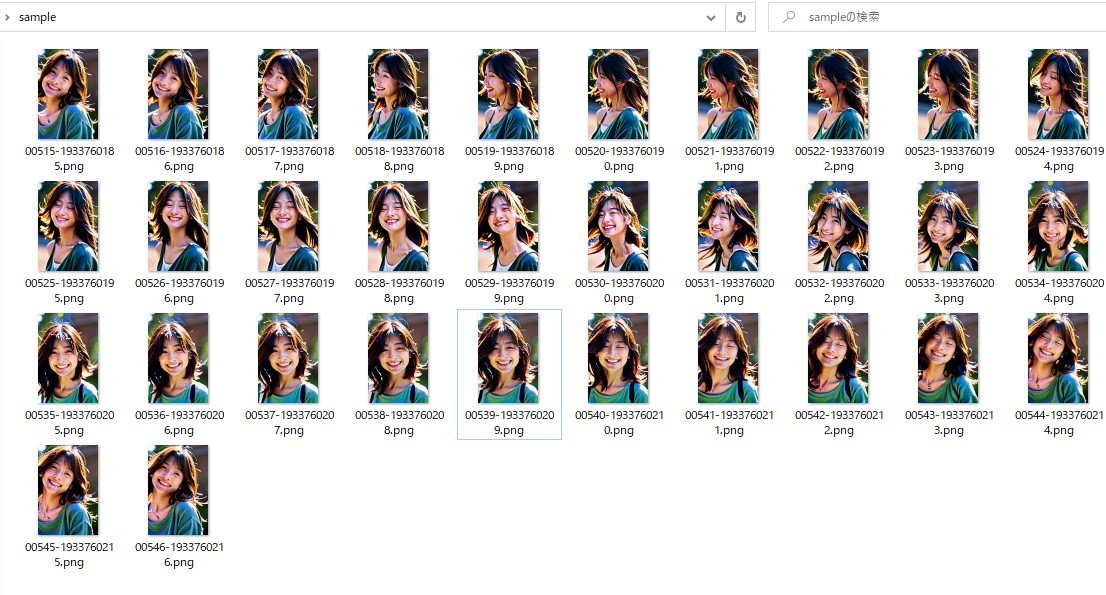 各画像をより綺麗に(img2img)img2imgを利用し、生成された画像をより綺麗にしてみる。
「 sample 」フォルダに先ほど生成した 32枚の画像をコピー する 「Batch」タブを選択し、以下のような設定にした。 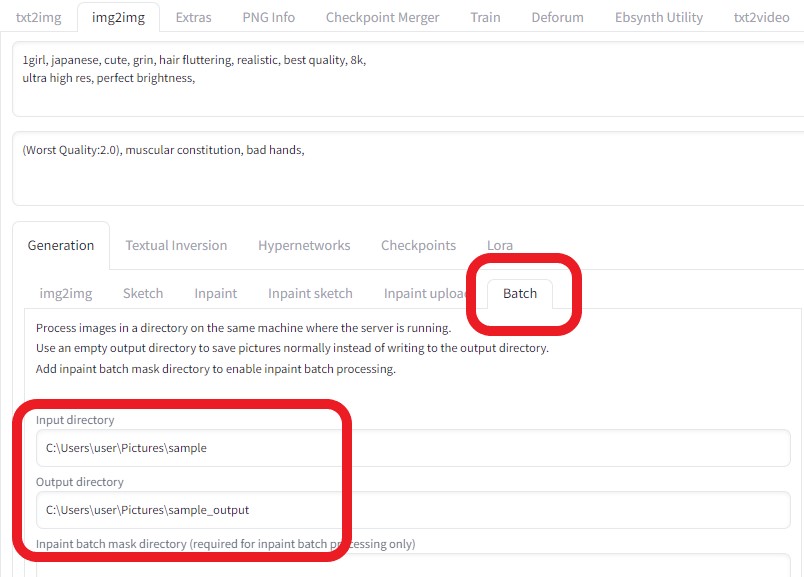
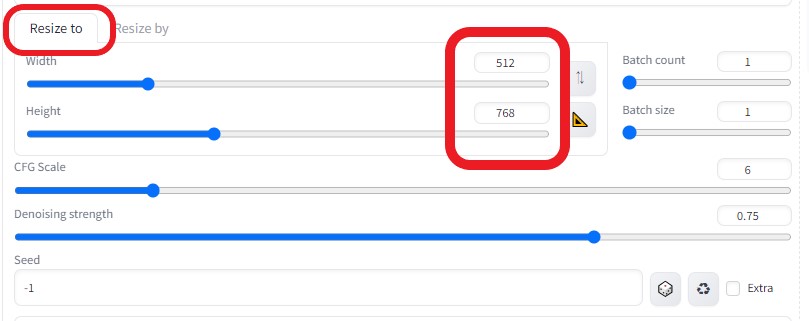 より綺麗な画像に変換したいので、画像サイズを1.5倍に上げた 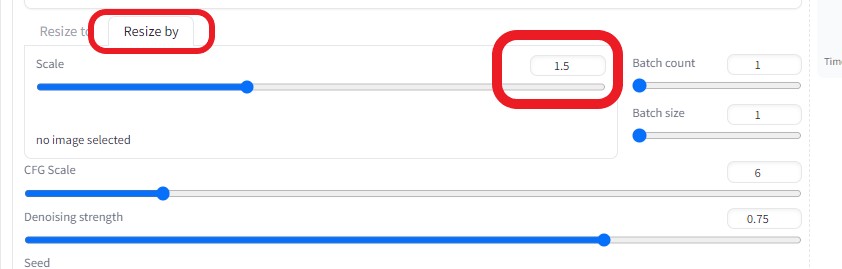 ControlNetを以下のように設定し、各画像の相関性を合わせるようにした 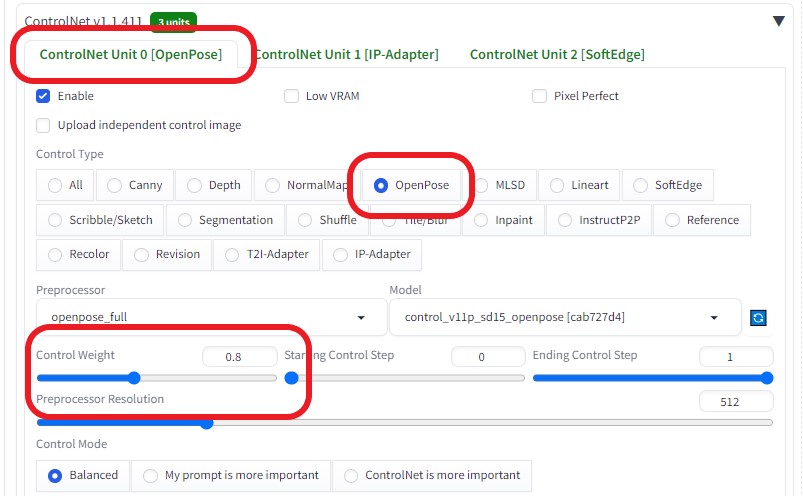
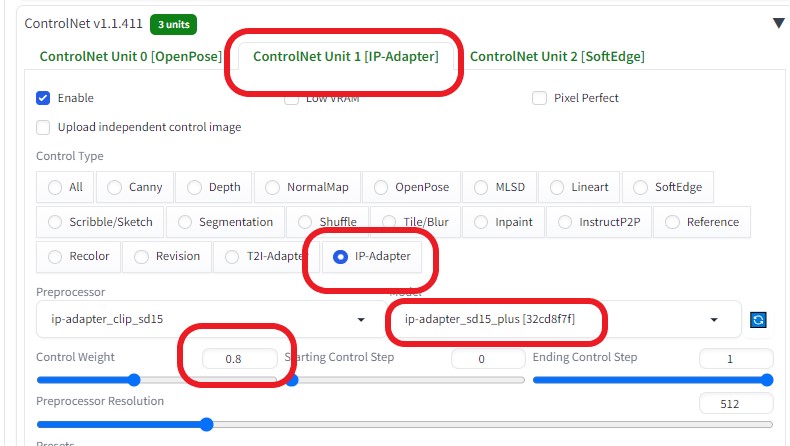
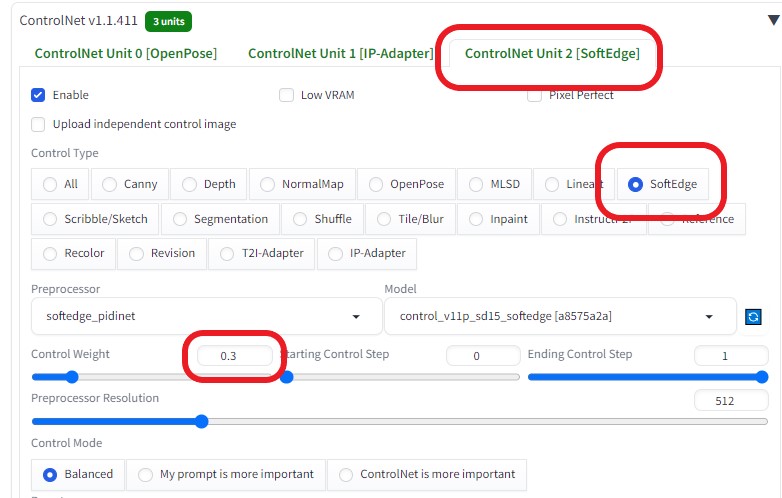 BRAV7で生成したAI画像をroop に 用いた 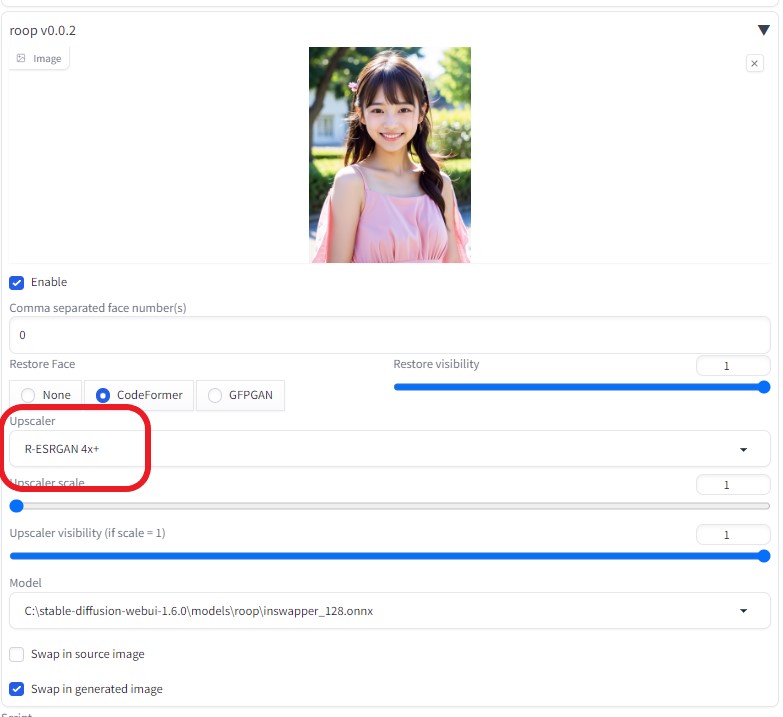 連続画像を動画に変換連続画像を動画に変換する
詳細は、以下を参考にしてください
編集などの設定は、以下の通りです。 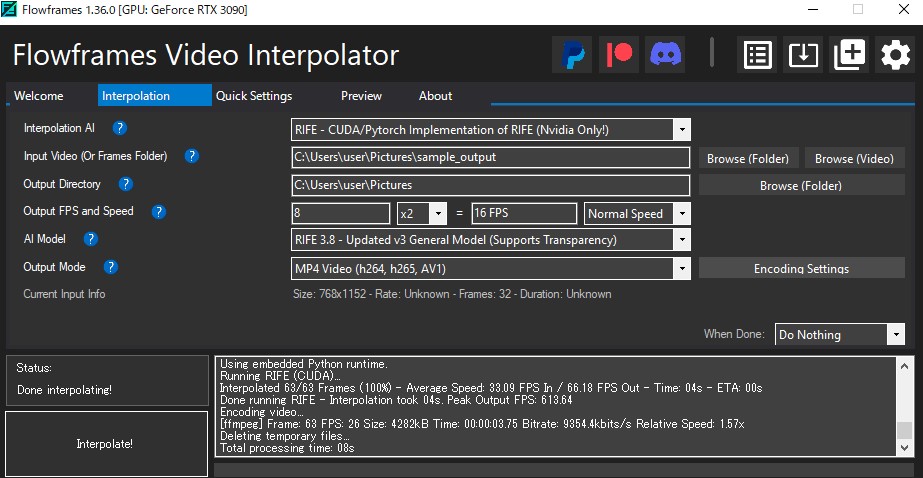 完成動画sample_output-2x-RIFE-RIFE3.8-16fps.mp4
YouTube用 編集動画YouTube用に編集した。 VideoProc Vlogger を使用し、BGMやモーション設定などを追加した。 音源 フリーBGM「センチメンタル・リバー (instrumen…」  フリーBGM素材『センチメンタル・リバー (instrumental)』試聴ページ|フリーBGM
DOVA-SYNDROME 無料・著作権フリーのBGM素材「センチメンタル・リバー
(instrumental)(作:ioni)」の試聴ページです。 dova-s.jp 【 VideoProc Vlogger 編集画面】 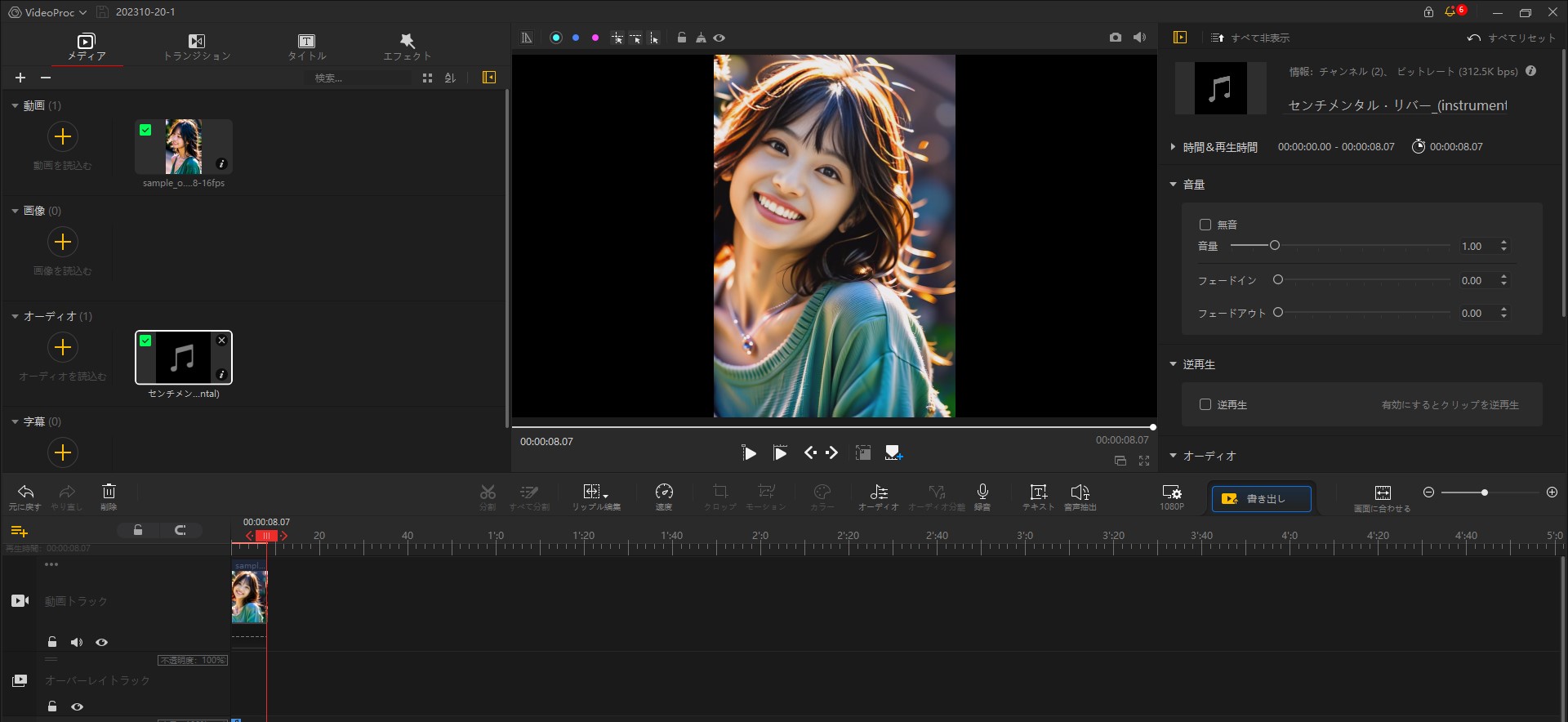
完成動画(YouTube用)※高画質に変更してから 、 ご確認ください
↓(高画質) 1080p60HD で確認するとより綺麗な動画になります↓
|

AnimateDiff+OpenPose AI動画 (txt2img) (2023-10-14 19:41:00)
ポッドキャスト :
video/mp4
はじめに前回、sd-webui-AnimateDiff AI動画 (img2img)で動画を生成した。 しかし、AnimateDiffのみを使用した際の滑らかな(ヌルヌルした)動画を作成することができなかった。 そこで、animatediff+openposeで何かできないかと検索していたところ、以下のようなサイトを見つけた  【AIアニメ】ComfyUIとControlNetでAnimateDiffを楽しむ|Baku
「AnimateDiff」では簡単にショートアニメをつくれますが、プロンプトだけで思い通りの構図を再現するのはやはり難しいです。
そこで、画像生成でおなじみの「ControlNet」を併用することで、意図したアニメーションを再現しやすくなります。
必要な準備 ComfyUIでAnimateDiffとCo... note.com ComfyUIにて作成していたため、sd-webuiで生成できるように考案した。 準備 Openpose画像(openpose_samples.zip)を以下のサイトから、ダウンロードする 【AIアニメ】ComfyUIとControlNetでAnimateDiffを楽しむ 【AIアニメ】ComfyUIとControlNetでAnimateDiffを楽しむ|Baku
「AnimateDiff」では簡単にショートアニメをつくれますが、プロンプトだけで思い通りの構図を再現するのはやはり難しいです。
そこで、画像生成でおなじみの「ControlNet」を併用することで、意図したアニメーションを再現しやすくなります。
必要な準備 ComfyUIでAnimateDiffとCo... note.com 
【こちらからもダウンロード可能( openpose_samples.zip )】 連続画像を動画に変換する Openpose画像を動画にするため、Flowframesを使用した  Flowframes - Fast Video Interpolation for any GPU by N00MKRAD Video
interpolation for everyone. Up to 100x faster than DAIN, compatible with all recent AMD/Nvidia/Intel GPUs. nmkd.itch.io 編集などの設定は、以下の通りです。 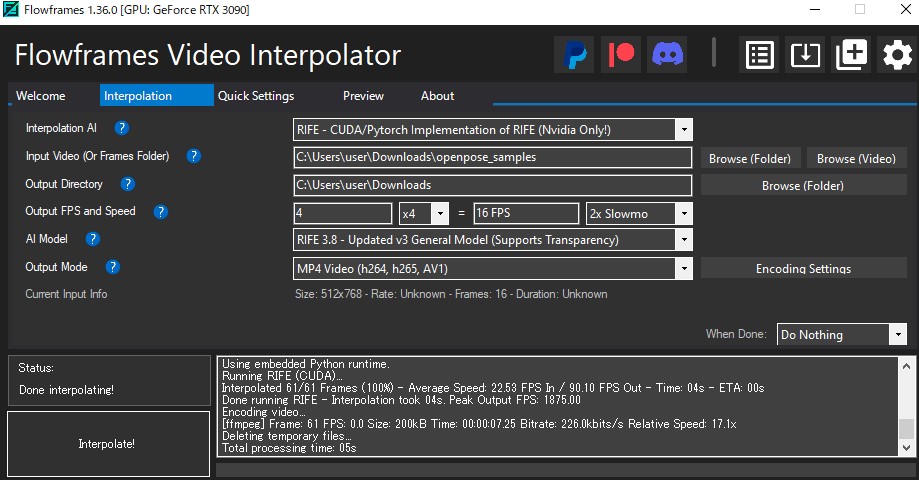 Openpose画像を動画にした openpose_samples-4x-RIFE-RIFE3.8-16fps.mp4
動画生成画像準備 モデル: BracingEvoMix_v1.safetensors プロンプト:
Sampling method: DPM++ 2M Karras Hires. fix:1.2 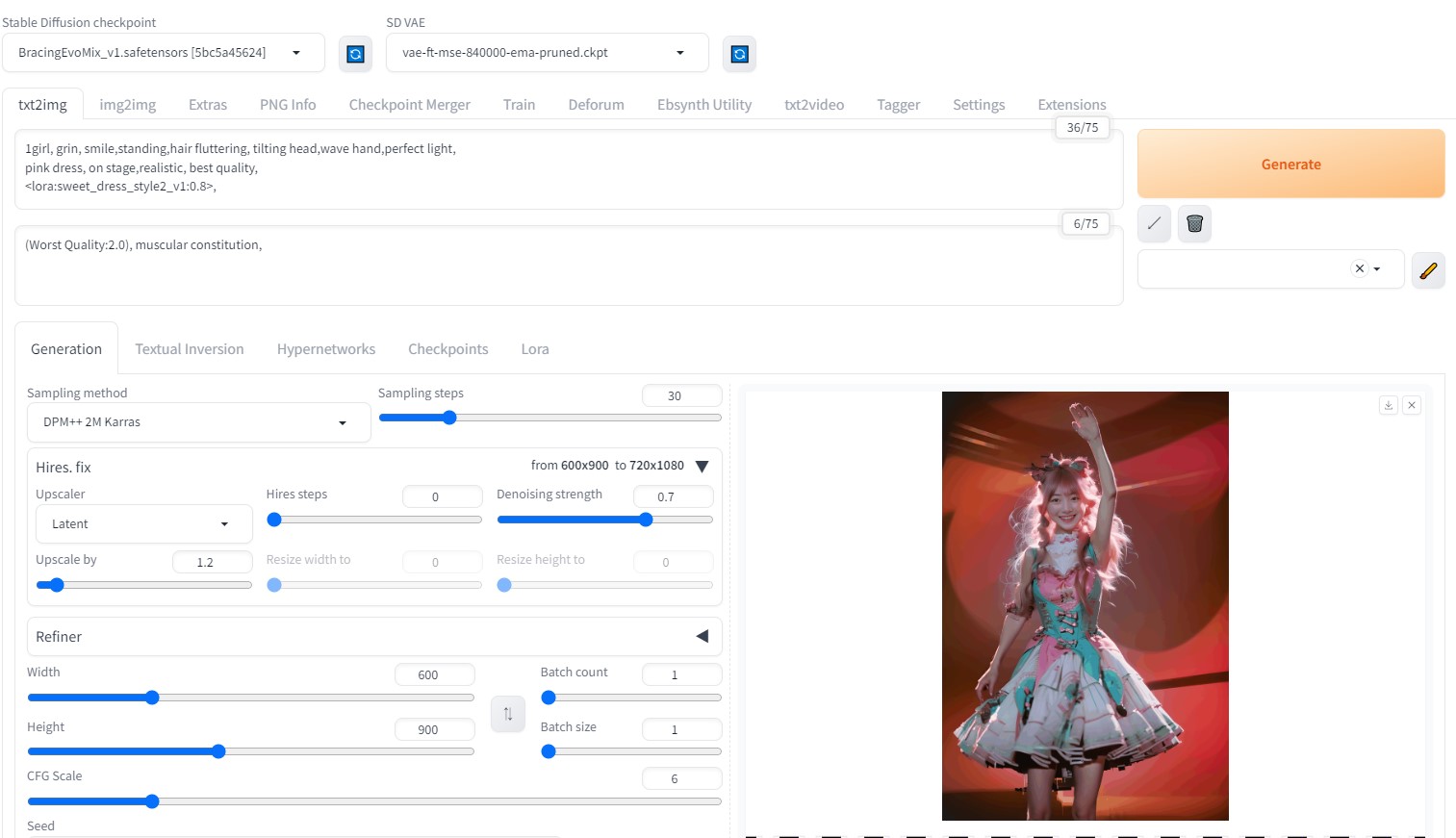 Number of frames:48 (6秒) 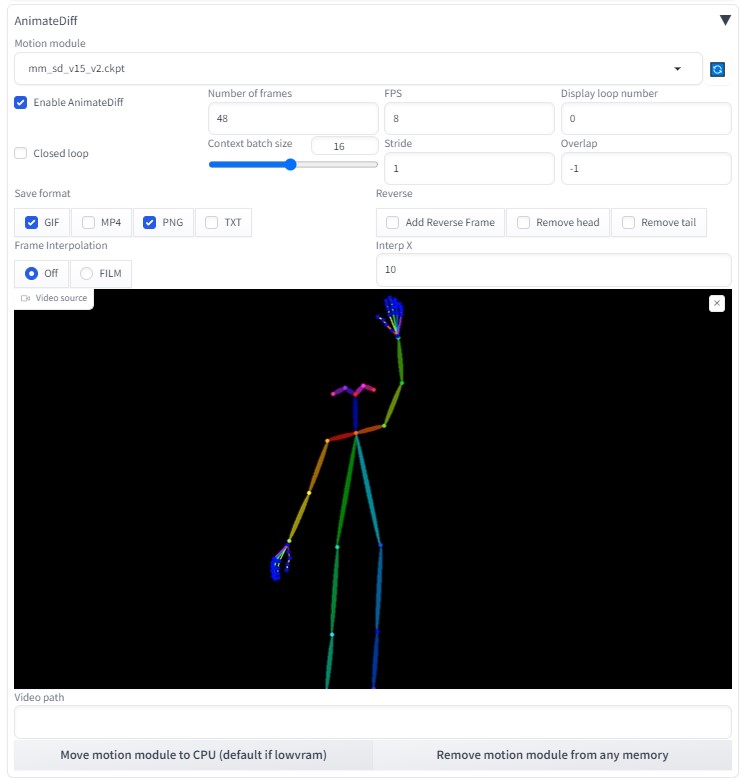 ControlNetにて、「OpenPose」を使用 動画元が、 OpenPose 動画のため、Preprocessorを 「 none」 に変更 (←※重要) 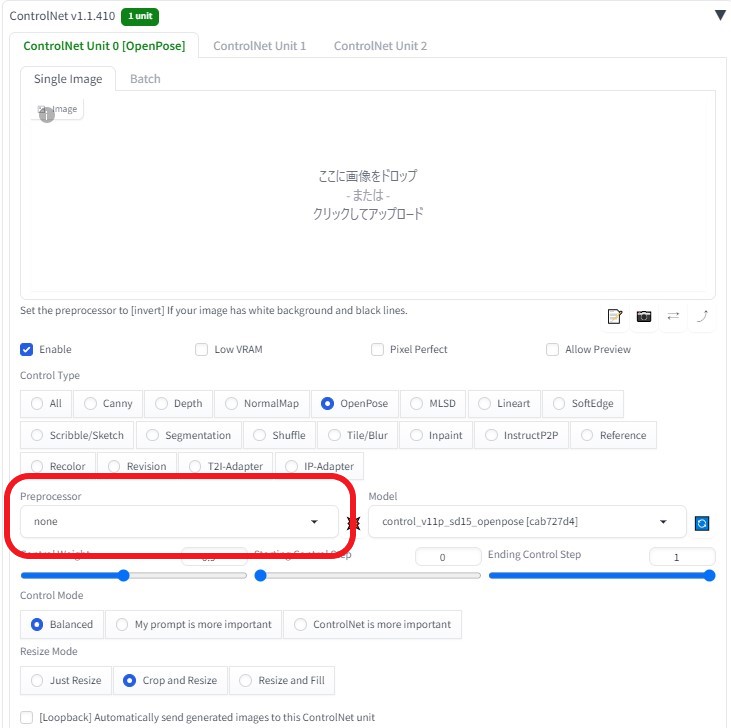 roopで顔を固定する (Upscaler scale は R-ESRGAN 4x+ 選択) 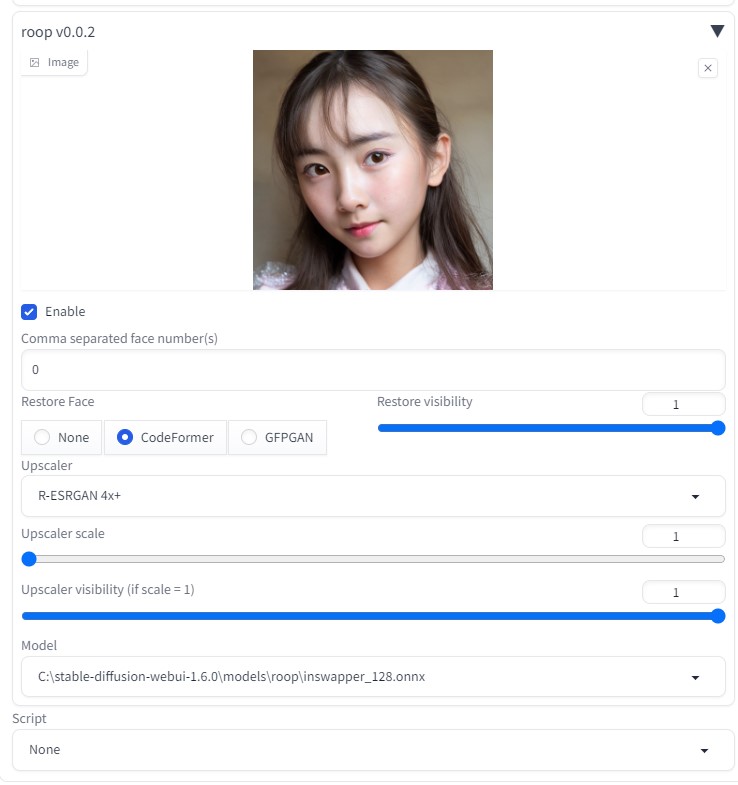 完成動画VideoProc Vlogger使用(BGM追加など)
考察動画今回作成したAI動画と元のOpenPose動画の比較 考察連番画像を動画に変更することにより、動作をある程度固定した状態で、綺麗な動画(ヌルヌルした動画)を生成することができた。 なおかつ、Flowframesソフトを活用することにより、OpenPoseを動画にすることも簡単に作成できた。
|
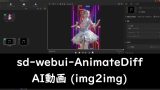
sd-webui-AnimateDiff AI動画 (img2img) (2023-10-13 2:09:03)
はじめに前回、sd-webui-AnimateDiff AI動画を生成できた。 img2imgを用いても生成できることが分かった。 画像を2枚用意することによって、最初と最後のポーズを決められる。 これにより、連番のような画像を用意することにより、継続する動画を作成することができるようになると思われる。 参考サイトsd-webui-AnimateDiffをイメージtoイメージで使う方法【AIアニメーション】 txt2img連番画像の準備連番画像生成(6枚) txt2imgにて、似たような画像(連番画像)を6枚生成 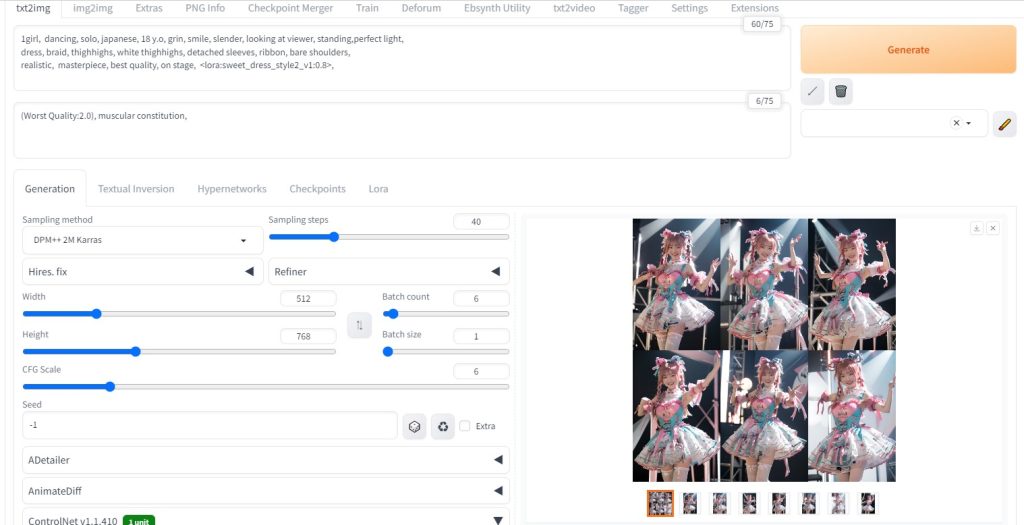 ControlNet> IP-Adapter で衣装をある程度固定する 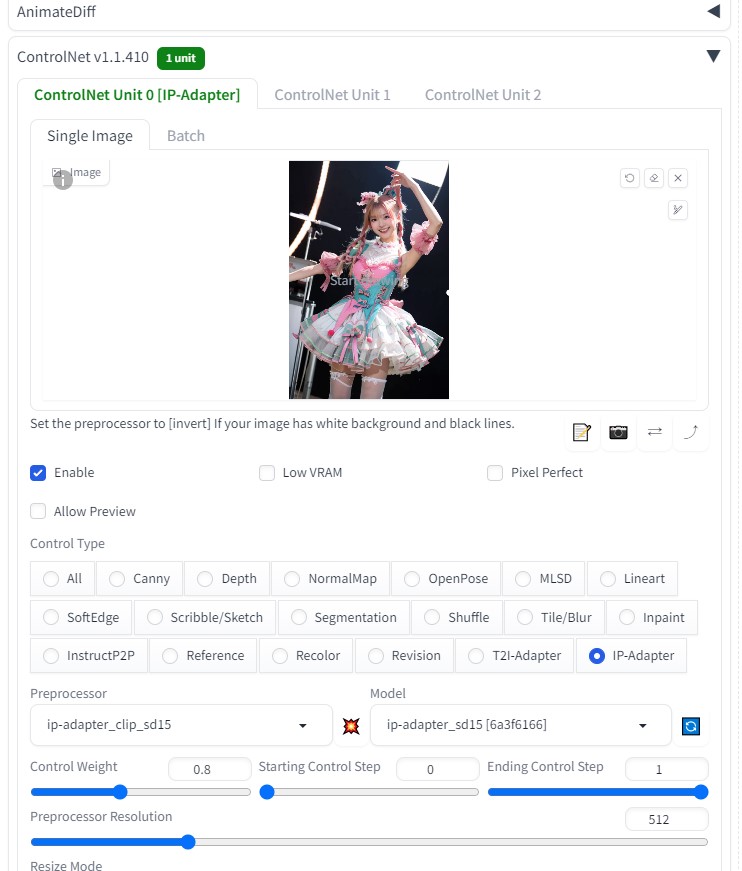 roopにて、顔画像をある程度固定する。  生成されたAI画像に連番を振る  img2img先ほど作成した、「 001.png 」をimg2imgに貼り付ける (動画 最初の画像 ) 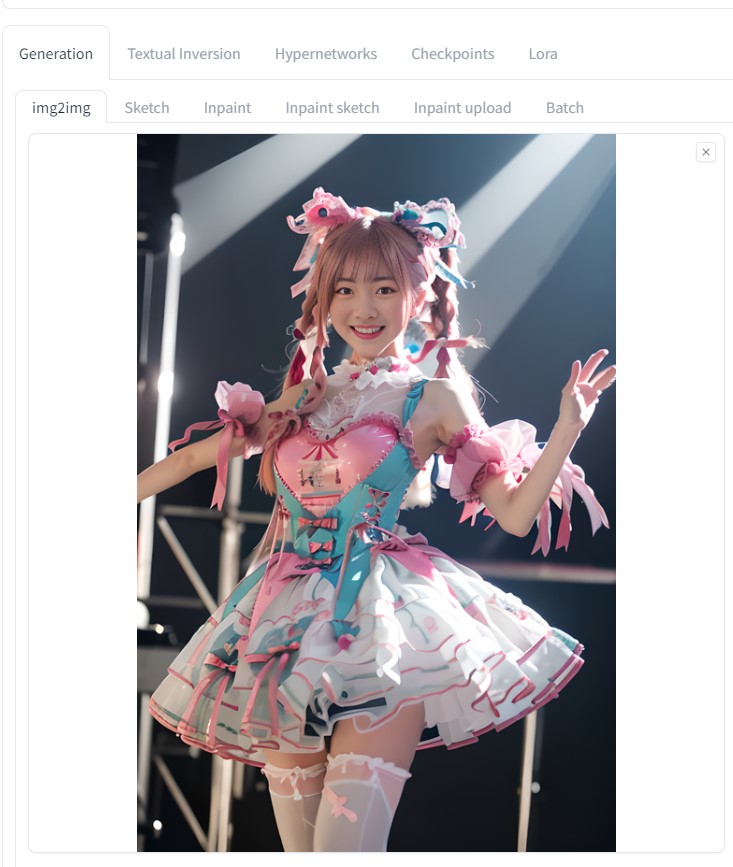 他の設定などは、以下の通りです。 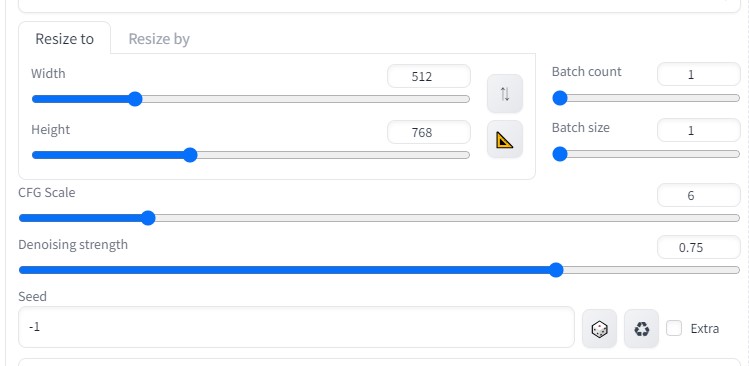
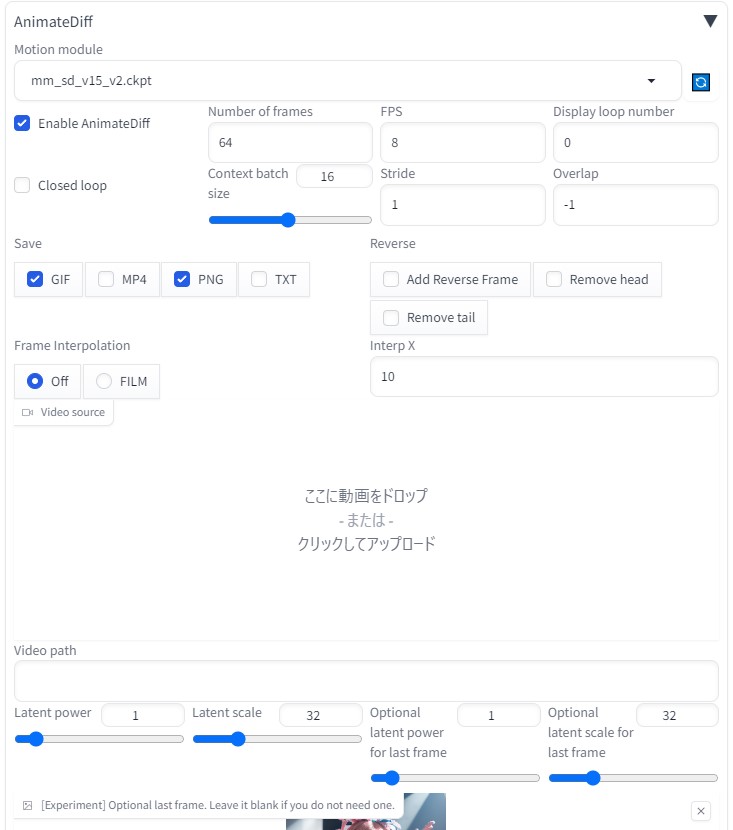 Latent power より下の場所に、「 002.png 」をimg2imgに貼り付ける(動画 最後の画像 ) 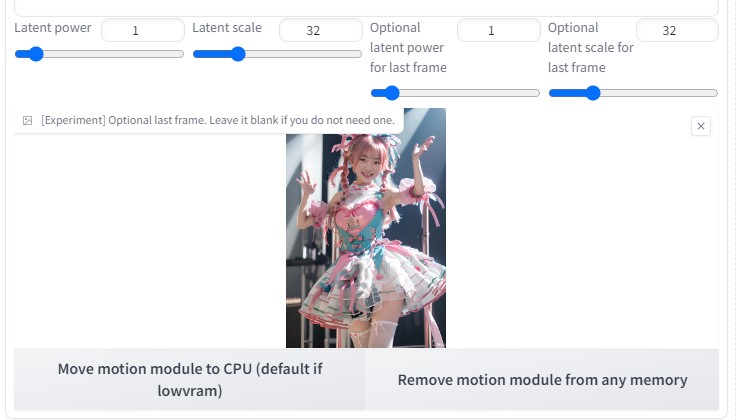 roopにて、顔画像をある程度固定する。 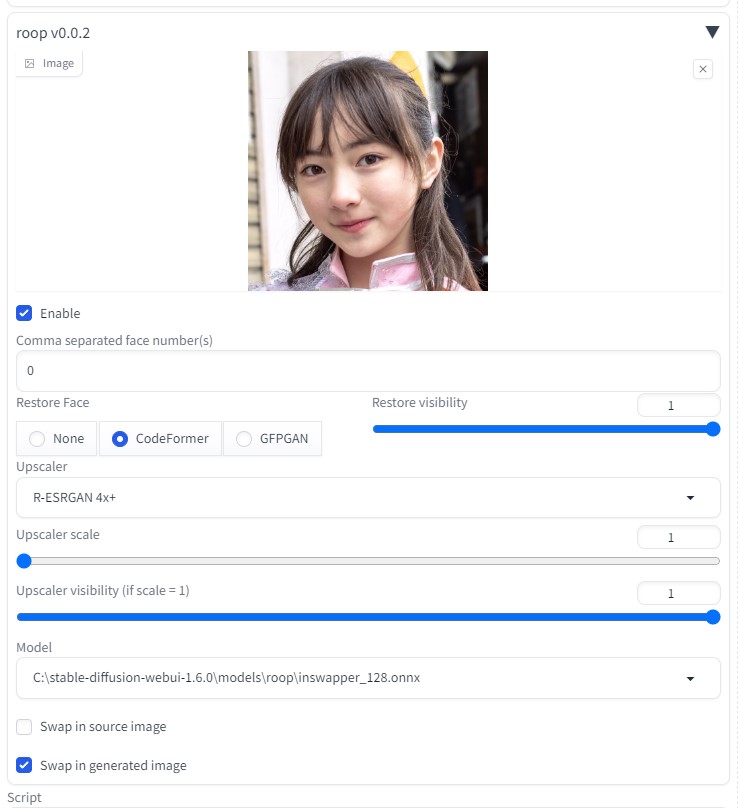 生成途中の画像は、以下のようになる。 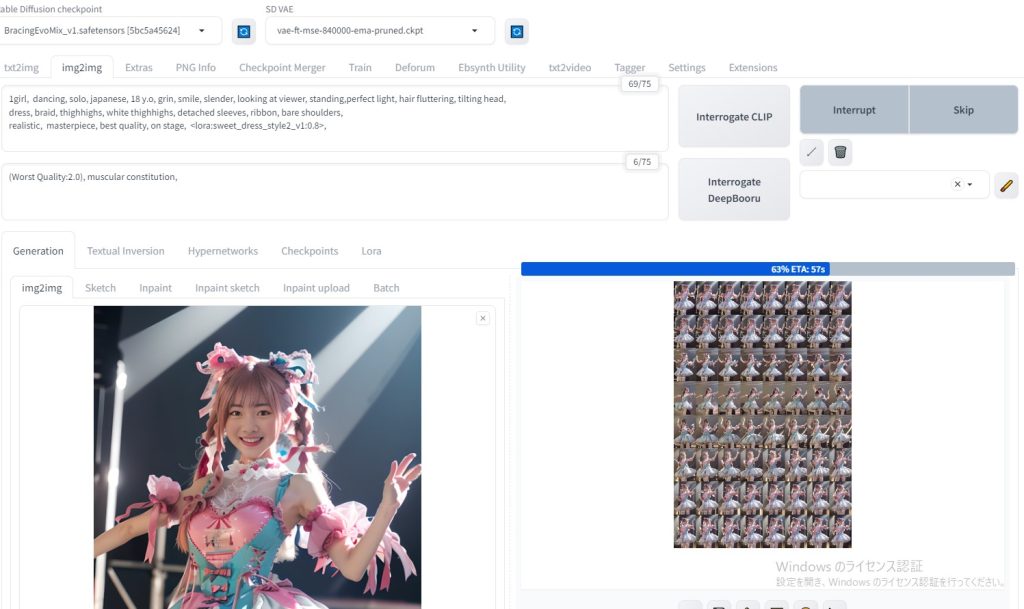 1つの動画生成を終了後、 最初の画像 と 最後の画像 を変更する
これを連番ごとに変更することにより、動画の継続性が保たれる。 作成したい動画の最後のフレームを、最初の画像に戻すとループ状に動画が動く
動画編集img2imgで生成した6つの動画を編集ソフトでまとめる 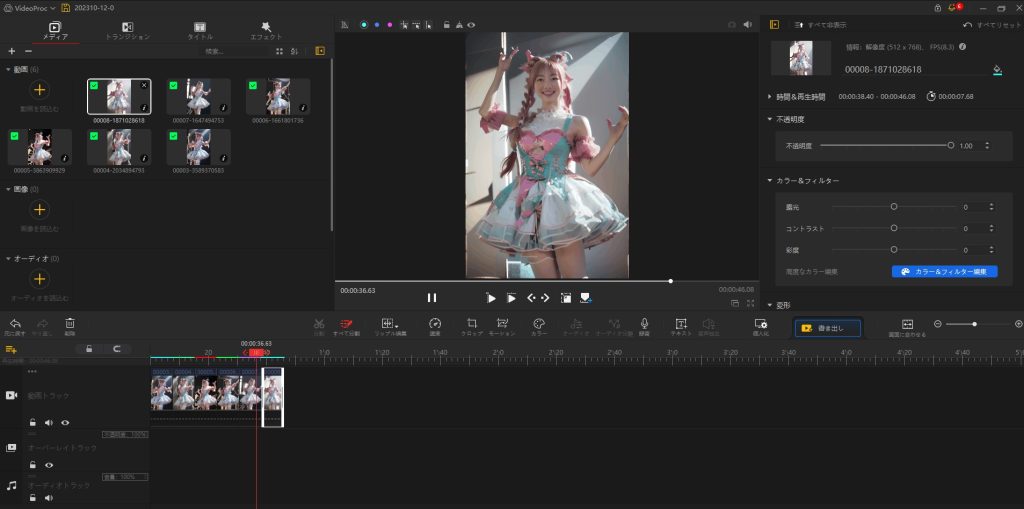 これで、1つの動画を生成できた。 EBsynth生成(背景交換)背景をEBsynthを用いて変更する 詳細は、以下をご覧ください。 動画編集 (BGM追加など)VideoProc Vlogger 使用(BGM追加、フォーカスの動き、ダンスのスピード速度の変更など) 音源(フリー素材): また明日 フリージングル素材『また明日』試聴ページ|フリーBGM DOVA-SYNDROME 無料・著作権フリーのBGM素材「また明日(作:カピバラっ子)」の試聴ページです。 dova-s.jp
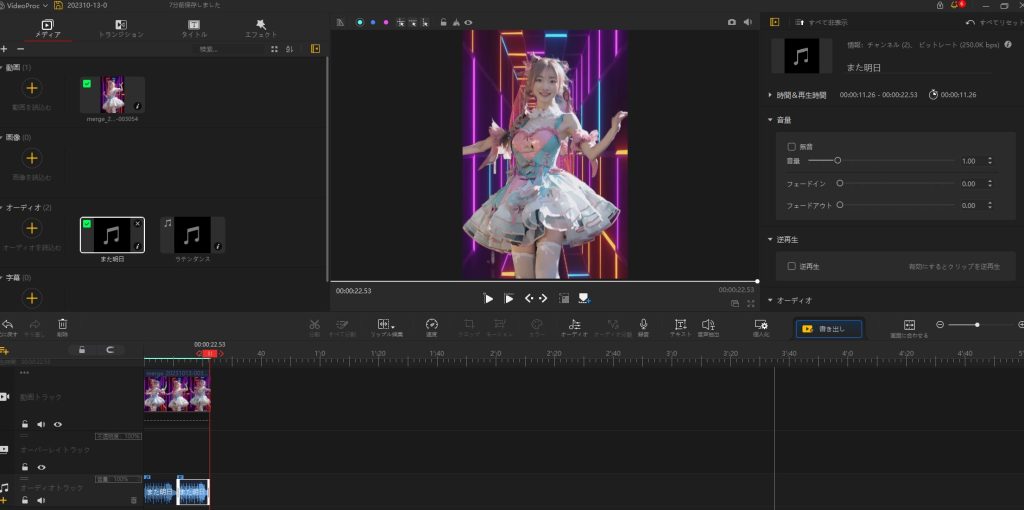 完成動画
|

sd-webui-AnimateDiff AI動画 (2023-10-10 1:28:36)
ポッドキャスト :
video/mp4
はじめにAIアニメーションがさらに向上した。
参考サイト【必見】Control netやdeforumと連携したsd-webui-AnimateDiffのアップデートを確認しよう【AIアニメーション】 動画生成AnimateDiff AnimateDiffは、以下をご覧ください。 PoseMy.Art Opening video を作成する。 PoseMy.Artサイトより、ダンスムービーを作成。  Windows 10 の標準機能で画面録画の動画とキャプチャを撮る方法「スクリーンショット」
Windows10/11の標準機能のスクリーンショットが強化され、簡単にパソコンの画面を動画で録画するこができま...
www.pasoble.jp 作成したダンスムービーは以下の通りです。 Taggerの設定 ダンス衣装プロンプトをTaggerで生成 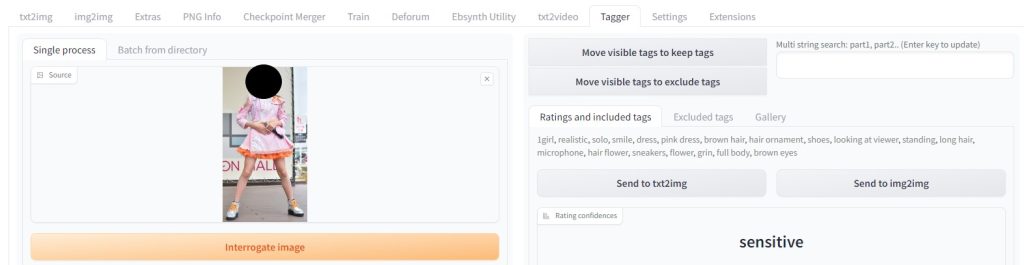 tagger:1girl, realistic, solo, smile, dress, pink dress, brown hair, hair ornament, shoes, looking at viewer, standing, long hair, microphone, hair flower, sneakers, flower, grin, full body, brown eyes
AnimateDiffの設定 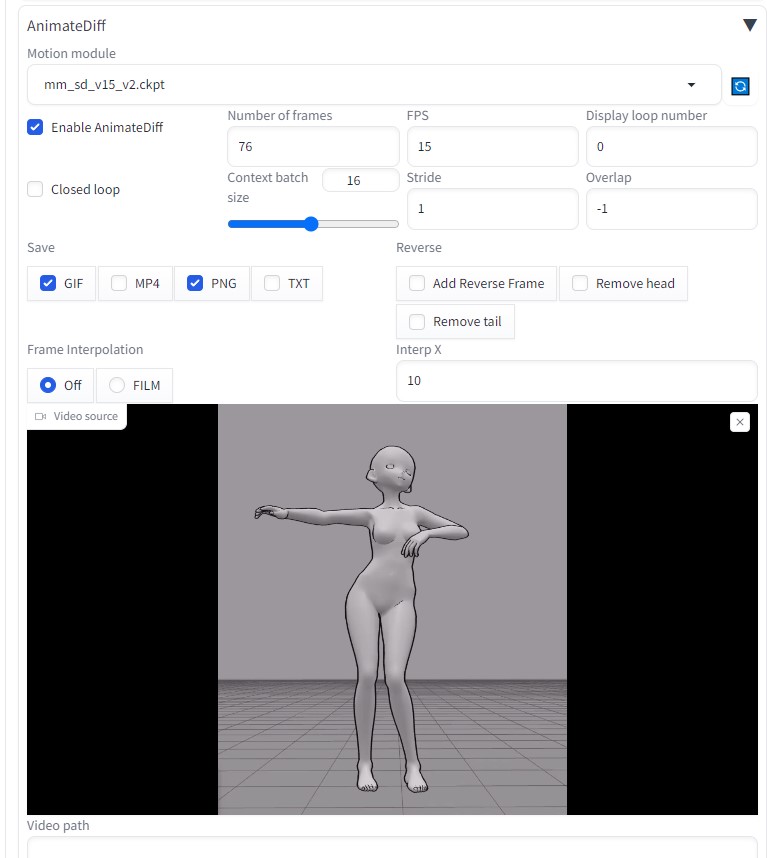 ControlNetにて、「OpenPose」と「IP-Adapter」を使用しました。
|
Fooocus SDXL画像生成 (2023-10-9 15:18:31)
はじめに 現在、Stable Diffusion でSDXL画像を生成している。 今回は、SDXLを手軽に扱える「 Fooocus 」を考察したい。
参考サイトSDXLを手軽に扱える「Fooocus」のインストール方法・使い方まとめ!簡単操作でハイクオリティな画像を生成しよう 
SDXLを手軽に扱える「Fooocus」のインストール方法・使い方まとめ!簡単操作でハイクオリティな画像を生成しよう
今回は新しく登場した画像生成ソフトに関する話題で Stable Diffusion
XLを簡単に扱える「Fooocus」の導入方法と使い方 を丁寧にご紹介するという内容になっています。 Stable Diffusion
XL(SDXL)が登 kurokumasoft.com Fooocusのインストールから簡単な使い方を紹介【SDXLを手軽に高速に使える!低スペックでも安心です】Stable Diffusion WebUIのインストール方法 
Fooocusのインストールから簡単な使い方を紹介【SDXLを手軽に高速に使える!低スペックでも安心です】Stable Diffusion
WebUIのインストール方法
Fooocusのインストールから簡単な使い方を解説していきます。新しいStable Diffusion
WebUIクライアントで動作の軽さや、設定が簡単な点が特徴となっています。Automatic1111でSDXLを動かせなかったPCでもFooocusを使用すれば動作させることが可能になるかもしれません。
itdtm.com 生成AIグラビアをグラビアカメラマンが作るとどうなる?第八回:シンプルで高機能なSDXL専用インターフェースFooocusとFooocus-MREの使いかた (西川和久) 
生成AIグラビアをグラビアカメラマンが作るとどうなる?第八回:シンプルで高機能なSDXL専用インターフェースFooocusとFooocus-MREの使いかた
(西川和久) | テクノエッジ TechnoEdge Stable
Diffusionを使う新たなインターフェース、Fooocusをご紹介したい。インストールはbat一発、起動/アップデートもbat一発、Modelも初期起動時に自動的にダウンロードと非常にシンプル。そしてなにより、出てくる絵が驚異的という優れたインターフェースなのだ。
www.techno-edge.net Fooocusのインストール方法圧縮ファイルをダウンロード GitHub - lllyasviel/Fooocus: Focus on prompting and generating Focus
on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub. github.com Click here to download から圧縮ファイルをダウンロード 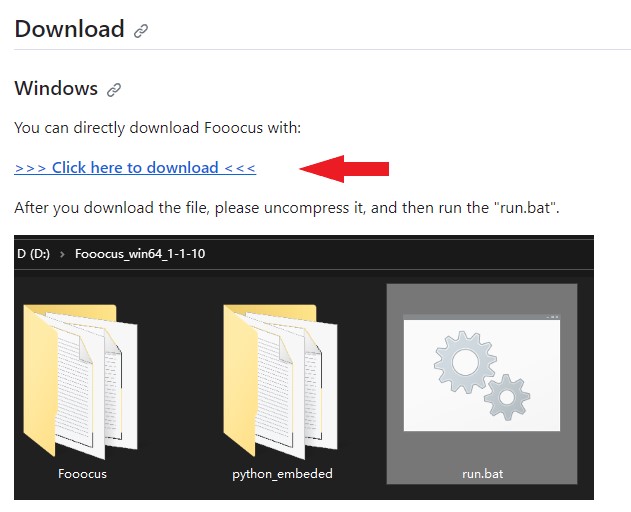 ダウンロードしたファイルを適当な場所に展開してください
2つのモデルファイルを事前にダウンロード
 stabilityai/stable-diffusion-xl-base-1.0 at main We’re on a journey to advance and democratize artificial intelligence through open source and open science. huggingface.co  stabilityai/stable-diffusion-xl-refiner-1.0 at main We’re on a journey to advance and democratize artificial intelligence through open source and open science. huggingface.co
最後に、Fooocus> run.bat を実行 AI画像生成人物 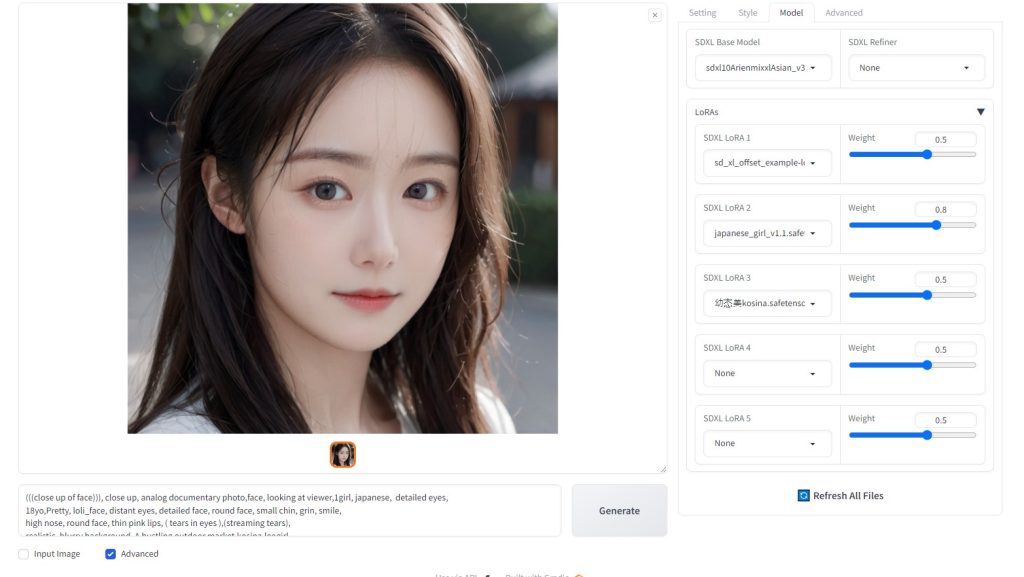 プロンプト: (((close up of face))), close up, analog documentary photo,face, looking at viewer,1girl, japanese, detailed eyes, Model:sdxl10ArienmixxlAsian_v30Pruned.safetensors Lora:japanese_girl_v1.1.safetensors, 幼?美kosina.safetensors  犬 プロンプト:1dog,realistic, blurry background,ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of field, film grain,  猫 プロンプト:1cat,realistic, blurry background,ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of field, film grain,  アンドロイド プロンプト:cyborg, realistic, blurry background,ultra high res,(realistic:1.4),deep shadow,(best quality, masterpiece),highly detailed, depth of field, film grain,  考察Stable Diffusion でSDXL画像を生成していた。 しかし、Fooocusを用いることによって、SDXL画像をお手軽に生成できることが分かった。 今後、SDXLを用いて、Lora学習をしてみたい。 Fooocus(SDXL)を用いることにより、飛躍的に画像生成が綺麗になったことが理解できた。
|
アニメーション動画『Deforum』考察 (Stable Diffusion V1.6) (2023-10-5 21:26:16)
はじめにStable Diffusion V1.6にバージョンアップしたため、AI動画を再確認している。 今回は、アニメーション動画『Deforum』を考察してみる 参考サイトアニメーション動画『Deforum』考察 (Stable Diffusion) ↑ 『 Deforum』の構築方法などは、こちらを参考にしてください↑
AI動画生成
考察Stable Diffusion V1.6にバージョンアップしたため、以前と比較すると格段に良くなっている。 画像1枚1枚も画質が向上しているし、何よりひとつ前の画像を継承してAI画像をそれぞれ生成しているように見える。
|

アニメーション生成 AnimateDiff (2023-10-4 23:52:04)
ポッドキャスト :
video/mp4
はじめに現在、AI画像からAI動画へと発展してきている。 Stable DiffusionでAI動画にチャレンジしてみる。 参考サイトStable Diffusionで動画生成AnimateDiff  Stable Diffusionで動画生成AnimateDiff 本記事ではStable
Diffusionで動画を生成する際に、最も有効な手法であるといっても過言ではないAnimateDiffの使い方について解説します。プロンプトから動画を生成する基本的な使い方からControlNetを使って実写動画か
kindanai.com AnimateDiffインストールExtensions> Load from> animatediffで検索 → 「Install」をクリックしてインストール ※インストール後、再起動してください AnimateDiffのモデル
 animatediff - Google ドライブ drive.google.com stable-diffusion-webui> extensions> sd-webui-animatediff> model に配置する AI動画生成設定例
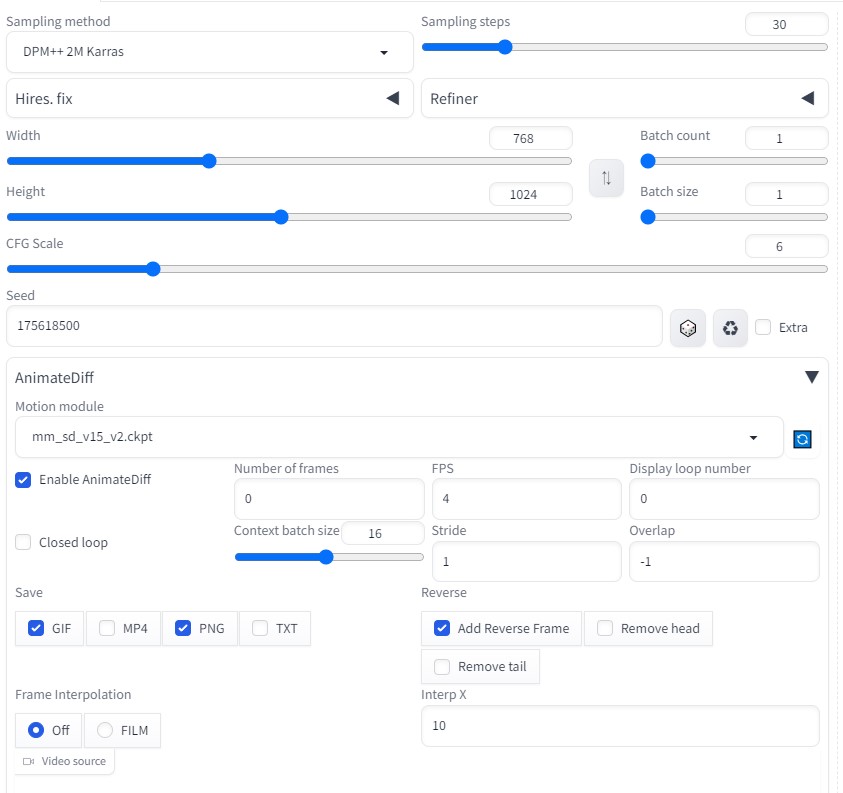 →Generate 生成結果考察Stable Diffusion V1.6 にアップデートし、モデルをmm_sd_v15_v2.ckptにしたことにより、かなり現実味のあるAI動画が完成した。 今回は2秒程度、AI動画を生成できた。 数分単位でAI動画ができるようになれば、ようやく実用性も出てくると思う。
|