ヘッドライン
| メイン | 簡易ヘッドライン |
簡易ヘッドライン

PC修理のわたなべ 最終更新日 2025-4-6 9:20:54
パソコン修理・パソコン販売・ホームページ制作など、パソコンのことなら、なんでもおまかせ!【茨城県坂東市・常総市・守谷市】
現在データベースには 488 件のデータが登録されています。
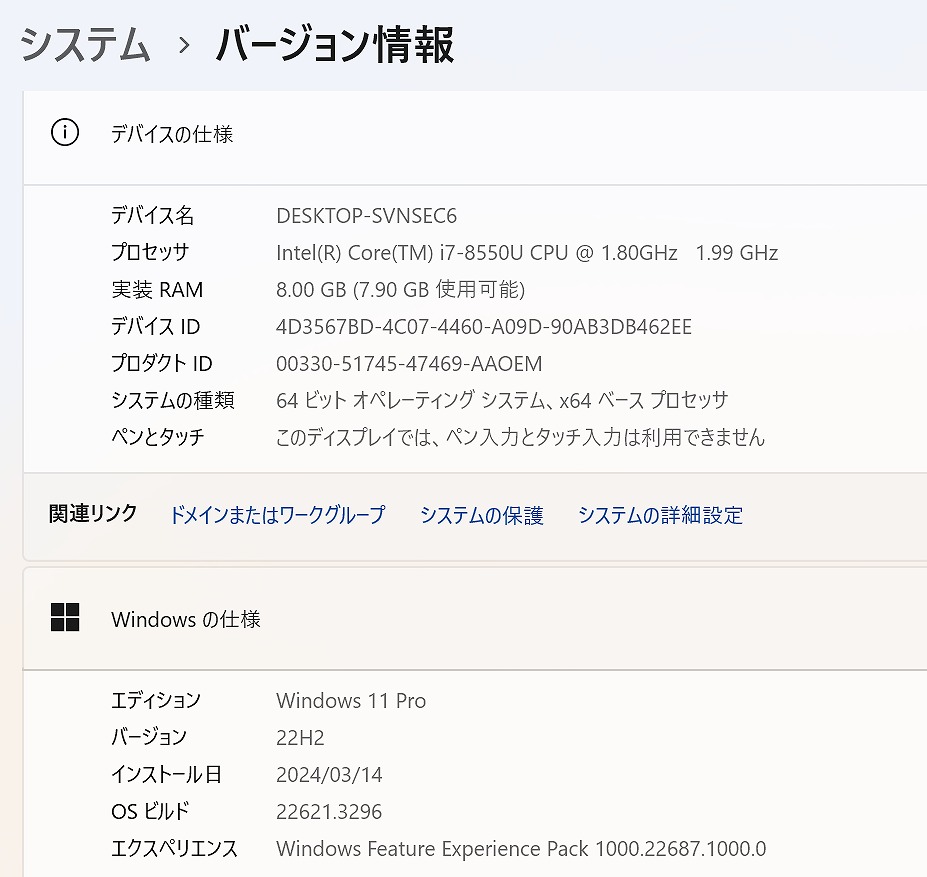
【美品】VAIO VJPG11C11N 13.3型 (Core i7/M.2 SSD500GB(新品)/8GB/Webカメラ/Win11/Office) (2024-3-17 22:22:17)
|
【爆速SSD☆Win11 Pro】 VAIO VJPG11C11N ☆新品M.2 SSD500GB!/Core i7 -8550U /メモリ8GB/Office 2021参考資料ある学校に配布されたパソコン販売パンフレット 
ギャラリー
説明 Intel Core i7プロセッサー&メモリ8GB搭載で、動作も快適♪ 
料金税込? 74800円 ?(税抜68000円)お問い合わせ※商品タイトルを「題名」にコピーして送信してください [contact-form-7] |






白黒写真をカラー化 2024/03/17 (2024-3-17 18:05:38)
はじめに知人からLINEにてモノクロ写真が送られてきた。  画素数が低いので、カラー化するためには少し難しいと思われた。 しかし、いざAI写真加工をしてみると意外とよい結果になったのでご報告させていただく。 ギャラリー
考察低分解能でもある程度、AI写真加工は上手く処理されると思われる。 また、ブレている写真でピンボケしている写真でもある程度シャープな写真に加工してくれることが分かった。

|




Hitpaw Photo AI モデル考察 【AI写真加工】 (2024-3-8 21:42:44)
はじめにHitPaw Photo AI のAI写真加工について考察してみた。  HitPaw Photo AI サイト: https://www.hitpaw.jp/photo-enhancer.html [公式]HitPaw Photo
AI?ワンクリックで写真や画像の高画質化を実現 HitPaw Photo
AIは、より良い画像高画質化スールの一つです。その強力なAI機能により、画像の拡大や高画質化、ノイズの除去、色の補正、白黒画像のカラー化などが簡単に行えます。さらに、古い写真の復元も可能です。高画質な画像を手軽に作成したい方にはおすすめの選択肢です。
www.hitpaw.jp 参考サイト【HitPaw Photo AI】使い方。画像サイズの倍率・出力先などの設定を解説。  【HitPaw Photo AI】使い方。画像サイズの倍率・出力先などの設定を解説。 |
なぎのブログとYouTube/AI&web3.0 HitPaw Photo Enhancerの新しいバージョンHitPaw
Photo
AIの使い方を解説していきます。画像をアップスケールする時の画像サイズの倍率や、出力先などの設定も解説します。処理速度を速める機能や、HD画質が最大4Kサイズまできれいにすることができます
nagi.blog Hitpaw Photo AI モデルの比較元画像 
フェースモデル:顔のディテールを強化するための特化モデル柔らかい 
柔らかいV2 
鋭い 
【マルチ】カラー化モデル 
ジェネラルモデル:一般的な画像向けの高画質化モデル
デノイズモデル:ノイズを除去し、クリアな画像を得るためのモデル
【マルチ】モデルによる処理結果の最適化 
カラー化モデル:色の再現性を高めるためのモデル
色補正:露出や彩色不足の画像を補修
【マルチ】デノイズモデル 
スクラッチリペア:傷のある写真を修復
【マルチ】フェースモデル 
ナイトモード:暗い場所で撮影された写真を明るくする
元画像とAI加工後の画像比較元画像とAI加工後の比較(スライダーを左右に動かしてください) 

無料体験ありHitPaw Photo AI サイト: https://www.hitpaw.jp/photo-enhancer.html [公式]HitPaw Photo
AI?ワンクリックで写真や画像の高画質化を実現 HitPaw Photo
AIは、より良い画像高画質化スールの一つです。その強力なAI機能により、画像の拡大や高画質化、ノイズの除去、色の補正、白黒画像のカラー化などが簡単に行えます。さらに、古い写真の復元も可能です。高画質な画像を手軽に作成したい方にはおすすめの選択肢です。
www.hitpaw.jp
|
【中古】パソコン用メモリ 販売(在庫品限り) (2024-3-8 17:37:50)
ノートパソコン用2個セット
(税込み価格) 単品
(税込み価格) デスクトップ用2個セット
(税込み価格) 単品
(税込み価格)
|




























SSD搭載パソコンの起動が遅くなった際の対処方法 (2024-3-4 20:35:28)
はじめにSSD搭載のパソコンが急に遅くなったと持参された。 【DELL XPS】  解決方法メモリを他のスロットに差し替えることにより、起動が通常通り高速になった。 差していたメモリスロットに不具合が生じたように考えられる。 
|
ノートパソコン用ACアダプタ(電源) (2024-3-4 17:41:44)
ACアダプタ(在庫品)※画像をクリックすると拡大します
メーカー
中古品となります。 電源ケーブルをお探しの方は、お気軽にご相談ください。 料金税込 2800円 |

















白黒写真をカラー化 2024/03/03 (2024-3-3 22:49:18)
はじめに古い写真をお持ちの方に多数の写真をお借りしました。 大正時代から昭和中期までの白黒写真をAI画像加工を利用してカラー化してみた。 ギャラリー
撮影場所
|






















【中古】冬のソナタ(DVD BOX、CD2枚、クリアファイルなど) (2024-3-2 17:31:12)
ギャラリー
内容知人からの依頼となります。 コレクションで集めていたそうです。 私見となりますが、すべて大切に保管していたように拝見できます。 韓国語の学習にいかがでしょうか? 話のネタとして、おばあちゃん・お母さんなどにも、お声掛けいただけると有難いです。 DVD BOX 冬のソナタ DVD-BOX vol.1(DVD 3枚組) : 定価14400円
CD(ソナタ) 冬の恋歌(ソナタ) サウンドトラック (国内盤): 定価2500円 CD(オルゴール) 冬のソナタ オルゴール・サウンドコレクション: 定価2200円 クリアファイル ペ・ヨンジュン 2枚 合計 38300円 となります販売価格税込 13200円 (税抜12000円) |










モノクロからカラー化『DeOldify』(Stable Diffusion) (2024-2-25 19:31:19)
はじめに昔の写真(モノクロ写真)を綺麗にしてほしいと依頼があった。  まず、写真を手元にあるドローソフト(Adobe Fireworks)で調整した。  次にモノクロからカラー化を実施。 以前、DeOldify単体で活用していたが、Stable Diffusionの拡張機能でインストールできることが分かった。 参考サイトStable Diffusionでモノクロ写真・動画をカラー化できる拡張機能『DeOldify』の使い方!  Stable Diffusionでモノクロ写真をカラー化できる拡張機能『DeOldify』の使い方!
白黒の写真や動画を簡単にカラー化する方法が知りたいと感じることはないでしょうか?この記事では、Stable
Diffusionを使って白黒の写真や動画をカラー化できる拡張機能「DeOldify」について解説しています。ぜひご覧ください!
romptn.com モノクロームな思い出を色鮮やかにするDeOldifyを使ってみた インストール方法
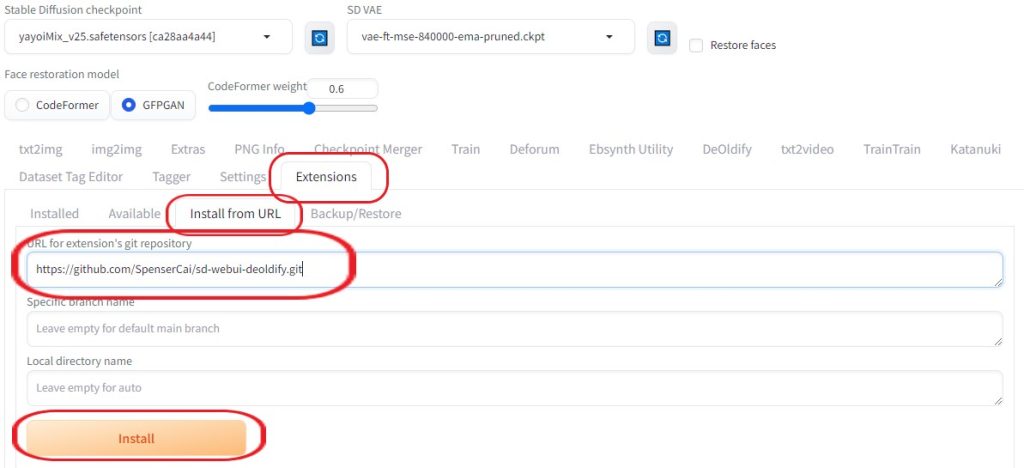 「webui-user.bat」の「COMMANDLINE_ARGS」に「 –disable-safe-unpickle 」を追記
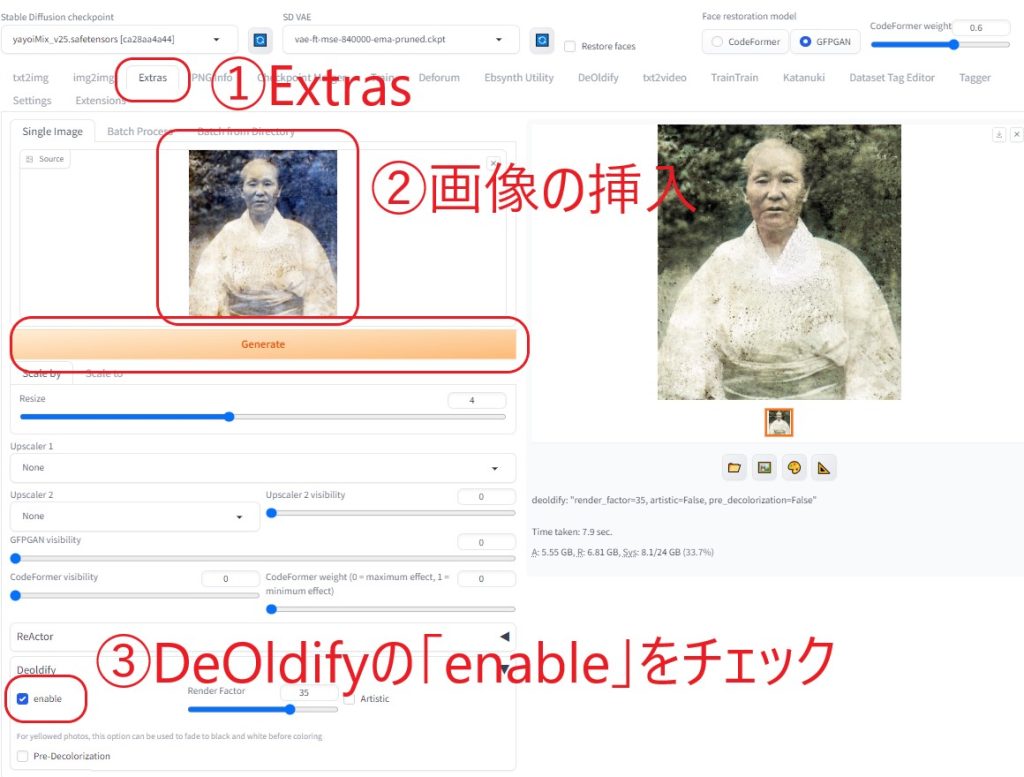
→ 再起動 「DeOldify」の使い方
 画像の調整「img2img」などで、少しだけAI加工する。 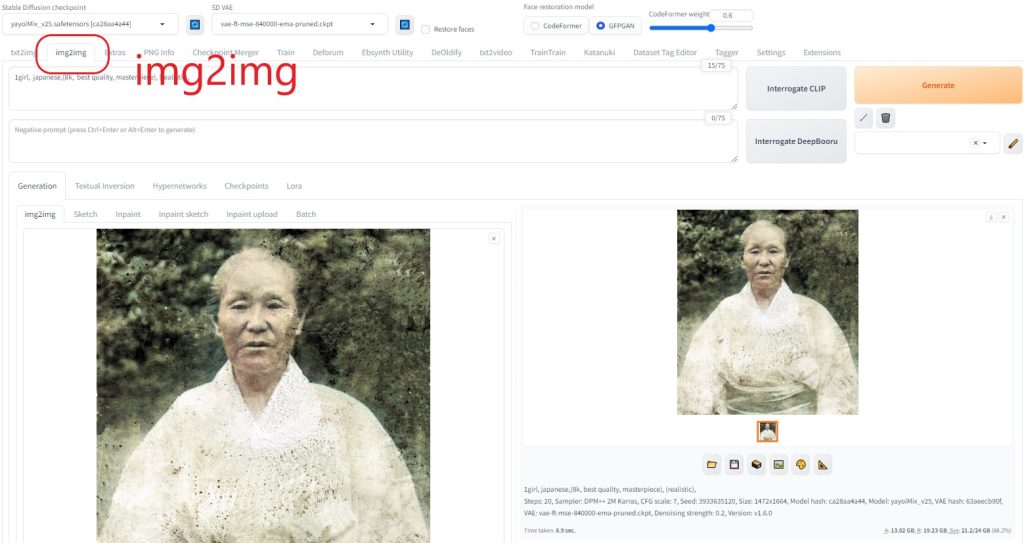 画像拡大Real-ESRGANにて、画像拡大した
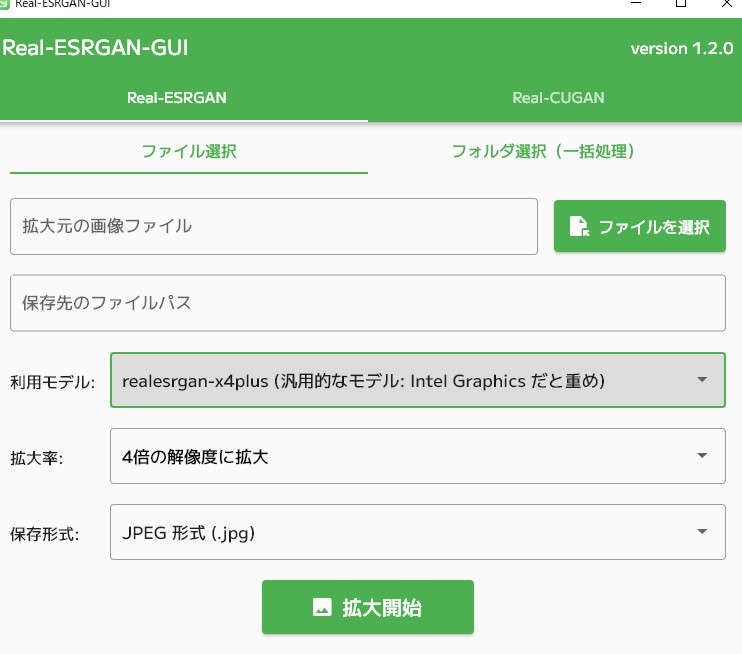 詳細は、以下を参考にしてください  CUGANも使える簡単アプコンGUIソフト「Real-ESRGAN-GUI」
今回は簡単に画像のアップコンバートができるソフト、「Real-ESRGAN-GUI」を紹介します。
以前Cupscaleというソフトを紹介していましたが、今回はよりお手軽に試す事ができるのでおすすめです。
Cupscaleとは違いRealC golabo.net 完成モノクロ写真をカラー化にすることができた。 また、分解能も拡大することもできた。 
考察AI画像生成のStable Diffusionを途中で加えることにより、カラー化する際、馴染みやすいように感じた。 やりすぎると顔が違う人に変わってしまうので、少しだけ活用するとよいと思います。
|
HDDをSSDに換装すれば、高速化で快適! (2024-2-23 19:08:34)
パソコン修理のパンフレット制作HDDをSSDに換装すれば、高速化で快適生活ができるようなパンフレットを制作しました  【 PDFファイル 】 SSD換装実例
dynabook AZ25 のHDDをSSDに交換 ・起動が10秒程度 ・シャットダウンが5秒程度
HDDからSSD換装サービス詳細は、以下のサイトをご覧ください |