ヘッドライン
| メイン | 簡易ヘッドライン |
簡易ヘッドライン

PC修理のわたなべ 最終更新日 2025-4-6 9:20:54
パソコン修理・パソコン販売・ホームページ制作など、パソコンのことなら、なんでもおまかせ!【茨城県坂東市・常総市・守谷市】
現在データベースには 488 件のデータが登録されています。
Stable Diffusionの再インストール(V1.6) (2023-10-4 17:29:48)
はじめに従来SDと新規SDXLが混合しているため、Loraを含めて、不具合が生じてきた。 そのため、最新Stable Diffusionを再インストールした。 参考サイト2023年最新!Stable Diffusionローカル環境構築インストール方法  2023年最新!Stable Diffusionローカル環境構築インストール方法
数ヶ月前の方法だと上手くインストールできないステーブルディフュージョンの最新インストール方法を紹介します!ローカル環境構築をすると無料・無制限で使えカスタマイズ性が高くなります。
piyo-piyo-piyo.com インストール手順Cドライブ直下にて、コマンド(cmd)入力
「stable-dffusion-webui」> 「webui-user.bat」を書き換え
「webui-user.bat」をダブルクリックし、実行! 作業画面に、VAEを表示する。 Settings> User interface> Quicksettings list> sd_vae を追加 以下のファイルを準備
AI画像生成プロンプト
ネガティブ
Stable Diffusion checkpoint:yumyumfusionXLBETA_v01Beta.safetensors SD VAE: sdxl_vae.safetensors Refiner: sd_xl_refiner_1.0.safetensors 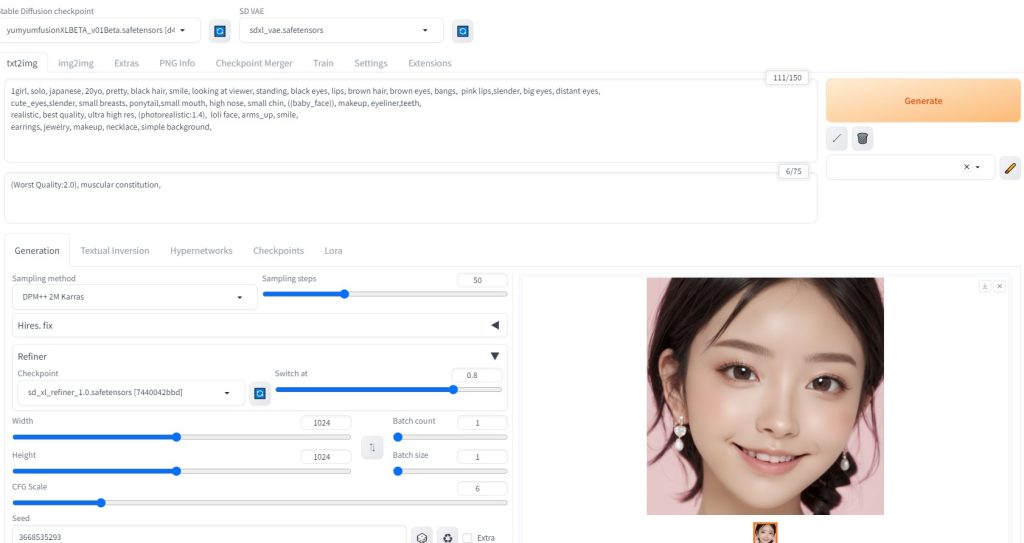
生成AI画像 考察Loraなしでも、かなりきれいな画像を生成できた。 1024*1024で生成したこともあり、きめ細やかな表現が実現されていると思う。 SDXLモデルを用いたLoraを、自分で学習できるようになれるように、これからもいろいろと勉強していきたい。 |
roop エラー修復(SD v1.6.0) (2023-9-20 11:41:24)
はじめにstable diffusionを更新し、version: v1.6.0にアップデートした。 それに伴い、roop for stable diffusionをインストールした。  【簡単便利】roop for stable
diffusionで顔の特徴を引き継ぐ! stable diffusion
は、モデルによって顔立ちの傾向はあるものの、毎回異なった顔が生成されてしまいます。これを解決するため、顔の特徴を引き継ぐControlNetやLoRAという方法が用いられるのですが、新たに
roop という resanaplaza.com しかしながら、roopタグが現れず、エラーメッセージが出てきた。 ValueError: This ORT build has ['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'] enabled. Since ORT 1.9, you are required to explicitly set the providers parameter when instantiating InferenceSession. For example, onnxruntime.InferenceSession(..., providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'], ...) 参考サイトNeed help with face swapping extensions 解決方法
SDを再度起動したところ、エラーがなくなった。 roopタグも表示され、ディープフェイクも正常に機能した。 |
SDXL 1.0 最新AI画像生成 (2023-8-29 18:22:16)
はじめにStable Diffusionに最新の画像生成SDXL 1.0が更新されたので試してみた。 参考サイト最新の画像生成AI「SDXL 1.0」実写系イラストのクオリティがすごい!!  最新の画像生成AI「SDXL 1.0」実写系イラストのクオリティがすごい!! (1/3) Stability AIが7月27日に公開した画像生成AI最新モデル「Stable Diffusion XL 1.0(SDXL
1.0)」レビュー。SDXLに対応したAUTOMATIC1111氏の「Stable Diffusion?web UI」で、環境を構築して試した。 ascii.jp モデルのインストールBASEモデルをダウンロード (「models\Stable-diffusion」にコピー)
 stabilityai/stable-diffusion-xl-base-1.0 at main We’re on a journey to advance and democratize artificial intelligence through open source and open science. huggingface.co Refinerモデルをダウンロード (「models\Stable-diffusion」にコピー)
 stabilityai/stable-diffusion-xl-refiner-1.0 at main We’re on a journey to advance and democratize artificial intelligence through open source and open science. huggingface.co Refinerモデルをダウンロード (「models\VAE」にコピー)
 madebyollin/sdxl-vae-fp16-fix at main We’re on a journey to advance
and democratize artificial intelligence through open source and open science. huggingface.co 画像生成・Stable Diffusion checkpoint
・SD VAE
・プロンプト (日本訳:横浜港に邪悪なモンスターが襲来してビームを吐いている。地球防衛軍の戦闘機が応戦している)
・Width
・Height
「Send to img2img」ボタンをクリックして画像を「img2img」に送る。 モデルを「stable-diffusion-xl-refiner-1.0」に変更、VAEはそのままでいい。
考察画像の分解能が大変よくなったような気がする。 手などの不具合も減少されたようである。 リアル系やLORAなども使用できるようになれば、よりいいかなと思う。
|
roop 1枚の画像から動画の顔スワップ構築 (2023-7-12 22:53:50)
 ポッドキャスト :
video/mp4
ポッドキャスト :
video/mp4
はじめに以下の動画を拝見した。 【StableDiffusion】ワンクリックで動画化!?AI画像から動画を作成する方法 roop構築以下のサイトをご覧ください GitHub - s0md3v/roop: one-click deepfake (face swap) one-click
deepfake (face swap). Contribute to s0md3v/roop development by creating an account on GitHub. github.com Installation 1. Installation one-click deepfake (face swap). Contribute to
s0md3v/roop development by creating an account on GitHub. github.com Cドライブ以下で、コマンドプロンプトを起動
Acceleration 2. Acceleration one-click deepfake (face swap). Contribute to
s0md3v/roop development by creating an account on GitHub. github.com すべてのファイルを入れると以下のようになります。 ※ファイル名:roop_setup.bat は、後ほど自作します 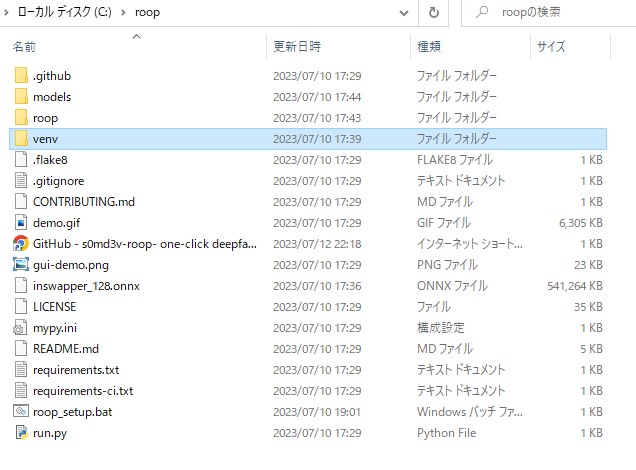 実践Select face: 対象となる画像  Select target: 対象とする動画
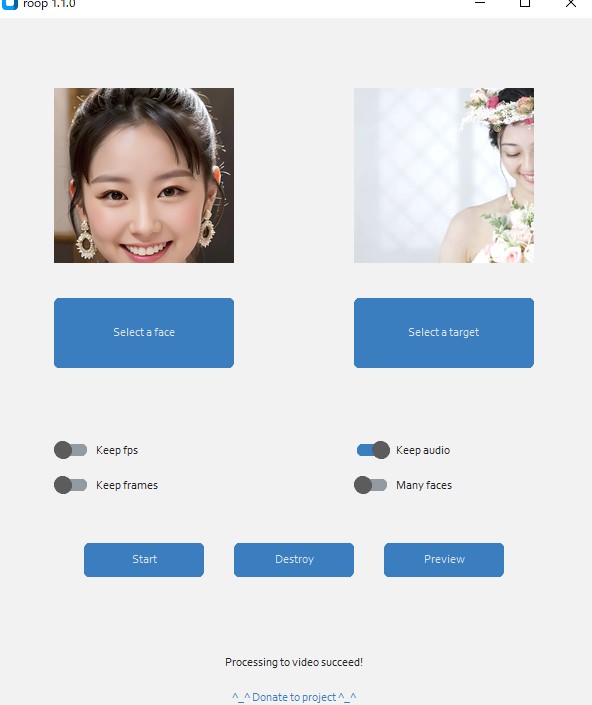 「Start」ボタンで生成を開始します。 結果 考察構築さえできれば、簡単に顔のスワップができるようになった。 venvを実行することが面倒だったので、バッチファイルを作成しました。 ※ファイル名:roop_setup.bat
「roop_setup.bat」を【roop】フォルダ下に置きました。 これで、バッチファイルを起動するだけで、「roop」アプリを起動できるようになりました。
|
sd-webui-faceswap 顔の入れ替え (2023-7-12 21:25:34)
はじめに超簡単!顔の入れ替えをstable diffusionで可能とyoutubeで発見
参考サイトsd-webui-faceswap のインストール【extensions】タブ→【Install From URL】→【URL for extension’s git repository】に以下のサイトからインストール
「inswapper_128.onnx」モデルのインストール inswapper_128.onnx ? deepinsight/inswapper at main (huggingface.co)
「\(stable diffusionフォルダ)\extensions\sd-webui-faceswap\models」へ、「inswapper_128.onnx」モデルをインストール Visual C++のダウンロード Visual Studio Tools のダウンロード – Windows、Mac、Linux 用の無料インストール (microsoft.com) 再起動します 実践
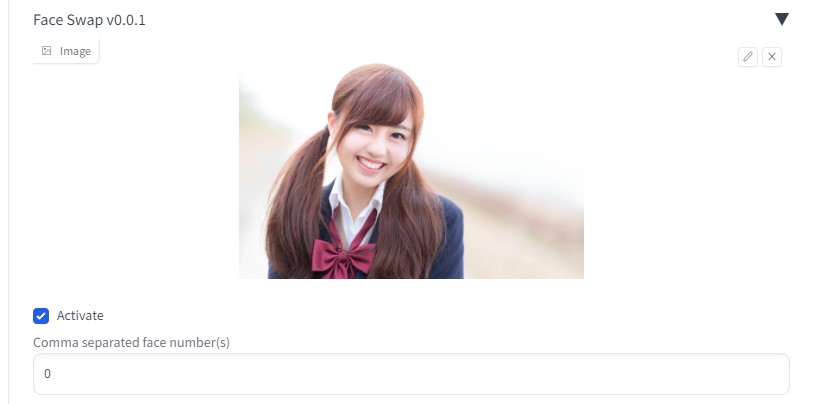 素材:https://www.pakutaso.com/  ぱくたそ -
登録不要で写真やAI画像素材を無料ダウンロード
「ぱくたそ」は、会員登録せずに今すぐダウンロードできる無料の写真素材・AI画像素材のフリー素材サイトです。一部を有料販売したり、枚数制限による課金など一切ありません。美しい日本の風景を中心に人物やテクスチャーなどの写真とAIで生成した背景画像の素材を配布しています。2023年7月11日現在、49,831枚の写真を掲載中...
www.pakutaso.com ●img2imgにて、実践 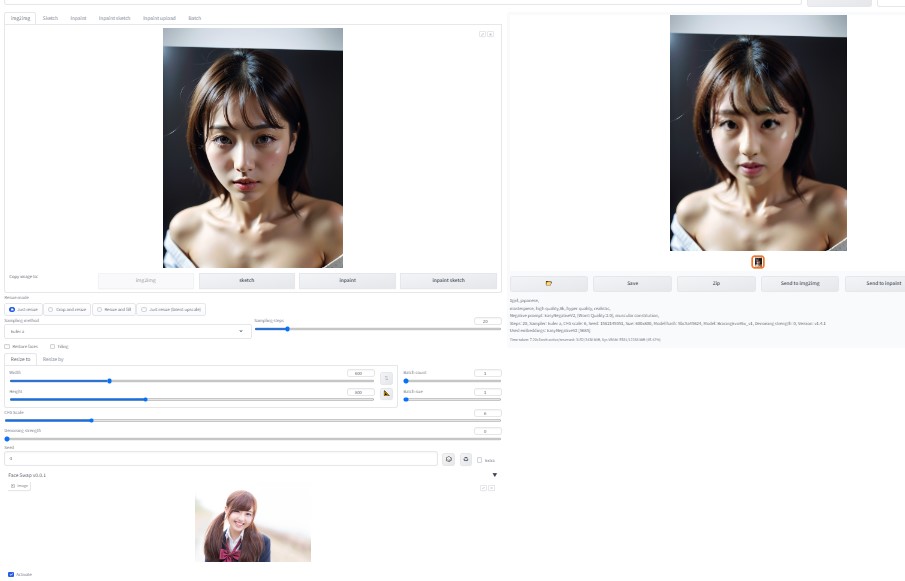
   考察超簡単に、顔のスワップができるようになった。 簡単ではあるが、変換後の顔画像の分解能が少し低いように感じる。 解像度を上げる方法があるかもしれません。 お遊びでスワップ画像を確認したい方におすすめします。 今回一番参考になったサイトは、以下の通りです。 GitHub – IntellectzProductions/sd-webui-faceswap: FaceSwap Extension – Automatic 1111
|
LeiaPix Converter 静止画からAI動画 (2023-7-5 20:50:49)
ポッドキャスト :
video/mp4
はじめにまたひとつ、静止画からAI動画を生成できるアプリをみつけた
参考サイト
生成過程【AI画像生成】  【公式サイト】 LeiaPix Converter | Depth Animations ※AI生成画像をアップロード後 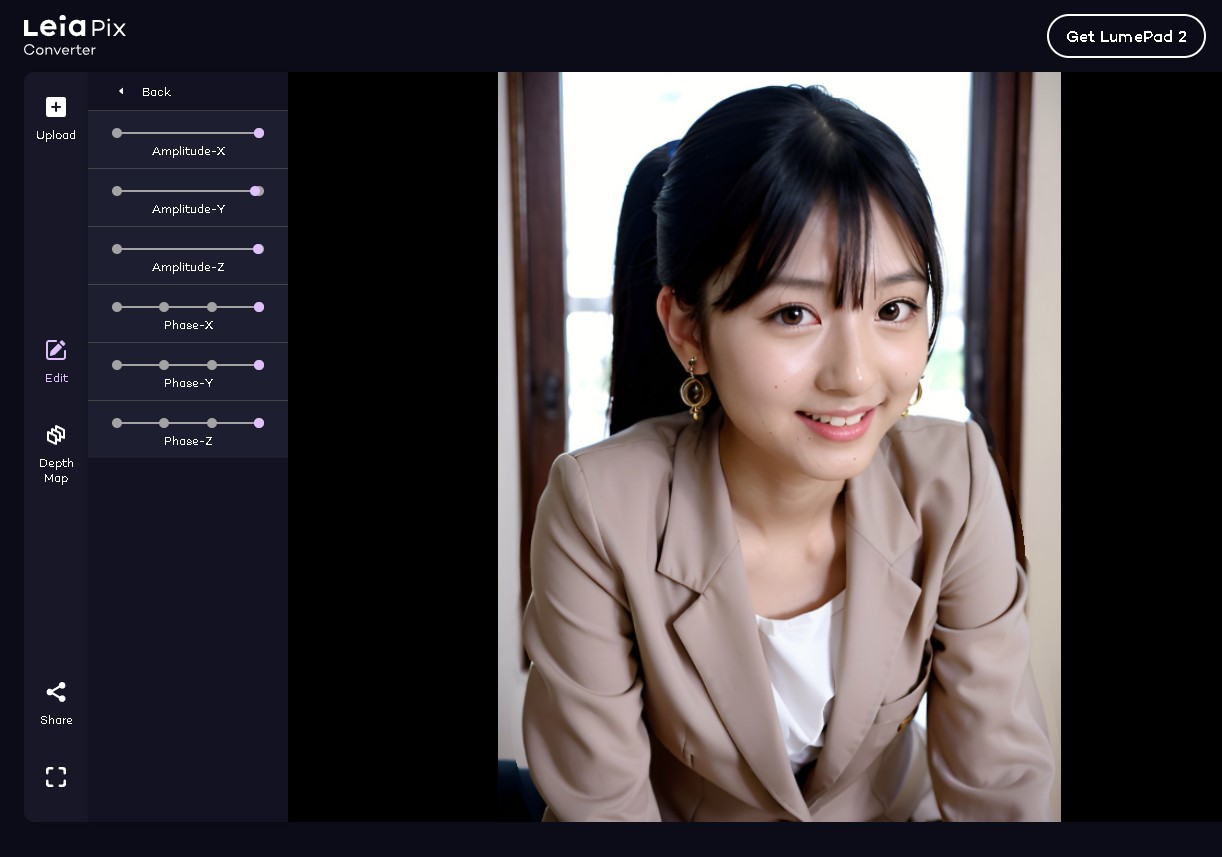 完成動画 考察1枚の画像から、ゆらぎのある動画を簡単に生成できた。 贅沢を言えば、音声を追加できるようになれば、いいかも。 |
SadTalker 画像に音声を合成 (2023-7-5 0:19:37)
ポッドキャスト :
video/mp4
はじめに音声に合わせて、画像の動画をつくりたいと思った。 【ツール】
参考サイトSadTalkerのインストールは、以下をご覧ください。 口パク(リップシンク)AI「SadTalker」をWebUI(1111)拡張機能として導入する方法 | 経済的生活日誌 (economylife.net) SadTalkerの使い方と魅力、画像と音声からアニメーションを作ろう! | 定年後のスローライフブログ (yanai-ke.com) SadTalkerの設定資料拡張機能URL
モデルの配置 stable-diffusion-webui/models/SadTalker 以下のサイトから、すべてのファイルをダウンロードし、上記フォルダ以下にコピーする。 sadtalker_checkpoints – Google ドライブ SadTalkerをつかってみたtxt2imgにて、画像を作成 【その1】  【その2】  SadTalkerに画像と音声を合成 【その1】 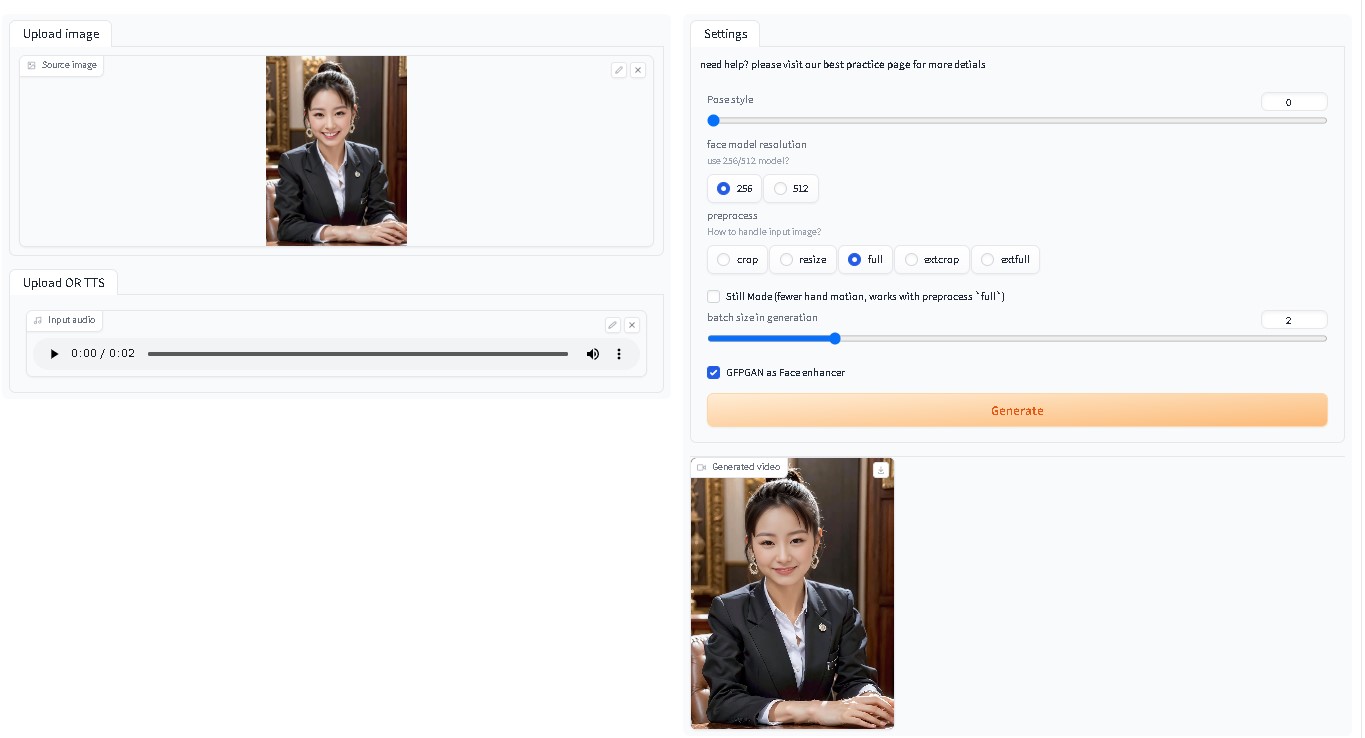 【その2】 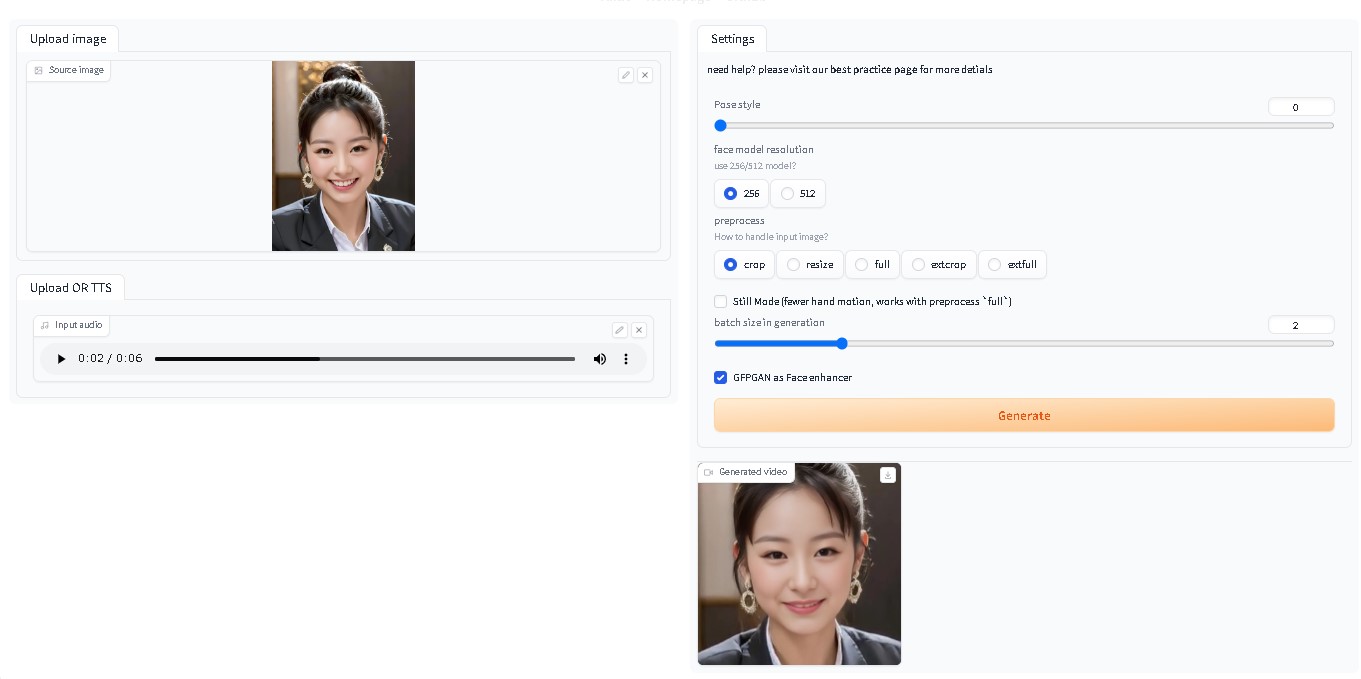 ビデオエディター(windows標準アプリ)にて、動画を結合 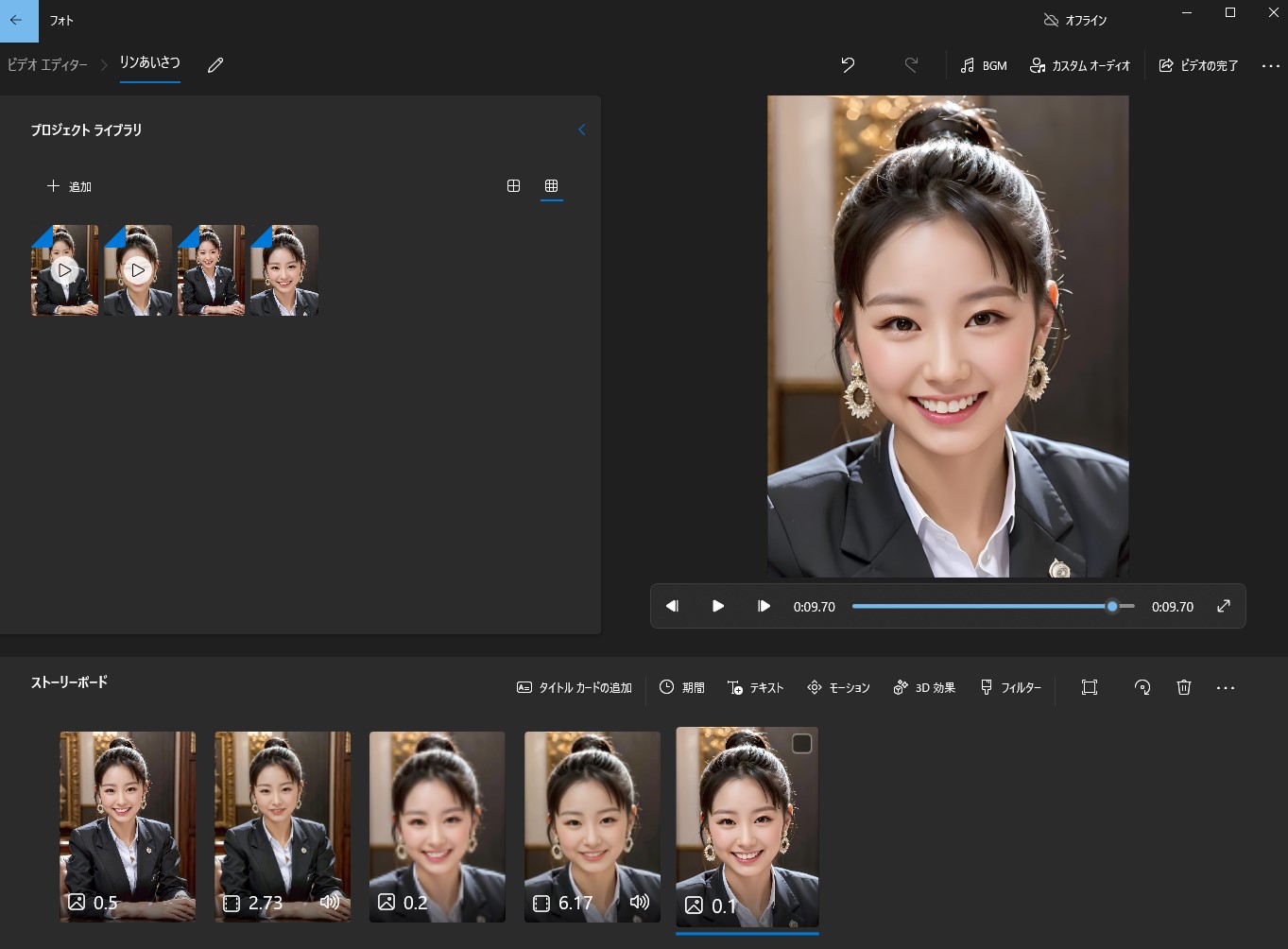 完成動画リンのあいさつ
考察1枚の画像から、音声動画ができるようになった。 Stable Diffusion の各動画ツールと違い、動画内の画質・人物・風景が相違なく動くのが、すごくよかった。
|
LoRA学習 福沢諭吉編 (2023-6-26 19:57:25)
はじめに1枚画像でLoRAを作成してみる。 【モデル】
 写真の調整写真の加工を簡単に施した。※手動修正
 白黒から高画質カラー写真へ
【参考ページ】  AI高画質化ツール(Real-ESRGAN)実施後  白黒画像・動画のカラー化(DeOldify)実施後  LoRAを作成してみる人物のみを切り抜く 【参考ページ】  イラスト切り抜き 作成 (Transparent-Background)  LoRA生成LoRA完成  LoRAで遊んでみたLoRAを使用して、画像を生成してみた 【作成例】
|








LoRA学習 坂本龍馬編 (2023-6-22 22:22:39)
はじめに1枚画像でLoRAを作成してみる。 【モデル】
 写真の調整写真の加工を簡単に施した。※手動修正
 白黒から高画質カラー写真へ
【参考ページ】 AI高画質化ツール(Real-ESRGAN)実施後  白黒画像・動画のカラー化(DeOldify)実施後  高画質なカラー写真が完成しました。 LoRAを作成してみる人物のみを切り抜く 【参考ページ】
イラスト切り抜き 作成 (Transparent-Background)  学習用素材に加工 【参考サイト】 (3/20更新)Kohya版LoRA学習環境 簡単スタンドアローンセットアップ(※bmaltais氏の『Kohya’s GUI』の導入)  (3/20更新)Kohya版LoRA学習環境 簡単スタンドアローンセットアップ(※bmaltais氏の『Kohya's
GUI』の導入)|niel 更新 6/17v21.7.8 ■はじめに AUTOMATIC1111
webuiのスタンドアローン化に引き続き、PythonやGiTをインストールしていなくても導入出来るKohya版LoRAの学習環境についてあれやこれやしてみました。ただ、今回はAUTOMATIC1111webui以上に技術者向けの...
note.com
 【ryoma01.txt】
【ryoma02.txt】
【ryoma03.txt】
kohya_ss_webuiでLoRA作成 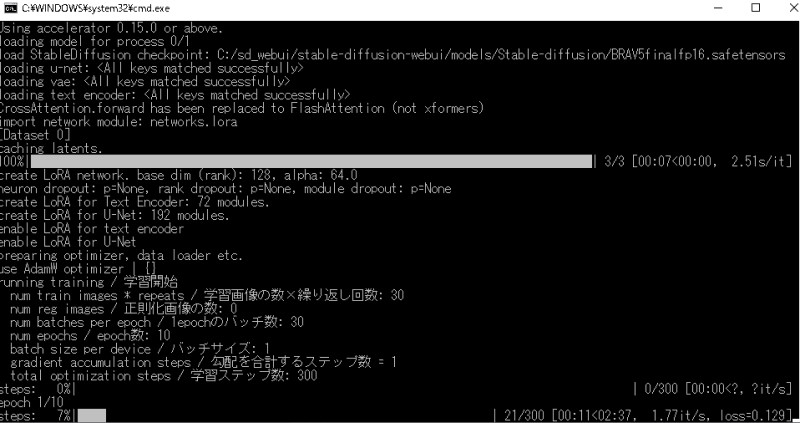 LoRA完成  LoRAで遊んでみたLoRAを使用して、画像を生成してみた 【作成例】 考察今回は、坂本龍馬でLoRA学習を実施し、AI画像を生成してみました。 1枚の画像から、立体感のある写真を生成することができました。 今回のSD WEBUIの設定画面を残しておきます。 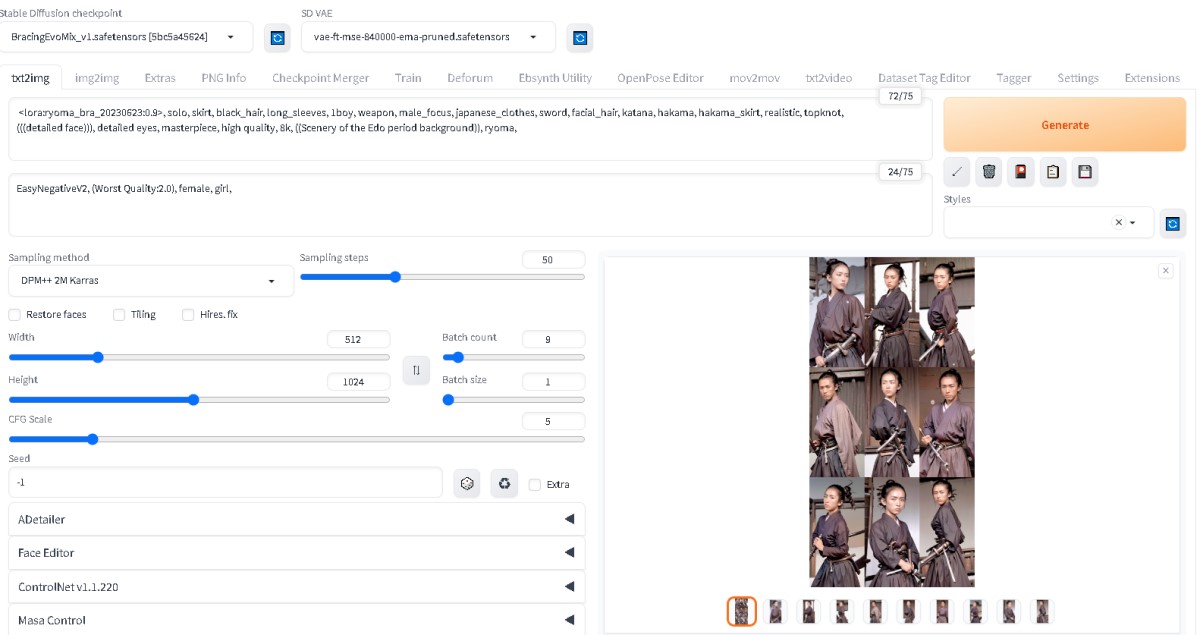 |





イラスト切り抜き マスク作成 (Transparent-Background) (2023-6-20 20:00:05)
はじめにStable DiffusionでLora作成のために、素材をマスキングしたいと思った。 【今回の学習】
参考サイト切り抜きや背景透過・学習素材集めのお供に最適!Transparent-Backgroundが超高性能なので使ってみよう!ほか拡張機能の紹介【Stable Diffusion】 インストール方法ダウンロードサイト plemeri/transparent-background GitHub - plemeri/transparent-background: This is a background removing tool powered by InSPyReNet (ACCV
2022) This is a background removing tool powered by InSPyReNet (ACCV 2022) - GitHub -
plemeri/transparent-background: This is a background removing tool powered by In... github.com インストール方法 コマンドプロンプトで以下の命令をする
 以上で終了です!※簡単ですね 使用方法練習用として、Cドライプに「 images 」フォルダを作成します。 その下位ファルダに、「 sozai 」と「 output 」を作成します。 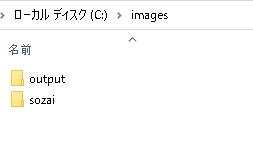 「 sozai 」フォルダに、「 sample01.jpg 」を追加しました。  「 sozai 」フォルダにて、コマンドプロンプトを起動させます。
 今回は、「 sozai 」フォルダに切り抜かれた画像「 sample01_rgba.png 」が生成されています。  比較【元データ画像】  【切り抜かれた画像】  髪の毛などを確認すると、他のアプリと比較しても断然良い生成結果になりました。 応用マスクを作りたい場合
今回は、「 sozai 」フォルダにマスク画像「 sample01_map.png 」が生成されています。  グリーン背景を作りたい場合
ホワイト背景を作りたい場合
目的の画像背景を作りたい場合 「 sozai 」フォルダに、「 back01.jpg 」を追加しました。
【命令文】  【作成結果】 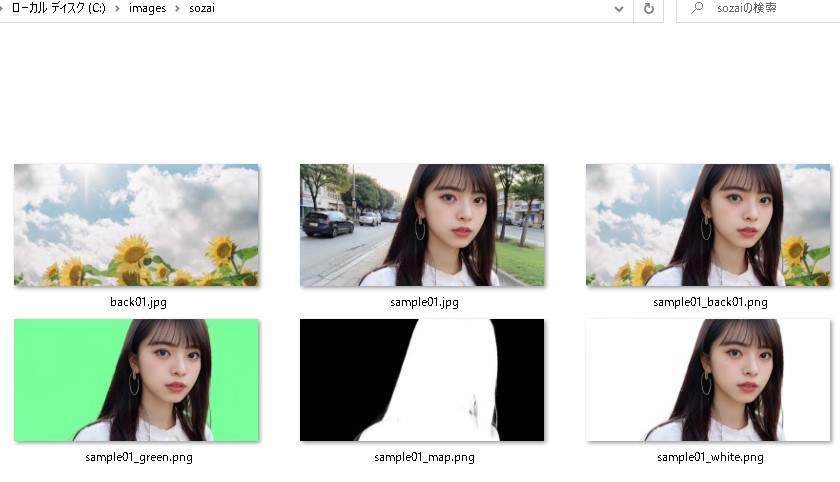 【背景画像を結合した結果】  バッチファイル作成フォルダ内のファイルを丸ごと変換するバッチファイルを作成します。 「 sozai 」フォルダに、「 sample01.jpg ?」を追加しました。  バッチファイルの作成「 setup.bat 」
 バッチファイル「 setup.bat 」をダブルクリックすると、「 output 」フォルダ内に、人物が切り抜かれた白い背景画像が生成されています。 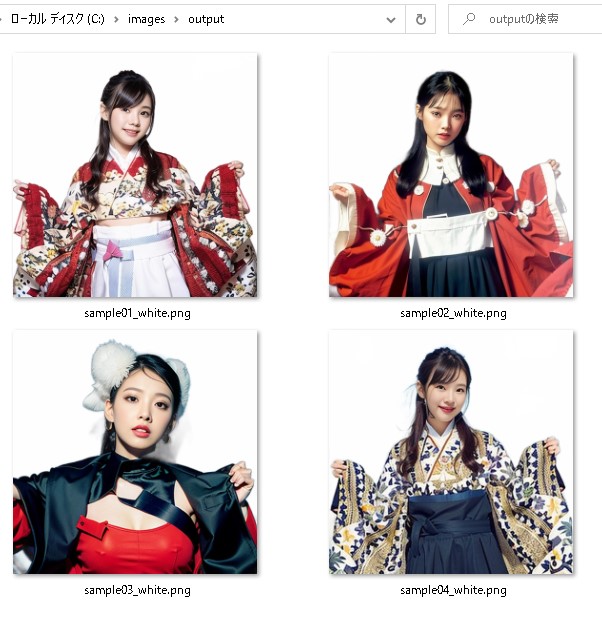 結論今まで手作業が多かった切り抜き画像がワンクリックで作成できるようになった。 Lora学習でも有益な活用が出来そうである。 |