ホーム
>>
ヘッドライン
>>
メイン
ホーム
>>
ヘッドライン
>>
メイン
ヘッドライン
坂東市にかかわる最新ニュースをご紹介
| メイン | 簡易ヘッドライン |
 |



|
現在データベースには 7905 件のデータが登録されています。
|
65000円 →? 58000 円 【美品】東芝 dynabook T75/EB 15.6型 (Core i7/SSD512GB/8GB/Webカメラ/Win11/Office)   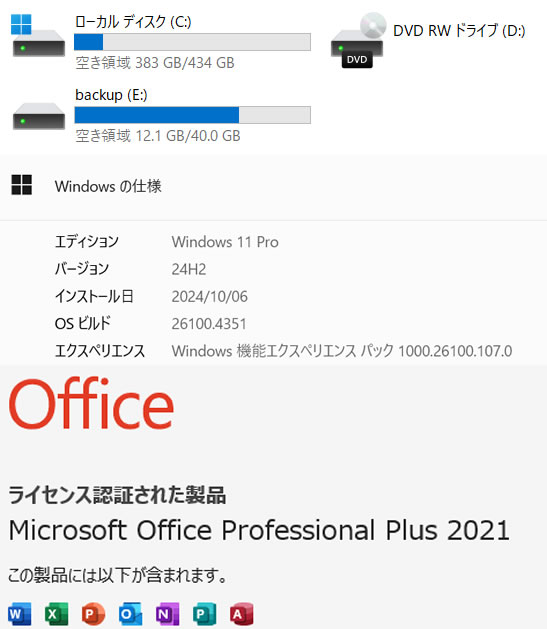 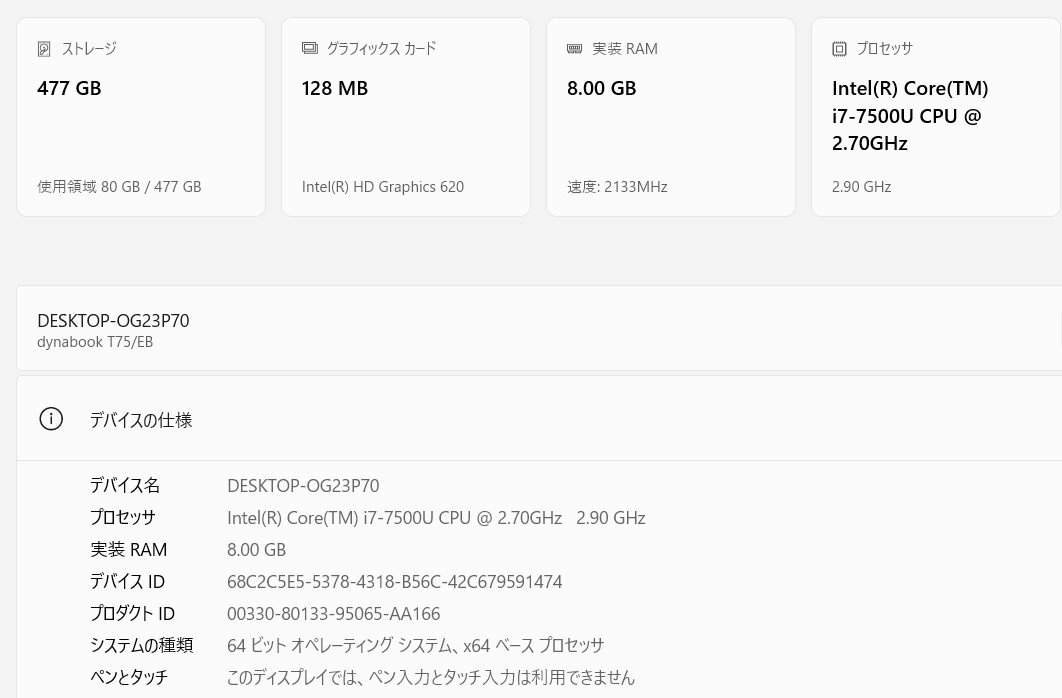
商品メーカー:東芝 付属品:ACアダプター
お問合せ※商品タイトルを「題名」にコピーして送信してください [contact-form-7]
|
|
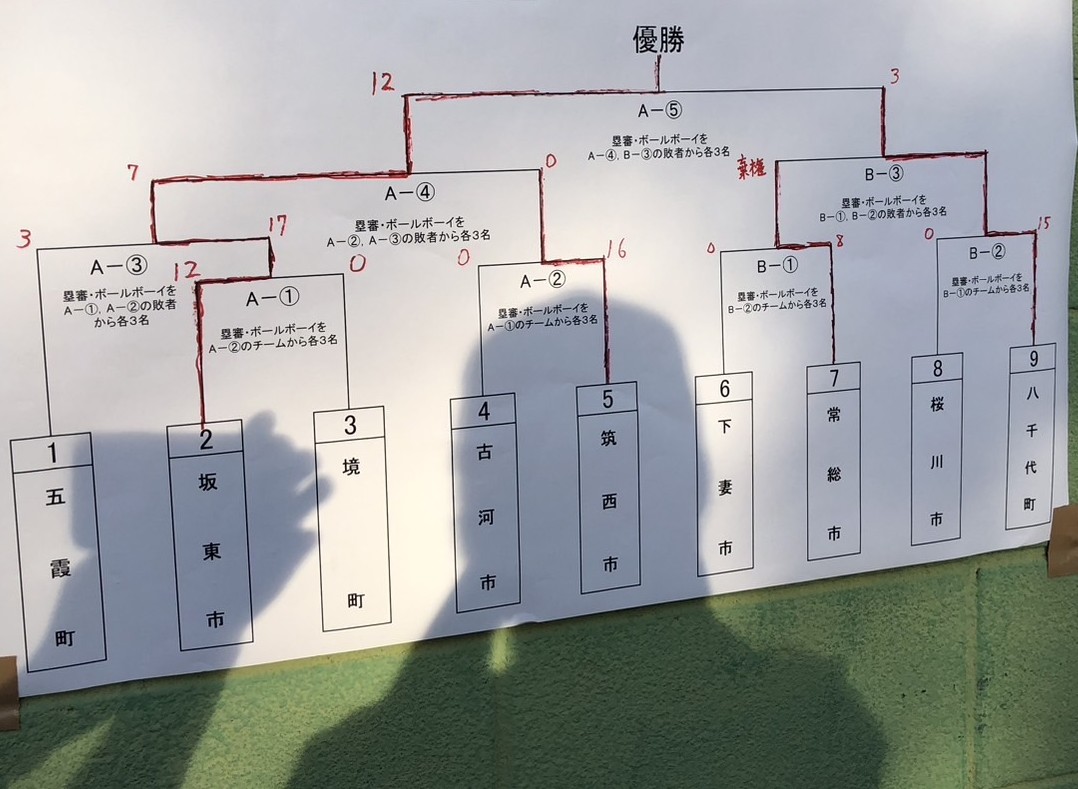
令和7年6月21日(土)に開催された「第55回県西地区商工会青年部野球大会」において当商工会青年部が酷暑の中4試合を勝ち抜き堂々の二連覇を達成いたしました。 前年度同大会優勝、茨城県大会ベスト4にもかかわらず抽選でノーシードから始まりました。 1回戦の相手は境町商工会青年部。 将門打線が相手ピッチャーを打ち崩すと共にエース兼主将兼青年部長の片倉慎吾が完封で勢いをつけました。 2回戦は五霞町商工会青年部。初回の攻撃だけで40分以上という将門打線爆発の猛攻撃。投手陣も井上?金久保ー木村ー中山智博ー片倉の豪華リレーで3回コールド勝ち。 3回戦は筑西市商工会青年部。前試合本塁打続出の猛打戦、投手陣も本格派の2枚看板を誇る筑西市商工会青年部でしたが、初回に坂東市商工会の将門打線爆発。井上、中山奎太の本塁打で着実に点を重ねる。守りも井上、片倉の完封リレー、好守備も続出し勝利を手にしました。 決勝は開催地の八千代町商工会。好投手を要する八千代町商工会青年部でしたが、初回から将門打線爆発。相手エラーにも助けられ初回に5点先取。 途中4試合目の疲労から来る失策も出て追撃をされ、手に汗握る一戦となりましたが、何とか逃げ切り勝利を収めました。 ベンチ入り全員が活躍しての優勝おめでとうございます。 10月の県大会に向けて頑張ってください!
|
|
6月7日 坂東市出身 高校3年生の中村唯人さんキャンペーン午後1時と3時の2回行いました。さすが地元とあって大勢の方々が応援に来てくださいました。唯人さんはテレビ番組カラオケバトルに出演し、作曲家の田尾先生に指導して頂いたそうです。当店がキャンペーンを始まって以来の満席!!是非皆さん応援しましょう!!9月28日(日)には当店主催の「岩崎電気うたまつり」に出演して頂きます。 クラウン 楠木康平 コロムビア 望月琉叶 テイチク 永井みゆき キング 井上由美子 徳間ジャパン 中村唯人チケットは岩崎電気 0297?35?4514 6月18日より販売します。 詳しくは当店のイベント情報を...
|
|
第七回 岩崎電気うたまつり今年も9月28日(日)坂東市民音楽ホール(ベルフォーレ)にて行います。開場 12時30分
/
開演 13時00分チケットの販売は6月18日より販売予定です。入場料 全席指定 3,900円シングルCD1枚付き(プレゼント商品のため、シングルCDは選べません。)チケットの販売は岩崎電気のみです。お問い合わせ…岩崎電気 茨城県坂東市岩井4276-13 電話:0297-35-4514出演者は クラウン 楠木康平 徳間ジャパン 中村唯人 テイチクレコード 永井みゆき キングレコード 井上由美子 コロムビア 望...
|
Rope-NextYouTube GitHub GitHub - Alucard24/Rope: GUI-focused roopGUI-focused roop. Contribute to Alucard24/Rope development by creating an account on GitHub.
インストールCドライブに「DeepFake_next」フォルダを作成 
「DeepFake_next」フォルダに移動 コマンドプロンプトで「DeepFake_next」フォルダに仮想環境を作成
仮想環境をアクティベート
GitHubからクローン
「Rope」フォルダに移動
必要ライブラリをインストール
アップデート
Rope-Next UI起動

ディープフェイクRope【複数顔の入替え】参考サイト Ropeによる高画質ディープフェイク動画の作成 ディープフェイクが簡単に!「Rope」 顔の入れ替えDeep Fake が圧倒的に簡単なRope Opal 事前準備 Python 3.10必… 
|
|
「職場における熱中症対策」 茨城労働局内の職場で令和6年に熱中症により死傷(休業4日以上)した労働者は44人。 うち3人が死亡!茨城県内の職場では4年連続の死亡者が出ています。 集計を始めた平成20年以降で最多となりました。 令和7年6月1日に改正労働安全衛生規則が施行され、暑さ指数28以上、または気温31度以上の環境下で連続1時間以上、または1日4時間を超える作業を対象に「体制整備」「手順作成」「関係者への周知」が義務付けられます。 |


|
Sustaina Blox にて、コスプレ撮影会が行われました。2025年5月11日(日) Sustaina Blox 吉田運送茨城県坂東市半谷224-15
https://www.yoshiun.com
|